ここ最近メンタルの微妙さや、週末に病院が入っていたりで全然映画が見れておらず、がんばっていきまっしょい が鑑賞できずにいた。
しかしこのままでは見れないまま終わってしまうのでどうにかしようということで、一揆奮闘し、先の12/14に見に行くことにした。
まず上映館を調べたが、近隣での上映は全滅していた。10/25公開の映画なので無理もない。先週くらいまで名古屋でもやってた気がするのだが、それも終わっていた。残っていたのは愛媛と東京だけだった。本作は愛媛が舞台の映画なので愛媛で見ることに決めた。
次にいつ行くかだが、遠方なので日曜は避けたかった。そして次の土曜日は歯医者、その次の土曜日も歯医者というスケジュールがあり、歯の健康のために、これは外したくなかった。因みに愛媛の先行上映会も歯医者で潰れており、がんばっていきまっしょい鑑賞は歯医者に邪魔をされている。
しかし最初の土曜日の歯医者は10:00~10:30だったので、16:40~の上映には間に合うのではないかと思い、調べてみたところ、航空便であれば間に合うという結果が出たので早速航空券をとることにした。映画を見に行くために飛行機に乗るというのはなかなか斬新な発想だと思う。
当日になり、歯医者での用を済ませた私は早速、伊丹空港に向かった。伊丹空港に来るのはこれが初めてだったが、普段映画を見にエキスポシティに行くルートとよく似ていたので迷わずに行けた。違いは蛍池で千里中央に行くか、空港に行くかくらい。移動中にSMSで乗り場が7番に変わったという連絡がきた。
伊丹空港につき、案内表を見ていると早速松山行きが出ていたが、番号は8番に変わっていた。松山行きの便は遅れており、この後も7→8と変わったが、全部が全部SMSで連絡されることはなく、最後の案内はなぜかメールできたので謎だった。
空港内の手続きは大体自動化されていて快適だった。
保安検査場の前に何やら怖そうな展示があったのでよく見てみるとハサミが持ち込めないとあり、筆箱の中にハサミが入っているのが気にかかったが手荷物扱いならいけることに気づき、ちょっとSF感のある預入機に投入した。なかなか便利な機械だ。最初筆箱だけ入れることを考えたがロストバゲッジしそうなのと、筆箱の中身が壊れそうなのでカバンごと入れることにした。バスとの乗り継ぎが10分しかなく、荷物を受け取ってバスに間に合うか心配したが、さすがに想定されていることを信じて突っ込んだ。
保安検査場にはWebでよく見かける対応はいかがでしたかボタンが置いてあったが誰が押すのだろうと訝しみつつ、取りあえずGoodを押しておいた。
保安検査を抜けると豊岡鞄が売られていた。神戸で見た記憶がないので少し驚いた。豊岡以外でも買えるんだ。
搭乗口まで来るとTHE 飛行場という光景が広がっており、眺めて暇をつぶすのには事欠かなかった。こういうのはいつまでも見ていられる。
そして定刻より10分遅れで、今回の搭乗機であるデ・ハビランド・カナダ Dash 8 がやってきた。ボーディングブリッジはなくタラップから乗るやつだ。聞きなれない名前だが中身はボンバルディア DHC-8である。
傘が持ち込めないため建屋出口には雨天時の傘が置いてあった。
いざ近づいてみると、機体側にタラップがあることに気づき、死重にしか見えず存在価値があるのだろうかと思ったが深く気にしないことにした。(きっとタラップのない空港でも運用しているのだろう…余計に食う燃料代で買えそうな気もするが…)
離陸時にはいい感じにGがかかって軽くジェットコースターに乗っているような気分が味わえてよかった。また気象の関係で揺れるというアナウンスがあったものの、特に揺れは感じなかった。
機内では飴をもらえた。遅延のお詫びらしい。ANAのロゴが入っていて、大阪産品なのは関西人として少し感心した。また揺れてすみませんという謎のお詫びもいただいたが、揺れを防ぐことができないのに謝ってどうするのかと思うなどしていた。個人的には特に揺れていなかったとは思う。
松山まではわずか一時間の旅で、上昇しきったらすぐ降下する感じだったのでベルトを外せる時間はわずか五分しかなく、恐ろしく飛行機で行く意味がないなと思ったが、海を隔てている関係で直線的に行ける経路が空路くらいしかないので、どうしようもない。参考までに三宮からだと新幹線と特急の乗り継ぎで4h、高速バスで5hくらい。それに対して空路は3hとだいぶ優位性がある。特に時間的に他に選択肢がない場合、非常に強力だ。
そうこうしているうちに松山空港が見えてきた。山側から入ってオーバーランすると海に落ちそうな空港だが、海上空港もそう変わらんなと思った。
周囲は田んぼが広がっていてのどかな光景が延々続いていた。これでも松山市内にあり、中心部からも程よく近いためアクセスは悪くない。なお鉄道アクセスはなく、接続する公共交通機関はリムジンバスと路線バスのみだ。
松山空港ではボーディングブリッジから空港へ入ることができ、一六タルトが出迎えてくれ、その次はみきゃんが迎えてくれた。
心配していた手荷物受取は心配するほどのものではなく、ボーディングブリッジを渡り一分も歩けば受取場がある上に、出口が目の前にあるため三分もあれば出られる設計だった。荷物が出てくるのが多少遅くても十分間に合うだろう。
空港出口には伊予鉄のICカードが売られていた。個人的にはなくても困らなかったが、伊予鉄高浜線はこのカードにしか対応していないらしく、カードがない場合、切符購入となるため、買っておくと多少便利かもしれない。
ここからはバスで松山駅へ向かう。
ここからは松山市駅行きのリムジンバスで松山駅へ向かう。松山駅と松山市駅は別物なので注意が必要だ。このリムジンバスは交通系ICカード全国相互利用サービスのものであれば基本使えるようだった。SF利用のためPiTaPaの人は事前にチャージしておこう。
空港のバス乗り場では奥のバスや路面バスも軒並みみかんカラーだったので愛媛をすごく感じた。
バスの搭乗口、全国共通利用は青いほう。多分オレンジは伊予鉄のやつ。最初間違えてタッチして???となっていた。青いほうはちょっと手前過ぎて気づきづらいw
道中で見かけた工事現場のアレがみきゃんになっていて、無限の愛媛愛を感じていた。くすりのレデイという聞いたことのないドラッグストアもあり、愛媛の独立感を感じるバス旅となった。地方の特色がみられるのはとてもいい。
そしてバスに乗っている間にうかどんで「空港の中に、生のほうの鯛めしの店があるゾ」 と言われたので、これから行く先では宇和島鯛めしを食べようと心に決めるのだった。
松山駅に到着、相変わらずみかん色のバスが並ぶが一台空気読めてないのがいた。伊予鉄のじゃないから仕方ない。
東京のマンションデベであるタカラレーベンの看板があって驚いたが、後で調べたところ、かつて松山市に系列企業があったようで、どうやらその名残っぽかった。
他にも伯方の塩もあった。伯方の塩はオーストラリアの塩を瀬戸内海の水に漬けて作ってるらしい。意味あるのかそれは。
駅前に大きなモニタがあると都会感があってよいが、駅前はどちらかというと寂れており、一個前の写真にあるあかやねビジョンもあんまり存在感なかった。どちらかというと左手奥に見えるパチ屋の存在感とタカラレーベンのクソデカ広告の存在感が異様で、それに隠れていたように思う。
他にも駅のターミナルには相当古い形式の機械式駐車機が設置されおり、大変歴史を感じるなどした。
肝心の松山駅だが、リニューアルされたと聞いていたのに、かなり寂れていた。なんだろう、この場末感は…w 店の行灯を讃岐うどんの箱で隠してるのは四国らしいが、松山ならみかん箱にしてほしかった()
駅前面にある店は恐らくすべて閉店しており、なんともな具合だった。バスターミナルには近隣の府県が書かれており親近感を覚えるが、東京などの遠方が書かれていないのが気になる。なんか白く塗りつぶされているように見えるので昔はあったのかもしれない。ところで三宮を三ノ宮と書くのはやめてほしい。JRなので仕方ないが…。
さて、肝心の松山駅に入っていこうと思う。どっしりしており、歴史が感じられる佇まいだ。松山驛と旧字体なのが特にいい。山の字体もいい。
駅は絶賛工事中という感じで、旧駅部分は線路の上に仮通路を架橋し、新駅につないでいる構造だった。しかし三宮駅もそうだけど流線型のデザインが流行ってるのだろうか?既視感がすごい…w
新駅の中は木の温かみがあっていい感じだった。九月ごろにできたばかりのはずなのでピカピカだ。
愛媛には愛媛ジェーシービーというものがあるらしい。四国ジェーシービーでなくて愛媛ジェーシービーなのが面白い。
駅に来たものの別にJRに乗る用事はなく、映画の上映時間までの暇つぶしで来たので、まずは腹ごしらえをすることにした。そもそも歯医者に行くために朝を抜いており、歯医者を出たら松山まで食べる余裕がどこにもなかったし、鯛めしが食いたいというのもあり、きっとあるだろうと思い探すことにした。
調理時間やゆったり食べる時間との兼ね合いで電車に間に合うかどうかが心配だったが、杞憂だった。30秒くらいで出てきた。
30秒くらいで駅内の食堂を見つけ、愛媛の鯛めし食べ比べ定食を注文。愛媛鯛めしと宇和島鯛めしが楽しめる一品だ。
まずは宇和島鯛めしから。生卵と鯛の刺身が合わさりビジュアル的には最強と言える。味はまぁ…卵かけご飯に真鯛の刺身乗せただけなので、あまり衝撃的なものではなかった。どっちかと言うとダシが効いてた普通の鯛めしのほうが美味かったというか…w
食べ終わったら土産が欲しいなということで土産を物色することに。とはいえ時間に余裕があるわけでもないのでサッと見てよさげなものをチョイスしていった。
まずはあからさまにオタク受けを狙った煎餅。道後温泉があるのに温泉娘ですらないオリジナルキャラで勝負してくるあたりが強い。しかもかわいいし!
次に愛媛県のヒノキで作られたという箸置き。実は今使っている箸置きに不満があり、数年間いい感じの箸置きを探していたのだが一目ぼれしたので買うことにした。他にもコースターや弁当箱など様々な木製食器が売られていた。
他にも買ってないけど土産はかなり充実していて、大変目移りする内容だった。神戸や岡山、高松はここまでではなかったと思う。みかんや道後温泉、今治タオルは確かに鉄板とはいえ、愛媛の力をすごく感じた。これだけの商品力は他の地域ではなかなか真似できないのでは?
土産をじっくり物色したいところだったが、今回の目的は映画鑑賞である。明らかに関係ないことをガンガン書いてきていて目的を見失いかけているが、映画を見に来たのである。
まずは伊予鉄の駅へ向かう。道路の真ん中にあっていくのメンドそうだなぁ…。なんか地下道みたいなところからいけないかな?と思ったら行けたので松山は偉大である。流石、高松より都会といわれるだけはある。
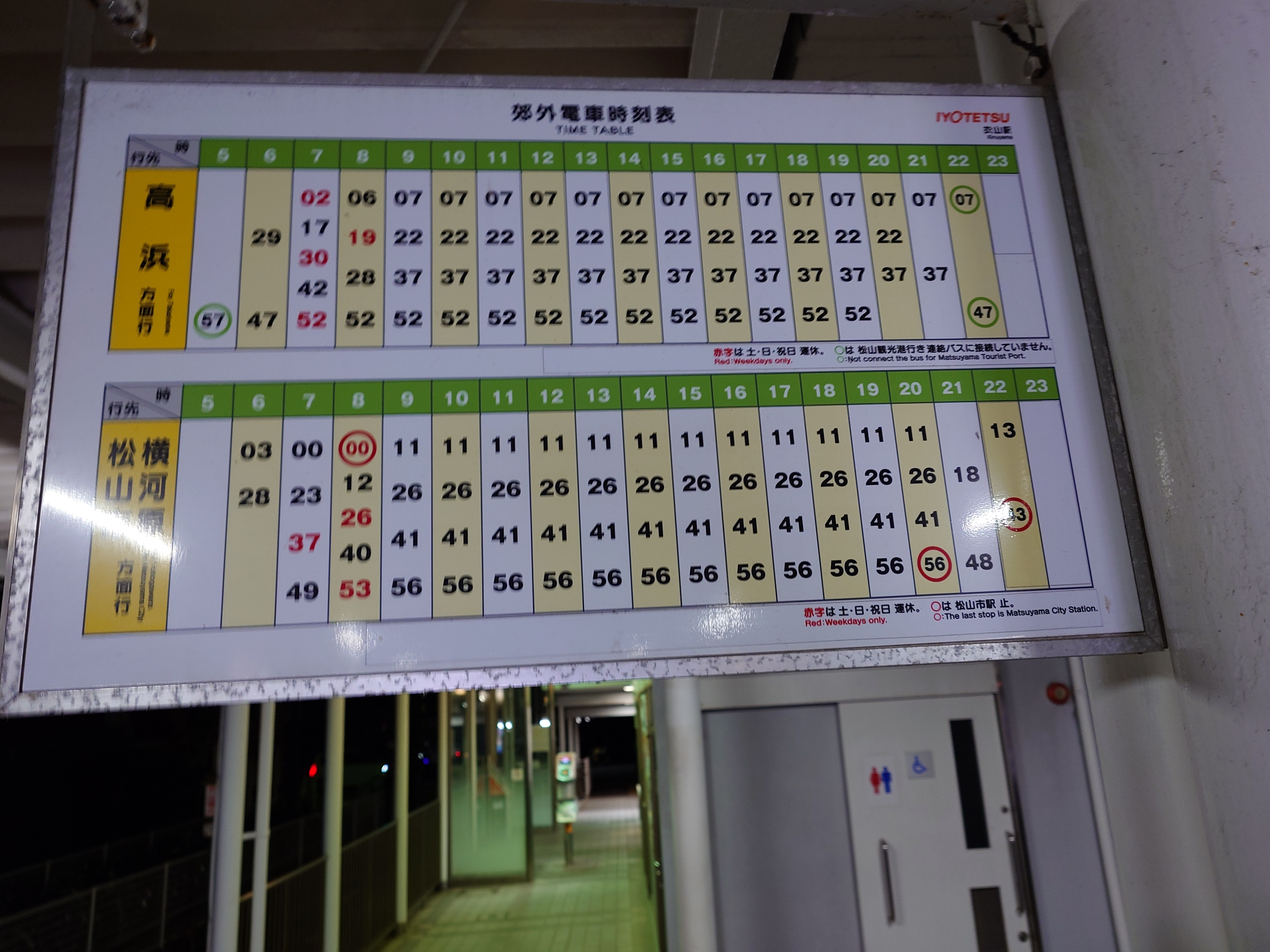
伊予鉄市内電車(路面電車のこと)の本数は結構あり、割と何も考えず乗れるのはいいなと思った。
待っていたらカッコいい感じのがきてテンションが上がった。車内は広く、座席も多く、広電より快適だった。線路が石畳の上にあるのもいい(いやまぁ岡電や広電にもあるが)
一駅乗車し、大手町駅へ。線路が水平交差(ダイアモンドクロス)しているのが良い。なお余りにも近すぎて歩いたほうが早かった。
大手町駅構内、ICカードタッチは伊予鉄専用のものしかなく、持ってなければ切符を買うことになるが改札はなかった。そもそも駅員がいなかった。しかしICカードの代表がSuica, PASMOなのが東京一極集中の象徴みたいでなんかいやである。ICOCAのサービスエリアでしょここwと思いたくなる。
線路は複線で電化されており、田舎の線路という雰囲気はない。法令で定められているはずなので当たり前だが線路上には保安装置も見える。
駅で待っているとみかん色の列車がやってきた。
衣山で下車。ここでは駅員がおり、切符が回収された。100均で売ってそうなトレーに入れる方式で、たぶん省エネだった。JRの無人駅では切符は箱に入れる方式なのでキセルができてしまうが、伊予鉄形式ではしづらいのでよく出来てるなと感じた。
さて、ここまで延々長々と一切関係ないことを羅列してきたが、やっと目的地であるシネマサンシャイン衣山へやってくることができた。今思えば先行上映のあったエミフルMASAKIの方に行けばよかった気がするが、この時はまだそれに気が付いていなかった。エミフルMASAKIでの上映は明日で打ち切られるので今から行くのは現実味が薄いが、行けばシネマ5、153席の大箱で見れるようだ。衣山の上映は95席の最小箱が設定されており、終映前の追い込み部屋である。あと衣山の建物はやや老朽化感が否めないが、エミフルの方はWikipediaを見る限り立派なようだ。
2Fであまり高い場所ではないが開けており、眺望は意外と良かった。
さて待望の「がんばっていきまっしょい」とのご対面だ。先行上映に急な歯医者で行けず、その後も体調不良が続きなかなか来れなかったが、ついにやっと来れた。Xのフォロワーが良く上げていた写真の場所に、やっとこれた。恐らくここまで来れていなかったからこそこれたと思う。そうでなかったらたぶん神戸で見て終わっていたので、これは巡りあわせだと思う。
因みに1Fには小売業界で有名なFujiが入っていた。Fujiは愛媛発祥のGMSで、愛媛県近郊では結構な力を持つと聞く。因みに空港から松山駅に移動するバスの中で見た「くすりのレデイ」もFuji系列らしい。
さて見た感想だが、これはいい、あんま話題になってない気もするが個人的には今年の最高作かもしれない。いや、そもそも私は話題作とかほとんど見てないと思うが…w
内容的にはスポ根系で、非積極的で根暗な主人公が、成長していくにつれ、立派になっていき、最終的にはリーダーシップを奮っていく感じの成長ストーリーだ。
伏線が結構あるが、意図的に回収せず、捨てることで演出するという面白い部分があるのも個人的に惹かれた。つまり伏線に見せかけておいて、実は伏線ではないのだ。この部分は本来主人公が恋愛に走るありがちな道を捨てて、ストイックにボートに向かっていく筋書きを作るのに非常に役立っていると感じた。
出てくる風景も愛媛特有のものが多く、しかも他の地方にはまずないであろう物を出してくる。何よりあからさまに愛媛を想起させるみかんは出てこない。狙ってない感じがいいのだ。
そしてキャラクターも男1に対し女多数というハーレム形式だが、色恋要素が主体ではない。あくまでスポ根を往くのだ。そう、少し恋を覚えそうになっても、それを振り切っていく感じ、ボートをやる、勝つという情熱。一度は情念に振り回されることがあれど、それを振り切る強さ、そういうところがいい。
本作はオタク向け萌えアニメの分類に入ると思うが、描写は非常に真面目で、健全だ。恐らく老若男女問わず誰が見ても安心できるだろう。過激な表現はほとんどないといっても支障ないと個人的には思う。性的に見える表現を極力排除し、それでいて違和感のない描き方にとどめているのは中々ないと思う。特定の部位の強調なども一切ない。
本作の監督は櫻木優平なのだが、前回監督作である「あした世界が終わるとしても」でも比較的真面目な描写が基調にあったと思うので、恐らくこの監督はこういう作風が得意なのかもしれない。因みに「あした世界が終わるとしても」も3Dアニメ映画作品である。
「あした世界が終わるとしても」は自分の稼ぎで初めて見た映画というのだけあって、また櫻木優平監督作品を見れたのもうれしく思う。
是非もう一度映画館で観たいので、もし来週も衣山で上映していれば見に行くかもしれない。衣山は12月下旬まで上映予定としかないので、いつ終わるのかが見通せないのだ。とはいえ、行ったときは4割ほど埋まっていたので、やってくれる可能性はゼロではないと思うが、一般的に木曜で打ち切られるので、土曜までやってくれないと厳しさを感じる。その次の週だと12月を超えてしまうので、どこまでやってくれるのか次第である。
シネマサンシャイン重信は終映予定が出ていないので、仮に衣山が終わっていても、ここなら見れる可能性がある。
衣山の力の入れ方がすごいので出来れば続いてほしいが…。正直10/25公開で12/15には東京と愛媛以外全滅の状態でエントランスをここまでやってくれてるのはもう愛としか言えない。愛ゆえに、あと少し、もう少しだけどうかお願いしたいところだ。
夕方の眺望もなかなかだったが、夜もなかなかだった。24h営業のネカフェがあるのにも驚いた。こんなとこに客来るのか?
時間に余裕があったのでゲームセンターに入ったらAtariの筐体があった。アタリショックのあのAtariのだろうか?
他にも神戸のローソンとかでよく見かける小型プライズを見かけたり、懐かしの機体を見かけたりした。
キャッシングコーナーは愛媛一色という感じで、なんでこんなに地場の金融機関あるのかと驚いたりした。
商業施設に自転車の空気があるのは便利だなとか。しかも無料。
懐かしそうなお店があったりして、なかなか楽しかった。しかしずっと居るわけにもいかないので帰路に就くことにした。
帰りの衣山では改札が行われており切符にスタンプが押された。パチンとするやつではなくハンコみたいなやつだった。
衣山駅のホームにはセブンティーンアイスの自販機があり待ち時間にアイス食べれるのはいいなと思った。
列車本数は結構あり、適当に来ても困らない感じだ。松山市駅から直通なら次来るときは市駅まで行ってもいいかもしれないなとも。いや次は流石に飛行機で来ないと思うが…。
帰りの電車は行きより一両多く三両編成だった。地方私鉄にしてはゴージャスである。山陽本線でも三両編成いなかったっけ…?
廃駅となった松山駅は二代目として71年もの間使われていたらしい。新駅ができる前は中心的都市では唯一奥ゆかしい改札(箱に人が入ってるタイプの有人改札)が残っていたらしいので、その光景が見てみたかったものだ…。丁度年の区切りになるときまでは引っ張ってくれたJRの良心に感動してしまう。
さて、松山駅まで帰ってきて、次はフェリー行きのバスに乗るのだが、時間に余裕があるので土産を物色する。
みかん石鹸からみかん入浴剤、定番の湯の花といったものから
みきゃんラーメンやみかんご飯という黒歴史に至るまで面白いものもある。因みにみきゃんラーメンにみかん成分は一切ない。
他にもみかん箱を模したものや、定番と言えるみかんジュースなど魅力的な品々が多数あった。
蛇口から出るみかんジュースは残念ながら飲めなかった。次来たら是非飲みたい。なお裏には普通にドリンクサーバーが置いてあったが見なかったことにした。
そろそろバスの時間なので松山駅を出ようとしたらあったかいメッセージに心が惹かれた。愛媛はええなぁ…!
駅を出るとMATSUYAMA INFOMATIONと書かれたいい感じのビューが設置されていた。あかやねビジョンよりこっちの方が個人的には好きだ。
空を望めば月に叢雲がかかっており、風流だった。さてそろそろバスを探そう。六番乗り場ってどこだ?
バスターミナルの全体図が見当たらなかったので地面の番号を眺めながら歩いてたら丁度やってきた。
フェリー乗船と合わせてバス代金を支払うことができるようだが、手続きが複雑なのか未払いでトラブルになっている人が何人かいたので、事前予約するときは注意した方がいいかもしれない。
さて、いよいよフェリー乗り場に到着だ。
入ってまず目に入ったのは四国初のセブンティーンアイスの自販機。フェリーに持っていくと食べるまでに溶けると思うので待合室向けだろう。
大阪行きフェリーなので大阪の交通情報も入っていた。生田川IC手前の電光掲示板にも書いてある内容なのでほっこりした。
電話予約したので乗船名簿を書くことができた。オレンジフェリーは出航日前日にはWeb予約が閉じてしまうようで、電話で空室確認をするついでに予約も入れたのだ。
オレンジフェリーはジャンボフェリーのようにQR乗船には対応していないのか、受付窓口には列ができていた。必ず窓口を通す必要があるのかな?
乗船受付では翌朝の朝食を予約することができ、和食と洋食が選べるのだが和食は予約限定、洋食は予約してると割引ありという内容だった。洋食は当日の朝でも買えるらしい。恐らく和食は調理工程があるので、その関係だろう。(洋食は注文を受けてからでもなんとかなるのだと思う)
受付には「こえる大峠さん」のイラストが飾ってあった。絵柄がむっちりしていてよい。
周りを見るのに夢中だったりして受付で時間がかかってしまったが、いよいよ乗船だ。今回は「おれんじ えひめ」に乗る。
オレンジフェリーの銘板が光る。地場である今治で建造されたそうで、愛媛の誇りともいえる船だと感じた。見たところ2018年建造だろうか、結構新しい船だ。
入り口のドアはガラス張りでおしゃれで、その奥もなんか豪華に見える。ジャンボフェリーのりつりん2も入口は中々絢爛だったが、その比ではない。入ったらホテルマンのような人に部屋を案内され、ホテルのフロントみたいなのまであった。
オレンジフェリーはジャンボフェリーと違い椅子に座って乗るという選択肢がないので、乗船する場合は部屋をとるので部屋に移動するのだが、その時の通路の様子はさながらホテルである。
バリアフリーにも配慮されており、バリアフリー室の前には点字ブロックがあったりで、下手なホテルより配慮が行き届いてると感じた。
取った部屋は一番安いシングルだが、十分な広さがある。ノートPCを置いて作業できる程度の広さの机やコンセントも二口あり、椅子もしっかりあるので乗船しながら不自由なく作業することもできそうだ。机の下には救命胴着が入っていたので、物入にするのはあまり良くないだろう。
ハンガーもあり、ベッドの下に靴も入れられるため、収納に困ることはなかった。スリッパがあるのもありがたい。部屋の等級によってスリッパも変わるのか、グレードの高そうなスリッパを履いてる人も見かけた。
空調は集中管理方式で温度が調整できなかったが、吹き出し口を塞ぐことはできた。一等室であれば温度調整ができるらしい。
搭乗してすぐに「22:30で船内レストランは終わりで、それ以降の飲食提供はできません。」という感じのアナウンスが流れてきた。案内がイマイチ分かりづらいのだがラストオーダーが22:30ということらしかった。因みに食べるだけなら自販機で軽食が売ってるので別に食べれる。アルコール類は自販機がないので、持ち込んでいなければこれが最後のチャンスだ。
レストラン前には食欲をそそるいい感じのメニューが貼ってあった。
レストランの営業時間が書いてあるが、夜はLO、朝は営業終了時間のようだった。朝のLOは7時と案内されていたと思う。
カフェテリア形式は謎だが要はセルフである。レストラン前のメニューが食べたい人はすべて無視して一番奥で頼めばよい。
土産売り場も兼ねているらしいが、神戸プリンやパインアメなど、イマイチ分からないものが多く、愛媛土産は多くなさそうだった。パインアメはギリギリ大阪土産と言えなくもなさそうだが、愛媛でも買えるだろうし、置いてる意味が謎だった。一番謎なのは神戸プリンだが、一応大阪・神戸行きらしいので、あるのだろう。神戸には寄らないし、フェリーが着岸する大阪南港からのアクセスも良くはないので、イマイチ謎だが、たぶん雰囲気だろう。
カフェテリアのメニューは豊富で、これだけでも十分といえるほどにはあったが、私はおでんだけ取って、あとは鯛だし塩ラーメンを頼むことにした。
おでんは牛すじと麦味噌がなんともたまらなかったし、ラーメンの方はよくある冷凍麺を使っているように見えたが、ダシがよく、大変おいしかった。
オレンジフェリー内には「がんばっていきまっしょい」の船内展示がある](https://www.orange-ferry.co.jp/6884.html)というのを公式サイトで見たので、それを探してみることにした。
すると1Fエントランスに掲示を見つけることができた。
パンフレットも置いてあり、オレンジフェリーオリジナルのものもあった。そういえばインスタのパンフはもらってなかったのに気が付いた。(その左右のは貰った)
こえる大峠さんと一緒にポスターが掲示されているされている場所もあった。
こえる大峠さんのポスターと単行本。なんと単行本を借りることができるようで、乗船すると無料で読めるようだ。この時は余裕がなかったが次回があれば読みたいところ。
しかしパネル展示は「おれんじ おおさか」にあるようで、今回乗船した「おれんじ えひめ」にはなかったのが残念だった。
結構大きな船で色々ありそうなので適当に散策してみることにした。
エントランスホールは明るく豪華で見ごたえがあった。ジャンボフェリーもここは立派だったので、そういうものなのかもしれない。
浴衣がもらえたりするフロント。ホテルのフロントみたいな見た目で、ホテルとしか言いようがない。営業時間外は鉄格子が下りていた。
フロント横にはフェリーが今どこにいるのか見れるモニターもあり、周りの島や橋を見るときの参考になりそうだった。
橋が見たい人向けの案内も掲示があった。
1F自販機、飲料と軽食が売られていた。ポンジュースはなかった。コーヒーの販売機もあり、至れり尽くせりだ。
2F自販機、アニメティが売られており大浴場に入るときに便利だ。今治タオルかどうかはわからなかったが、オレンジフェリーのロゴが入っていたので記念に持って帰っていいかもしれない。クオリティは銭湯のタオルなので使い捨て品に近く、家庭で繰り返し使うのは不向きだろう。ティッシュもあり、花粉症の時期にも安心できそうだ。
ゲームコーナーもあった。建造された年から考えるとだいぶ時代錯誤な気もするが、パチスロとプライズしかなかったので、恐らく家族連れやトラックドライバーをターゲットにしているのだろう。パチスロはドライバーっぽい人らが遊んでるのを見た。
パチスロは結構な台数があり、設定変更できる機種も存在した。コントロールパネルがかわいい。
プライズの中身は怪しいグッズから、そこら辺の商業施設にありそうなものまで結構幅広くあった。
また自販機では軒並新札が使えなかったが、ゲームコーナーの両替機が新札対応だったので、ここで新札を崩すことで使うことができた。
大浴場の前にはシャワー占有状況を示す謎のテクノロジーがあり、昭和を感じられた。これは大浴場のシャワーではなく、大浴場の向かいにあるシャワールームのものと思われる。
大浴場にはよくある暖簾が掛けてあったが、天井からハンガーが生えてる光景が、周りの風景からすると余りにも場違いで、ちょっとおもしろいなと思った。
ひとしきり見た後は床につき、5時ごろに船内放送で起こされた。ちなみにこの放送23時くらいまであるので、気にしてると6時間くらいしか寝れない。そもそも朝食の営業が7時までなので早起きは必須だが…。
まだ薄暗い船外。
朝食。船を降りて飯屋を探したり移動するのは手間なので船の中で食べられるのは非常に効率的だ。
メインディッシュは鮭の塩焼きとだし巻き、サラダに納豆、梅干し、鯛みそ?だった。納豆は食べてないが他はいずれも美味しかった。特にかまぼこは謎のクオリティで、たぶん結構高い奴だと思う。少なくとも100円とかのかまぼこではない。海苔も西条市にある瀬戸内海苔の製品で愛媛を感じられたのがよかった。
乗船から9時半ほど、長く続いた船旅もここで終わりだ。
大阪の地に足を踏み入れ、まずは帰ってきた感じがするが、来たことがない場所だったので実感は皆無だった。
ボーディングブリッジを歩いていると、可愛いけどここに掲示して大丈夫なのか…?というきわどいキャラクターがいた。流石にこれは攻めすぎでは…w
フェリーターミナルに入るとやたら立派なPORT OF OSAKAに迎えられた。虎柄っぽいのが大阪感を出しているような気がしなくもない。
南港からの帰りはニュートラムという新交通に乗った。ニュートラム的なロゴから昭和のバブルを感じた。多分当時は結構ハイセンスだったのだと思う。
住之江公園で四つ橋線に乗り換え。やっと見慣れた名前が見えてきたが、なんか入り口が軽くホラーでビビった。ゾンビとか出てきそう(
西梅田から阪神梅田に移動してきてやっと見慣れた光景、地元感が出てきた。あとはこのまま電車に揺られながら神戸の自宅に帰って旅を終えた。
12/14に行ったのに記事を出すのが12/23にもなってしまったが、これはちょっと記事を詰め込みすぎて伸ばしすぎてしまったと思う。後悔はしていない。
そしてがんばっていきまっしょいをまた見たいので、松山に再度行く計画を立てている。シネマサンシャイン衣山がいつまで上映してくれるのかはわからないが、12/26まではスケジュールが入っているので、このタイミングには見に行きたい。次週になると12月下旬を超え、1月に入ってしまうのでここが最終に見えるが、打ち切る場合は日付を記載しているようなので、いつまでやってくれるのかは果たして謎である。ワンチャン変則的な上映で12/31までやってくれたりして…。
ひとまず年末なので休みを取って聖地巡りをする予定だ。道後温泉も行きたかったが、こちらはいい部屋が埋まっていて取れなかったので、仕方なくビジホをとることにした。食事なしの洋室に泊まるくらいならビジホでよくね?と思ったからだ。旅館は和室で食事付きでなんぼだと思っている。素泊まりで洋室ならビジホでいいっしょみたいな…。
そして運よく「おれんじ おおさか」の便も取れたので、パネルが見れることを期待したいが、果たしてその時まであるかどうか…。また最初は帰路を鉄道で想定していた関係で「おれんじ おおさか」の一等室が取れなかったのが悔やまれる。これは鉄道を予約する前にチラ見したときはあったが、鉄道をやめて船に変えようと思ったら消えていた。
ただまぁ巡り合わせというか、不運が重なった結果、送迎バスが満員になっており、東予フェリーターミナルの最寄である壬生川まで鉄道移動することになったため、鉄道も楽しめる結果となったのは僥倖だった。