更新日:
投稿日:
世の中ではリボ払いはとかく悪者として扱われがちだが、個人的には便利な仕組みだと思っているので、振り返りがてら個人的な過去の事例を書いてゆく。リボ以外のことはあとがきにちょろっと書いている。
なお、この記事はリボ払いを推奨するものではない。リボの返済は面倒なので使わなくて済むなら使わないに越したことはないが、いざというときには頼りになる諸刃の剣といった感じの代物である。
利用の順序的には2→1→3→4。
月によって5万円だったり、20万円だったり、収入が変動する場合にリボは便利だ。
例えば翌月の収入が大幅に減ることが分かっていれば、リボの支払額を5000円など、最低支払額に設定することで、その月の不払いを逃れることができる。
その分当月分の請求が膨れ上がるが、それは翌月以降に返していけばいい。但しこれが使えるのは一瞬収入が落ちる瞬間だけで、継続的に落ちる場合は厳しい。
これは過去にSES会社で現場を切られて、なんかキレた社長から懲戒処分を受けて減給というアクシデントが起きたときの調整で使った。
気の迷いによりクレジットカードの利用枠を上限まで使い切り、現金さえも溶かしてしまったとき、こういうときにもリボは使えた。
私の利用している三井住友カードには「あとからリボ」というシステムがあり、現在までの利用分を全てリボ払いへ変更できる。これを使うことで、いきなり利用した全額が請求されることを回避できる。
この仕組みを利用することで一旦支払いについては何とかなった。しかしこの状態では、当月の生活費の捻出ができない。そこでどうするかだが、私は経験上キャリア決済が二ヶ月後に請求されることを知っていたため、これを使うことにした。キャリア決済の請求はクレジットカードに出来るため、現金がない状況でも誤魔化せたのである。
つまりクレカ利用不能+現金なしをキャリア決済を使うことで回避したという寸法だ。給与の振込日は25日、クレジットカードの引き落とし日は26日だったため、給与の入金直後にクレカの利用枠が空く。その枠で、翌月に請求されるキャリア決済分を支払うという戦略だ。
これは上手く回り、しばらくするとキャリア決済しなくてもいいだけの空きが出てきたので、そこからは普通に返済するだけでよくなった。
ある転職で東京に引っ越す必要が出たが手持ち金がない問題が発生した。
引っ越すためには不動産屋の仲介手数料に、賃貸会社への前金、初回賃料、引っ越し業者への支払いなど様々なものが必要だったが、これらを分割で払うと具合が悪い問題があった。
そこでリボにまとめることにした。分割払いだと複数の異なる支払いを丸められず、出費の管理がしんどいが、リボにすれば毎月一定額で返せばよいので考えることが減る。
更に入社後三ヶ月で祝い金が出ることが分かっており、この祝い金を受け取り、リボの返済額を満額にすることで容易に返せたため、リボとの相性がとてもよかった。
転職活動で有休を使い切り、転職間際で仕事がなく、どうせなら自由にやっていこうと欠勤をしていたら、転職後にお金が無くなったケース。
欠勤による減給により手持ち金が減るのは想定内だったし、貯蓄もあったし、それ自体は特に問題はなかった。
問題は転職後の話だ。転職した会社には入社日の出張に、首都圏への一週間の出張研修があり、4月入社というのもあって首都圏の交通宿泊費が高騰していた。
私のお財布は去年資金難になることを承知で行った佐賀旅行と、年始に壊れたモニタの購入で割とカツカツだった。こんな時にもリボは活きる。そう、リボならすべて後に回せるのである。
但しこの時は計算を誤っており、二月末にリボに設定したものを、三月末に「たぶん行けるやろ」と解除したせいで資金ショートを起こす痛い目を見た。しかし、クレカの支払いが滞ったので時系列を書き出すにも書いたとおり、資金ショートが発覚した段階で迂回策を取り、何とか途中でリボに切り替えることに成功したため、延滞こそあったものの債務不履行という致命傷は逃れられた。
今までのリボ活用経験から、ショートした翌月に請求金額を満額支払い、手持ち現金をほぼ償却、その翌月はリボ設定となった残債を少額返し、更にその翌月は現金が復帰したため通常の支払いに戻すというフローが使えた。
こちらは本記事執筆時点でまだ完済していないが、支払いが滞ったにも関わらずXperia 1 VIIIの与信は通って買えた。
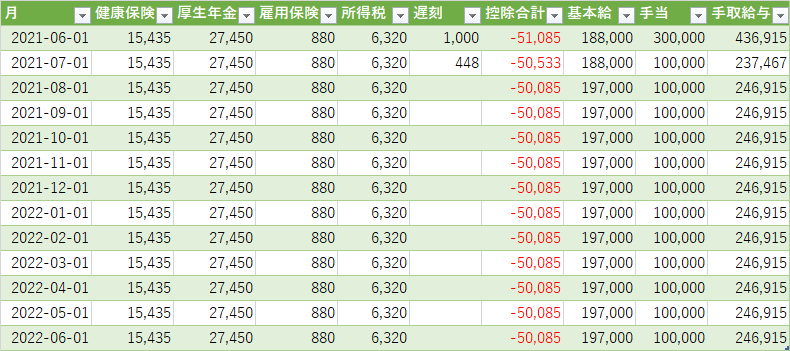
一回目のリボは返済表が残っていなかったが、記憶が確かなら毎月の遅刻と残業を記録することで当月の総支給と税金を計算し、手取りを弾き出すことで翌月支給される給与のうちどの程度を返済に充てられるか計算する機能があったと思う。
この時が人生で初めて自分の給与計算をした時だったと記憶している。確か予実計算には数円の誤差しかなった気がするが、よく覚えていない。
この表は一回目のリボ返済に使った表を転用した上で一部簡略化したり、形式を変えたりしているが、一回目の表が残っていないため比較できないのが残念だ。
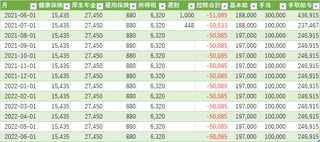
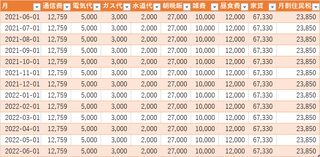
この当時は支給される給与から手取りを計算したり、固定費をはじき出して目測を立てる方向で返済計画を立てていた。
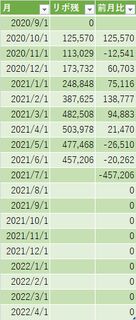
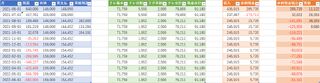
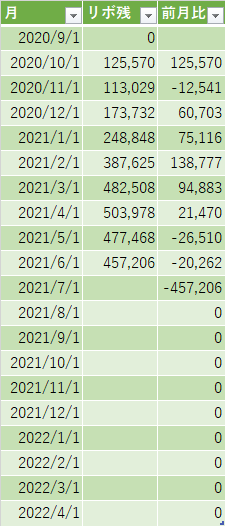
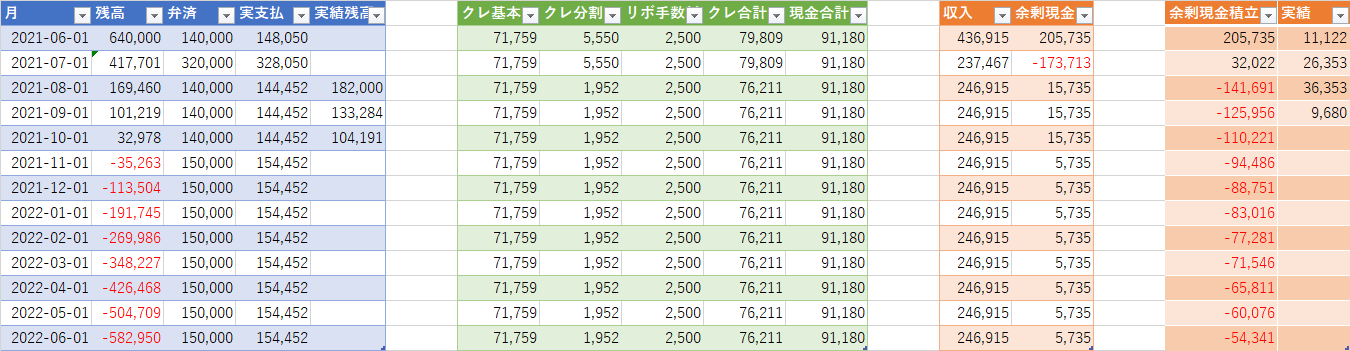
この表は実際の予実表だが、途中で方式を変更しているようで、一枚目の表は2020年9月から始まり、2021年6月で切れているが、二枚目の表がそのあとに続いているのを見た感じ2021年の11月に完済したものとみられる。
見ていると2020年10月は減っているのに、そこから2021年4月までは残債が増えているのである。確かこの時、家の鍵が壊れたり、事故にあったりで謎の出費が多かった気がする。
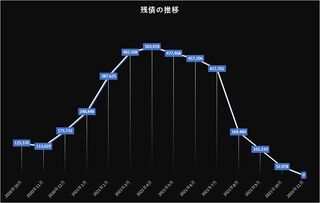
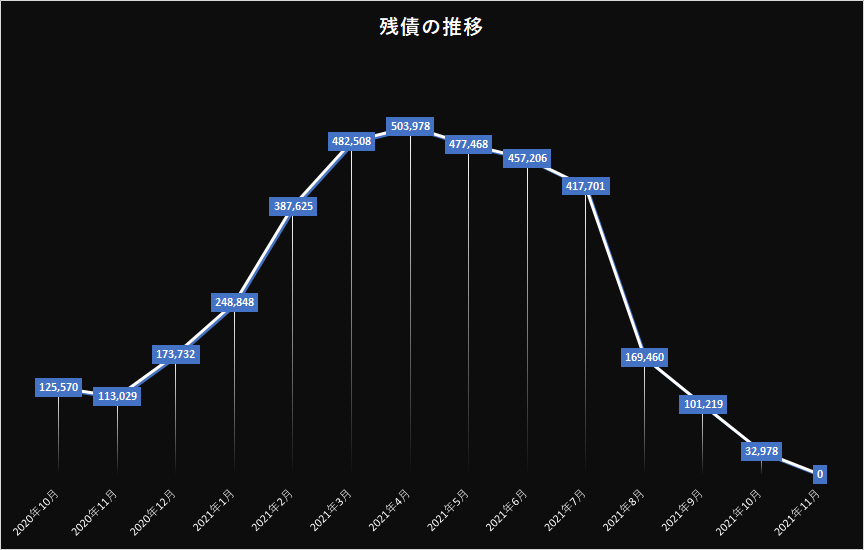
恐らく全期間での推移をグラフにするとこんな感じだろう。リボは良くも悪くも増えるので、気を抜いているとモリモリ増えてしまう。

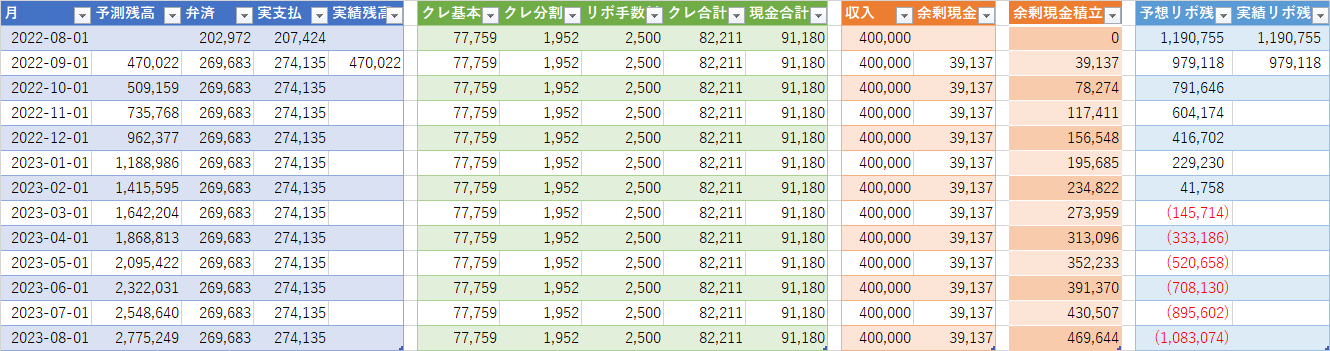
一回目の表を転用し計画を立てていたようだが記入の痕跡がほとんど残っていない。9月に入社祝い金が出てチャラに出来たはずなので恐らく表を作るだけ作って管理していない手抜きである。
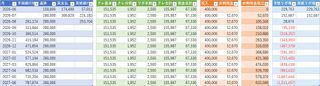
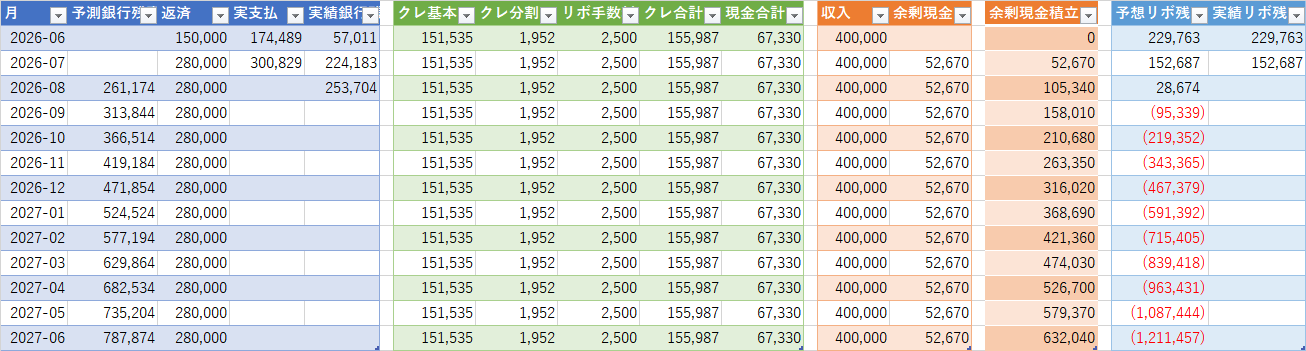
現状の目測では悲観的に見ても今年中には返済できる予定だ。楽観だと二ヶ月後だが、何故か旅行に行くことにしたのでこれは無理だろう。
まずここで言うリボ払いとは、残高スライド式リボルビング方式と呼ばれるものだ。
さて世の中では邪険にされているリボ払いだが、何が問題なのだろうか?
端的に言うとリボ払いは残債が見えづらい上に、使い方次第で増えてしまうのだ。これは見方を変えれば利点だが、多くの人には恐らく欠点だろう。
そしてリボ払いというのはだるま落としに似ている。
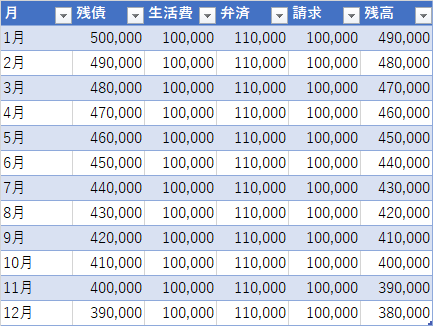
例えばリボ払いの初期残債が50万円で、月の生活費が10万円あり、毎月11万円返済するとする。すると11万円返しているので11万円減るはずである。
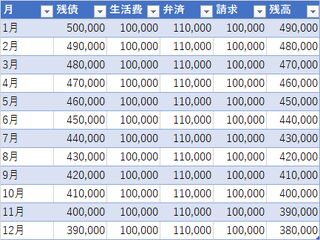
しかしこの場合、減るのは1万円である。理由は単純で10万円増えて11万払っているから差額の1万円しか減らないという訳だ。
これが残高がスライドするという話である。1万円のブロックが10個増えて、11個落とすから、いつの日かはだるまが落としきれる。単純計算だと50ヶ月後くらい。
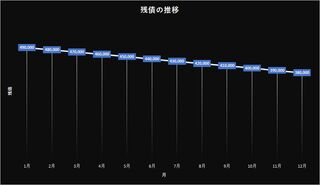
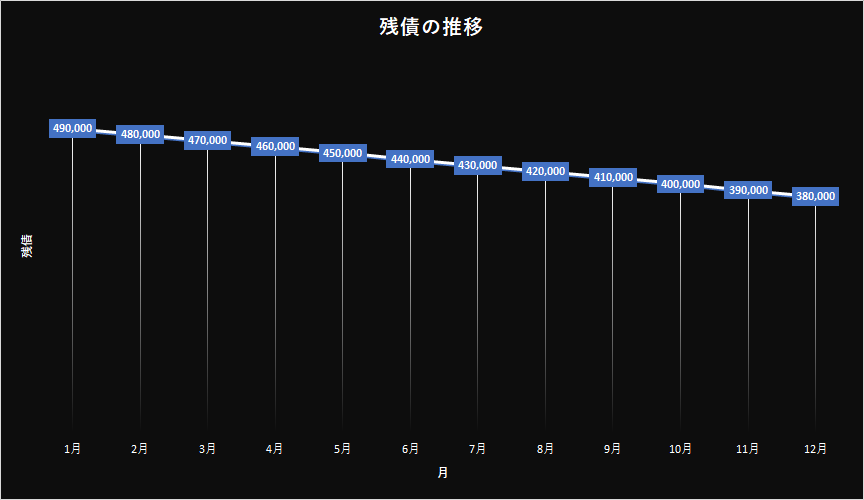
グラフにするとこんな感じ。現実には手数料が入るためもっと減らない。つまり50ヶ月では済まない。恐らく52ヶ月程度かかるのではなかろうか?単純計算で完済に4年掛かる。
更にもし月10万円しか使わないはずが15万円使ったらどうなるだろうか?15 - 11 = 4で4万円増えるので、逆に借金が増えるのである。ブロックが14個増えて、11個落とすのでは減ることがない。前に書いたグラフでもなんか増えてるやつがあるが、まさにそれである。
分割払いの場合は毎月固定額が落ちていくのでいつかは消えるが、リボ払いはそうはならない。逆に増やすことができるので支出が苦しい時は増やして回避することができるのがリボの長所でもある。分割払いはこの月だけ支払額を減らすというのは普通出来ない。
そしてこの仕組みこそがリボが無限借金地獄のように扱われる元凶でもある。
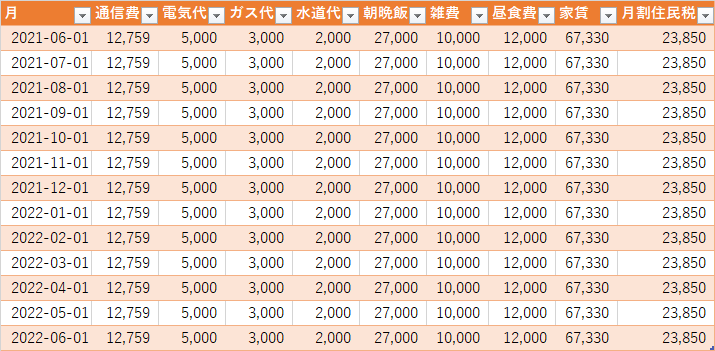
また、リボと分割を併用している場合、分割分はリボに乗ってこないためリボ払いの返済額+分割払いの月次返済で二重苦になる。やるならどちらかに寄せておくのが良いが、分割払い中にリボを使う羽目になった場合、もうそこは覚悟を決めるしかない。なお先に掲載した表には「クレ分割」という列があるが、これは分割払いが固定で入ってくるので、それを勘案したものである。
要するに私は当時分割払いの固定請求とリボの返済を両輪で捌いていた訳だ。
基本的には諸事情あって請求が膨れ上がったときにでも不払いになるような詰みを回避できるところだとは思う。
特に収入が不安定な時でも支払額を調整できるため収入に波がある場合でも少ない月は減らし、多い月は増やすという制御ができるため、そういったリスクを回避しやすい。
手数料だの年利だのはどうしてもついてくるがクレヒスに傷を入れたり破産するよりはマシだろう。
自慢ではないが私は過去に住民税を一年三ヶ月くらい滞納して財産の差し押さえ予告が送られてきたことがあるが、これも完納したことがある。これは役所の税務課へ出向き計画を示せば対応してくれる。
但し当年の納税分と過去の滞納分を同時に払うことになるため、中々苦しい。記憶が確かなら24回払いで完納した記憶がある。
この期間は国保にも入らずいたりして、中々壮絶な暮らしをしていたが、電気ガス水道通信費やクレカの支払いはちゃんとしていた。
国保未加入状態から国保に入ると確か未払い金の請求が来るのだが、社保に入って五年経つと時効で消滅するという事情があるため、未払い請求を回避する技もあったりする。とはいえ、全国民の保険金の原資であることから、とても勧められる行為ではない。他にも国保は自治体が管理しているので引っ越すと未払いだった過去が消えるとかいろいろある。実際に五年経過後に国保に入ったことがあるが、特に何も起きなかった。
まぁという訳で、自分は割合借金とかその手のものを返してきたなぁというのもあって書いてみた。と言うかこのネタは書こう書こうと思い二年くらいが経過したので、いい加減書こうという気持ちになったというのもある。ある意味、前日の資金ショート事件辺りはこの記事を書く良い刺激になった気もしている。