2025/09/10(水)マシンを更新したのでローカルLLMを軽くベンチマークしてみた
更新日:
投稿日:
投稿日:
久々にPC構成を大刷新してから三ヶ月ほど経過しているが、ローカルLLMを叩いたときのパフォーマンスが前回と比べてどれほど上がるか計測してみた。
環境の現新比較
| デバイス | 前回 | 今回 |
|---|---|---|
| CPU | Intel Core i7 13700 | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti |
| MEM | Crucial Ballistix BL2K16G32C16U4B(DDR4-3200 16GB) * 4 | Crucial CT2K16G56C46U5(DDR5-5600 16GB) * 4 |
| M/B | ASUS TUF GAMING Z790-PLUS D4 | ASRock Z890 Pro RS |
確認環境
実行環境はWindows 11。
| Env | Ver |
|---|---|
| ollama | 0.15.2 |
| Open WebUI | 0.6.42 |
ベンチマーク結果
前回はストップウォッチで計測していたが、今回はOpenWebUIのメタ情報から確認した。
gpt-oss:20b

| 指標 | 値 |
|---|---|
| response_token/s | 120.74 |
| prompt_token/s | 255.92 |
| total_duration | 22796593800 |
| load_duration | 11155098300 |
| prompt_eval_count | 73 |
| prompt_tokens | 73 |
| prompt_eval_duration | 285245200 |
| eval_count | 1371 |
| completion_tokens | 1371 |
| eval_duration | 11355103800 |
| approximate_total | 22s |
| total_tokens | 1444 |
今回新規で追加。なんかこいつが標準っぽいので測ってみた。
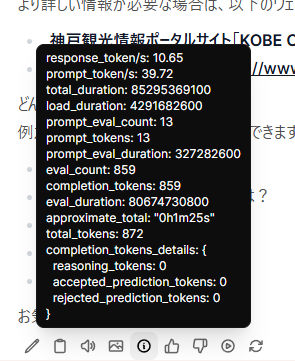
gemma3:27b

| 指標 | 値 |
|---|---|
| response_token/s | 10.65 |
| prompt_token/s | 39.72 |
| total_duration | 85295369100 |
| load_duration | 4291682600 |
| prompt_eval_count | 13 |
| prompt_tokens | 13 |
| prompt_eval_duration | 327282600 |
| eval_count | 859 |
| completion_tokens | 859 |
| eval_duration | 80674730800 |
| approximate_total | 1m25s |
| total_tokens | 872 |
前回は出力に3分半程度かかっていたが、今回は一分半程度と、良好な結果となった。
lucas2024/mistral-nemo-japanese-instruct-2408:q8_0

| 指標 | 値 |
|---|---|
| response_token/s | 51.88 |
| prompt_token/s | 127.3 |
| total_duration | 14512642900 |
| load_duration | 2966192400 |
| prompt_eval_count | 17 |
| prompt_tokens | 17 |
| prompt_eval_duration | 133547400 |
| eval_count | 592 |
| completion_tokens | 592 |
| eval_duration | 11411474600 |
| approximate_total | 14s |
| total_tokens | 609 |
前回は出力に1分程度かかっていたが、今回は14秒程度と、非常に良好な結果となった。
qwen3:30b

| 指標 | 値 |
|---|---|
| response_token/s | 27.49 |
| prompt_token/s | 57.74 |
| total_duration | 134732866900 |
| load_duration | 64763725000 |
| prompt_eval_count | 14 |
| prompt_tokens | 14 |
| prompt_eval_duration | 242451700 |
| eval_count | 1917 |
| completion_tokens | 1917 |
| eval_duration | 69724445400 |
| approximate_total | 2m14s |
今回新規で追加。悪くない品質で、そこそこ早いのでこれは良さそうだ。
qwen3:32b

| 指標 | 値 |
|---|---|
| response_token/s | 5.66 |
| prompt_token/s | 18.49 |
| total_duration | 332234237600 |
| load_duration | 9168679700 |
| prompt_eval_count | 14 |
| prompt_tokens | 14 |
| prompt_eval_duration | 757307500 |
| eval_count | 1823 |
| completion_tokens | 1823 |
| eval_duration | 322305287600 |
| approximate_total | 5m32s |
| total_tokens | 1837 |
今回新規で追加。流石に秒間5.66トークンは厳しい。
雑感
前回と比べるとかなり高速化されており、生成速度だけを見れば十分実用ラインに上がっていているように感じた。しかし回答の品質がそこまでよくなく、そのままでは使えないと感じた。恐らくRAGなどとして使えるようにカスタムしてやっと使えてくるみたいなところがあるのだろうか?
実用性で見ると、日本語文書作成ではgemma3:27bが一番よさそうに思えた。これはqwen3シリーズは単純な質問では結構いい感じなのだが、複雑な条件を付けると期待通りの結果を出してくれなかったからだ。lucas2024/mistral-nemo-japanese-instruct-2408:q8_0も、一見よさそうに見えるがよろしくない発言はできないように細工されているようで、微妙に感じた。
何はともあれ、現実的な速度でローカルLLMが動くようになったのはうれしい。