あとがきが長すぎて、実はこっちが記事の本体という可能性が…w
SSHの穴をあけるのは危険か?と思ったが組み込みのSSHであればgitユーザーが出来ること以外できないだろうし、任意のコマンドが実行されたところで、精々リポジトリの全消し以上のリスクはなさそうなので開けることにした。理由としてはHTTPはパフォーマンスが悪いらしいからだ。
構築していて思ったがForgejoのマニュアルは親切で比較的解り易く、構築が楽だったのが良かった。
積極的に使い始めたのはUbuntuのadiaryをlibfcgi-perlで動かす方法が初めてだが、unixsocketはTCP通信をしないのでポート管理が不要になるのが利点なのと、TCPのオーバーヘッドがない分処理が速いというのをどっかで見たので、使うことにした。
内部通信のポートが被らないように管理するのは地味に大変なのでアプリケーション間の通信は極力unixsocketに倒したいなと思った。
最大の理由は、ここ数年でGitHubやnpm周辺のサプライチェーンリスクを強く意識せざるを得なくなったからだ。
例えばSecrets漏れなどの事故はここ数年で非常に聞くようになったし、npmjsからGitHubのToken奪取などの問題もあったと思う。
そしてその関係でセキュリティが面倒なことになり、GitHub Actionsからnpm publish出来なくなってたのを対応したみたいなことをする羽目になったこともあり、非常に煩わしさを感じていた。
Value-DomainでcertbotのDNS Challengeをやるスクリプトを書き直した理由の一つも、npmjsから手を引きたい思いが実はあり、そもそも別にリポジトリから拾えばいいじゃんと思い、パッケージ化しなかったというのもある。だって別にPerlでもnpmレジストリに入れることはできるからね。
そして昨日npmjsのアカウントを消そうと思い立ちログインしようとしたらロックアウトされてしまった。私はホビープログラマとしてやっているだけなので、こういった変化についていくのに疲れてしまった。
例えば最近GitHub離れが進んでいることも理由の一つだ。
理由にはいろいろあると思う、例えばここ最近GitHubは不安定で、GitHub Actionsが失敗する、Webページが開けない、APIがダウンしているのは最早日常といってもいいだろう。少なくとも私はそう思っている。
他にもCopilotなどのAI化の推進や、UXの悪いPR、行儀の悪いソフトウェアの排除もある。
CopilotなどのAI化の推進についてはGitHubのWebページ上でコミットを打つと解るのだが、LLMによって勝手にコミットメッセージが補完される。あのメッセージに意図などなく、変更内容を文字列にしただけだ。これを避けるためにはAIが書き切るより早く書き起こしてコミットするか、或いは書き終わるのを待って上書きするか、何も考えず即座にコミットボタンを押しUpdate hoge.mdのようなメッセージにするかしかない。個人的にはこれが非常に煩わしく、避けたいと思っている。
そして、もしこれを回避する設定があるとしてもGitHubの設定は既に増えすぎており、もう探す気も起きない。
UXの悪いPRについては、PRを作ったときにベースリポジトリに更新が走ると更新するボタンが出てくるが、これを押すと中身のない空のマージコミットが作られることや、GitHubのバグとしか思えないよく解らない差分が出ることがあるのも挙げられる。こうやってやらなくていいことを増やすだけのシステムはUXが悪いと思う。
そして行儀の悪いソフトウェアの排除だ。行儀の悪いソフトウェアとは何かというと、もっぱら権利侵害を目的に利用されているのではないかと疑われているようなものである。
かつてGitHubでホスティングされていたyoutube-dlというソフトウェアがDMCA侵害でGitHubから消されることがあり、当時は結構騒がれた話だったと思う。その後、紆余曲折ありyoutube-dlは現在は再公開されているが、最近はほとんど更新されていない。恐らくフォークであるyt-dlpに開発が移ったと思われる。
そして今年に入ってからFAKKU, LLCが大規模なDMCAを通告した。これによりGitHubから多くのダウンローダー系ツールが削除されて祭りとなった。
この対応を受け、gallery-dlはCodebergへの移行を決めた。
個人的にはTwitterの画像を落とすのにHitomi-Downloaderをよく使っていたのだが、これもDMCAに含まれており削除の憂い目にあった。Hitomi-DownloaderはTwitterがXになり、APIが有料化してからもTwitterのメディアをバルクで落とせるので重宝していた人が多くいたと思う。なおHitomi-Downloaderについては移転したとかはなく、単に消えてそうだ。バイナリはググれば出てくるが、APIが変わってるので、もう動かないと思う。余談だが、現在Twitterの画像をバルクで落とせる無料のソフトウェアはgallery-dlくらいだと思う。
また前述したGitHubの不安定さや、AIの存在を理由にGitHubを離れたものとしてプログラミング言語のZigがある。ZigはGitHubの現状に失望し、痛手を負ってでもCodebergに移行した。現在のGitHubは更新されておらず、移行のメッセージが残されている。
また玄人向けのLinuxディストリとして知られるGentoo LinuxもGitHubのLLM方針に反発し、Codebergへの移行を発表している。
Gentooの2025年振り返りでは、「Goodbye Github, welcome Codeberg」という言葉も見られ、Planet Gentooでは開発者からLLMに対する鬱憤ともいえる批判が多く寄せられている。
個人的に強く共感したものには次のものがある。
They start using LLMs because they don’t want to maintain their code anymore. Software turns into slop, which burns out even more people.
(ja: 彼らは、もうコードのメンテナンスをしたくないという理由で、LLMを使い始める。その結果、ソフトウェアはずさんなものとなり、さらに多くの人々が燃え尽きてしまう。)
LLMを使う理由はコードを書きたくないから、メンテしたくないから、動いている風に見えればよいからだというのは私も思う。バイブコーディングで出てきたものがまともに動く保証はない。
公私ともにLLMを使ってコーディングしているが、本当にそう思うし、仕事ではLLMに毒されすぎたのか判断能力を失ってしまった人も見かける。
Gentoo aims to be made by humans
We banned LLM contributions two years ago, and never regretted it. We didn’t “wait and see”, we took decisive action, and if we got left behind, it’s only for the better. I can’t give you a 100% guarantee that no tainted code slipped through, but we’re doing our best to stay vigilant. In the end, it’s all about trust, and trusting one another is what builds our community.
(ja: 私たちは2年前にLLMによる投稿を禁止しましたが、その決断を後悔したことは一度もありません。「様子を見る」のではなく、断固たる措置を講じました。もし他者に遅れをとったとしても、それはむしろ良いことなのです。不適切なコードが混入していないことを100%保証することはできませんが、私たちは警戒を怠らないよう最善を尽くしています。結局のところ、すべては信頼にかかっており、互いを信頼し合うことこそが、私たちのコミュニティを築き上げるのです。)
この人間らしさには非常に共感した。特に「もし他者に遅れをとったとしても、それはむしろ良いことなのです。」の部分だ。誰かより早くある必要はない、誰かと比べて遅れていても問題ではない。何故なら競技ではないし、そもそもベクトルが違うと私は思う。
他にもAutodesk Fusion 360 for Linuxも同様の理由でCodebergへの移行を行い、GitHubは既にアーカイブされている。
lycolia.info、つまりサイトトップを触っていて思ったのだが、自分が作ったソフトウェアを見てもらうのに外部サイトにアクセスしないといけないというのが癪だと思った。
ソフトウェアの配布なら最悪自分のサイト上でzip配布でもすりゃあいいじゃんという話だ。
ただまぁ事はそう単純でもなく、リポジトリをWebサイトに置いておくと、出先からスマホでちょろっといじりたいとか、テキストとして転がして置き、一々ダウンロードせずコピペしたいみたいな絶妙な需要を満たせるので、セルフホストでかつ、GitHubの様な機能を満たせるものというところでForgejoを採用したのである。
勿論、先述したようなGitHubへの信頼性問題もあるが、私がDMCAでどうにかなる可能性は今のところないので、まぁ宗教みたいな話ではある。
そういえば以前WSL2のUbuntu 20.04にGiteaを生やすという記事を書いたし、Giteaにはコントリビュートしたこともあるが、GiteaのフォークであるForgejoでこんなことを始めるとは夢にも思わなかったので、めぐりあわせだなぁと思うのであった。
業務用と個人用でGitHubの無料アカウントを分けるは、このブログで二番目にアクセスの多い記事だが、Forgejoに完全に移行すれば、こういったことも解消できる。
なお現状ではGitHubのアカウントそのものはOSSのコントリに使うことが稀にあるため保持しておくつもりだが、いつ消し去っても良いくらいの温度感では持っておきたい所存である。
Forgejoは、その構造上、各ホスト上でアカウントを作らないとコントリビューションができないと思うので、特定のプラットフォームからの支配や思想を回避できるのが利点だが、同時に欠点だとも感じている。
端的に言うとそれぞれのForgejoサーバーには何ら繋がりがない。あるForgejoサーバーでアカウントを作ったとしても、別のForgejoサーバーでは使えない。これはForgejoサーバーが増えれば増えるほど難しくなっていく問題かもしれない。私の様なサーバーでは問題にならないので別にいいが…。
但しFediverseにあるActivityPubのようにオープンプロトコルを作り連合を作る計画はあるようで、将来的には各ホスト同士での疎通が実現するかもしれない。
とはいえ、連合は連合で問題である。Fediverseも連合制をとっていて様々なサーバーが連合しているがMastodonとMisskeyには互換性の問題があるし、連合は数が増えれば増えるほど負荷が大きくなる問題もある。例えばA Forgejoサーバーの変更が10の連合先に伝播し、そこから更に各サーバーの先にある10に連合…となれば伝播する時間もリソースも無駄になってくる。
設計次第ではあるものの相互に繋がった数千のサーバーがやり取りを始めたらDoS攻撃に匹敵する負荷が発生するかもしれないし、様々な分散サーバーに同一の情報が保存されるのはストレージの無駄である。
この辺りはMisskeyの開発者であるsyuiloさんや、.ioの運営者である村上さんも話しているし、連合のコストについてはfedibird管理人ののえるさんも話している。
分散型はプラットフォーマの支配を受けず、独自性を出しやすい代償に、スケールしづらいのだ。ただ、DMCAの通報がされるようなソフトウェアにとってはそっちの方が都合がいいかもしれない。とはいえ、GitHubにBANされなくとも、次はAWSやVPSからBANされたり、ドメインが差し押さえられたり、自宅サーバーであってもISPから契約解除されるなどのリスクはあるので、程度問題ではある。
そういえば、この手の話をまさにしているスレッドがRedditにあったので、記録に残しておく。
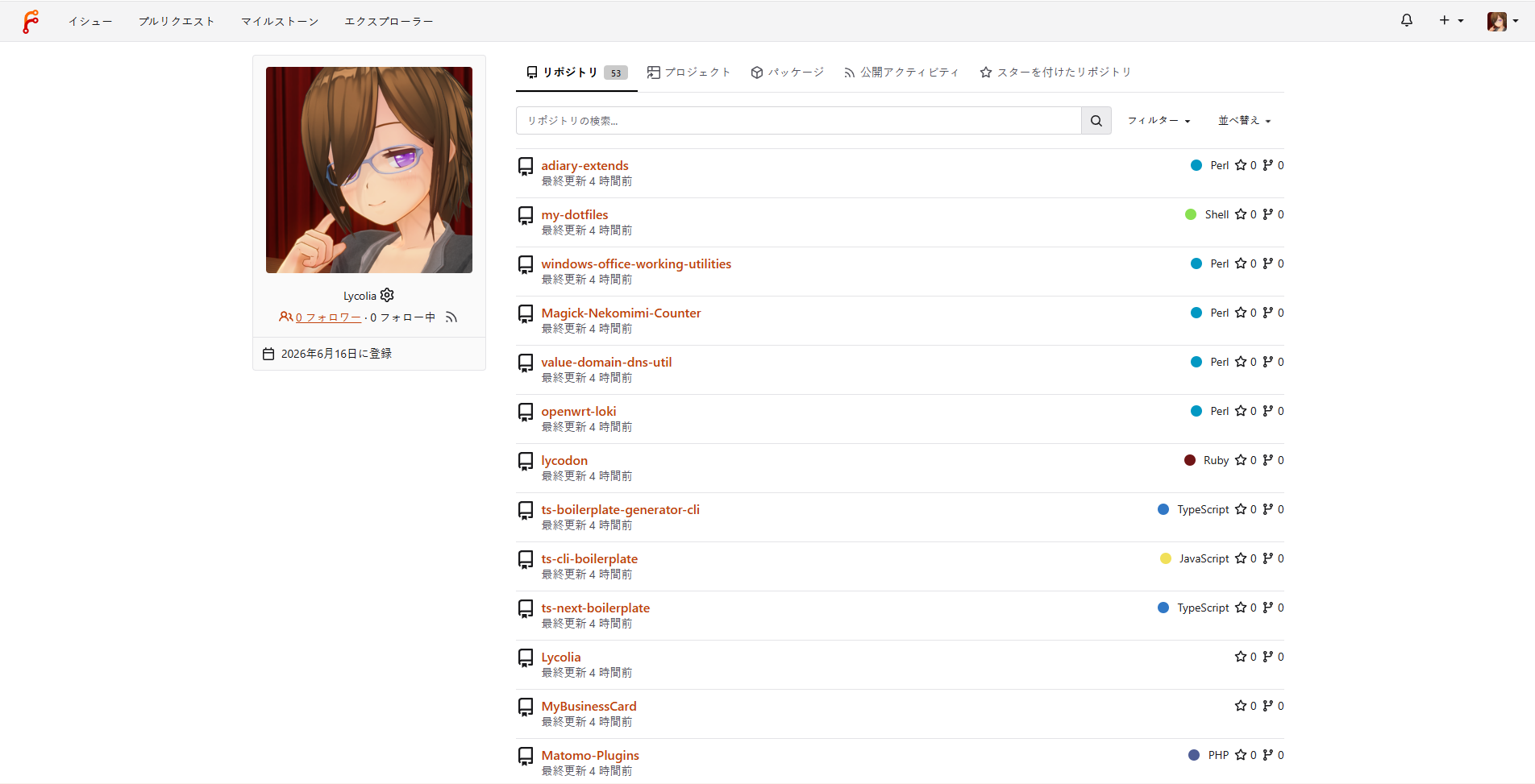
エクスプローラー - LycoGit: Lycolia's Git Hostingで公開リポジトリの一覧が見れる。
ドメイン直下にアクセスすると「自分で立てる、超簡単 Git サービス」という強めのおもしろアピールが出てくる。
今のところはGitHubのリポジトリを丸ごと移しただけなので、中身的には同じものである。