更新日:2026/06/10 投稿日:2026/06/08
本記事は自宅サーバーに雑に監視を入れた時にやったこと 、先日の自宅サーバー移転に対し追加対応をした の続きである。
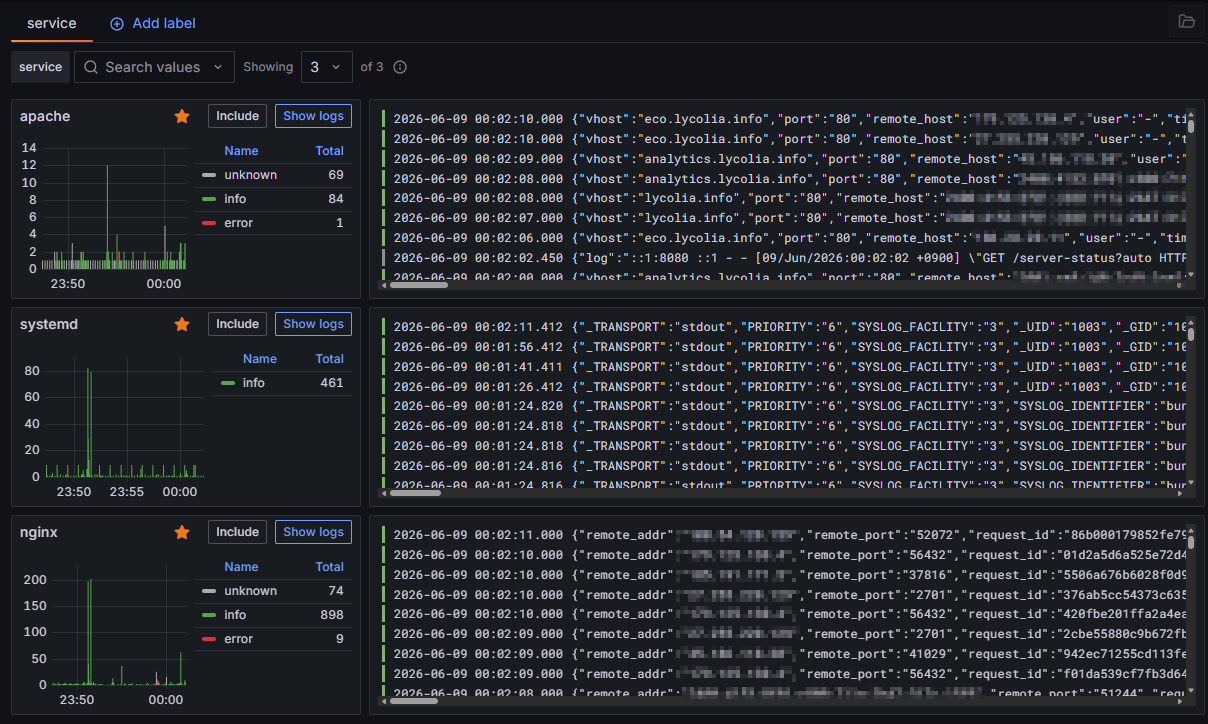
今回はSystemdのログをFluentBitで拾ってLokiに送ってGrafanaで見れるようにしたログ。
AWSやDockerなどを使った情報は散見したが、バイナリをネイティブ環境で動かしている情報や、複数のデーモンのログを収集する方法が見当たらなかったのでちょっと苦労した。GPT-5.5も正確なことを言わないので真面目にリファレンスを読んだりググったりして何とかした。LLM頼みも限度があるね。
Env
Ver
OS
Ubuntu 24.04.4 LTS
Fluent Bit
5.0.6
Loki
3.5.9
Grafana
12.1.1
今回は前回までのconfig設定をYAML設定に全面移行した。基本的にはデフォルトのconfigファイル+私が使っているI/Oの移植である。Lokiの待ち受けポートが9100であると仮定して進める。
各設定については公式マニュアルを参照のこと。
service:
flush: 1
log_level: 'info'
parsers_file: 'parsers.conf'
plugins_file: 'plugins.conf'
storage:
metrics: 'on'
pipeline:
inputs:
- name: 'systemd'
tag: 'systemd'
db: '/var/lib/fluent-bit/systemd.db'
systemd_filter:
- '_SYSTEMD_UNIT=adiary.service'
- '_SYSTEMD_UNIT=mastodon-web.service'
- '_SYSTEMD_UNIT=mastodon-sidekiq.service'
- '_SYSTEMD_UNIT=mastodon-streaming@5001.service'
- name: 'tail'
tag: 'nginx.access'
path: '/var/log/nginx/access.log'
parser: 'json'
db: '/var/lib/fluent-bit/nginx-access.db'
refresh_interval: 5
- name: 'tail'
tag: 'nginx.error'
path: '/var/log/nginx/error.log'
db: '/var/lib/fluent-bit/nginx-error.db'
refresh_interval: 5
- name: 'tail'
tag: 'apache.access'
path: '/var/log/apache2/access.log'
parser: 'apache2_vhost'
db: '/var/lib/fluent-bit/apache_access.db'
refresh_interval: 5
- name: 'tail'
tag: 'apache.error'
path: '/var/log/apache2/error.log'
db: '/var/lib/fluent-bit/apache_error.db'
refresh_interval: 5
outputs:
- name: 'loki'
match: 'systemd'
host: '::1'
port: 9100
labels: 'job=systemd'
- name: 'loki'
match: 'nginx.*'
host: '::1'
port: 9100
labels: 'job=nginx, log_type=$TAG[1]'
- name: 'loki'
match: 'apache.*'
host: '::1'
port: 9100
labels: 'job=apache, log_type=$TAG[1]'
前回の記事で作った 以下のパーサーを利用している。
[PARSER]
Name apache2_vhost
Format regex
^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$
Regex ^(?<vhost>[^:]+):(?<port>\d+) (?<remote_host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
Time_Keep On
また前回の記事で作成したapache_errorというパーサーについては役に立たなかったので使わなくなった。標準で付いてるapache_errorも使えないし、apache2もイマイチ使えないので公式のパーサーは当てにしないほうがいいのかもしれない。
なおパーサーは旧config形式で記述している。これはとてもじゃないが書き換えてられないボリュームだったのとYAMLに対応させようとするとエスケープがだるそうだったからだ。config形式は今年でサポート外になるようだが、既存の設定のプリセットはすべてconfig形式でしか存在しないため、何とも先行きが心配だ。
設定を.confで読んでいるので、ここを.yamlに変えてやる。
[Unit]
Description=Fluent Bit
Documentation=https://docs.fluentbit.io/manual/
Requires=network.target
After=network.target
[Service]
Type=simple
EnvironmentFile=-/etc/sysconfig/fluent-bit
EnvironmentFile=-/etc/default/fluent-bit
+ExecStart=/opt/fluent-bit/bin/fluent-bit -c /etc/fluent-bit/fluent-bit.yaml
-ExecStart=/opt/fluent-bit/bin/fluent-bit -c //etc/fluent-bit/fluent-bit.conf
Restart=always
[Install]
WantedBy=multi-user.target
インストールした当時は何故YAMLで書いても読んでくれないのか悩んでいたが、こんなところで指定されていた。しかも何故かパスが二重スラッシュになっていたので、そこも直しておいた。
以下のコマンドを流すと動いているかどうかが分かる。なんかログが取れてなさそうだったり、Lokiに届いてなさそうなときに使える。
/opt/fluent-bit/bin/fluent-bit -i systemd \
-p systemd_filter=_SYSTEMD_UNIT=mastodon-web.service \
-p tag='host.*' \
-o stdout
なんか最近のソフトウェアのマニュアルって論理的に書かれすぎてて具体的にどう設定したらいいのかよくわからなくて困る。もう少し具体的な設定例とか書いてくれてもいいと思うんだ。
YAML configuration files are the standard configuration format as of Fluent Bit v3.2. They use the .yaml file extension.
Classic configuration files will be deprecated at the end of 2026. They use the .conf file extension.
しかしconfigは今年末でサポート外になる という話があるのにGitHubのリポジトリの設定ファイルは全部configで、果たしてこんなので大丈夫なのか…とIssueを眺めていたら、そもそも開発側もYAMLの仕様を余り解ってないような空気を感じたので、これは今年中は厳しいのではないか?という感じがした。
ひとまず私はキー名がkebab-caseからcamelCaseになってもすぐ対応できるようにメインの設定だけYAMLにしておいたが、Parserを直すのはエスケープが面倒などもあると思うので、なかなか大変だと思う。
あと個人的に不思議に思った部分としてoutputsのlabelsが配列ではなく、文字列だというところだ。
pipeline:
outputs:
- name: loki
match: '*'
labels: job=fluentbit, mystream=$sub['stream']
何でここは配列にしなかったのだろうか?
実際に以下の記述でラベルが機能しているので、おそらくこの構文がFluentBitのDSLとして機能していて、真面目に配列すると改修が大変とか、そういうのがあるのかもしれないなとは思った。
- name: loki
match: 'apache.*'
host: '::1'
port: 9100
labels: 'job=apache, log_type=$TAG[1]'
ちなみに一番ハマったのはブログ執筆用に作っていたLokiのポートを書き換えたメモを基に作業していて、未来永劫FluentBitがLokiに疎通しなかったことである。