2025/06/04(水)ローカルLLMとチャットする環境を作ってみた
投稿日:
Open WebUIを使ってローカルLLMとチャットしてみたのでその記録。
確認環境
実行環境はWindows 11。
| Env | Ver |
|---|---|
| ollama | 0.9.0 |
| Open WebUI | 0.6.6 |
やり方
Open WebUIをセットアップ済みという前提で進める。
- Ollamaをインストールする
- 使いたいモデルを探す
ollama pull <モデル名>でモデルを取得する- 物次第だが数~数十GB程度ある
- Open WebUIを起動する
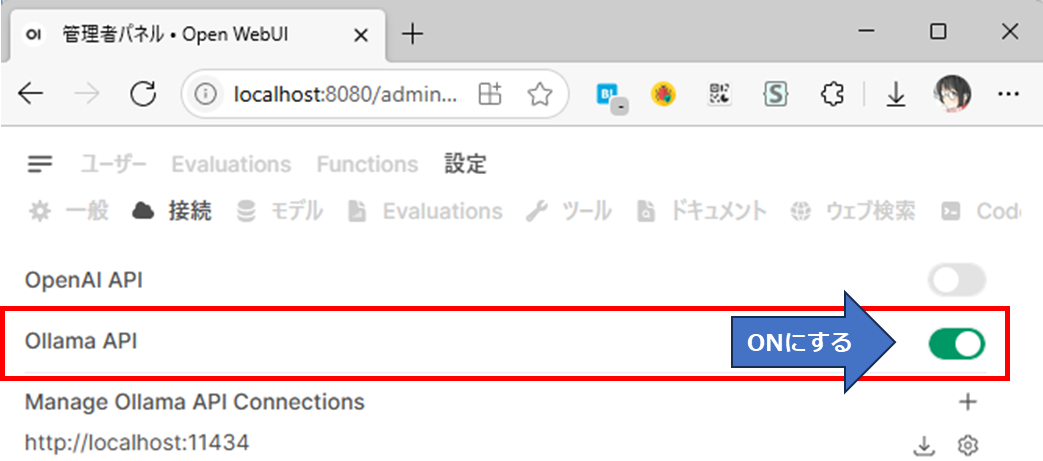
- 管理者設定の接続を開きOllamaをONにする(デフォルトはONのはず)
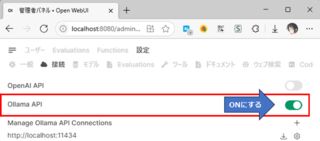
- 管理者設定のモデルを開き、pullしてきたモデルを有効化する
Ollamaサーバーの起動方法
Ollamaをインストールした直後はOllamaサーバーが勝手に起動するが、それ以降は手動で起動する必要がある。
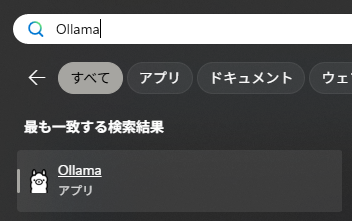
Windowsの場合スタートメニューから起動できる。Ollamaサーバーが起動していない場合、LLMとして使えないので注意。
所感
Intel Core i7 13700 + GeForce RTX 4070 Ti程度の環境では生成速度の遅さゆえに到底実用に耐えるものではなかった。質問への回答品質もあまりよくなく、実用性は疑問だ。チューニングすれば使えるのかもしれないが、よくわかっていない。
今回試した結果ではRPはGemini以上に破綻するので微妙だった。文章をある程度整理する力はある様に見えるので、用途次第では活路があるのかもしれない。
以下に実行した結果を記録している。
gemma3:27b
恐らくGoogle AI Studioにもいる子。
出力内容

真贋のほどはさておき、中々力の入った文章を出してくる。流石にローカルLLMの中でも注目されているモデルだけある。
しかし出力に3分半程度もかかっており、まったく実用性がない。無料の選択肢という意味ではGeminiやCopilotを使ったほうが遥かによいだろう。
マシン負荷
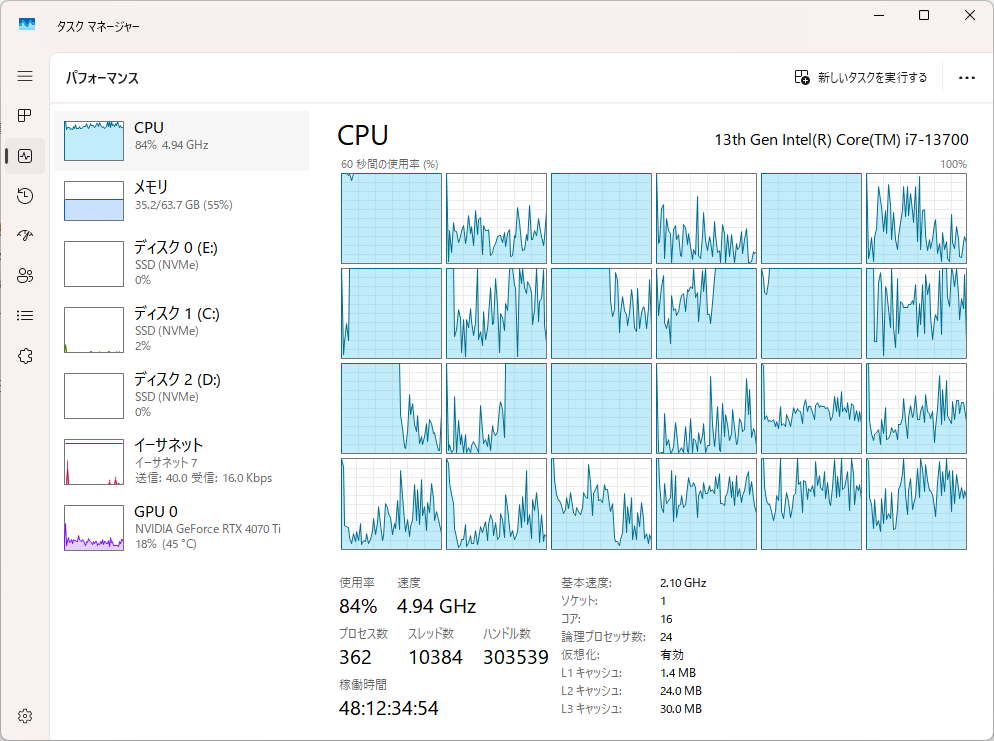
GPU負荷はないもののCPU負荷が強い。VRAMが足りないとCPUで処理するみたいな情報をチラッと見たのでグラボの性能不足の可能性もある。
lucas2024/mistral-nemo-japanese-instruct-2408:q8_0
CyberAgentが作ったとされているモデルのOllama版?
出力内容

こちらも真贋のほどはさておき、中々いい感じの文章を出してくれる。
生成速度はgemma3:27bよりは早いものの、それでも1分ほどかかっていた。
マシン負荷

CPU負荷はgemma3:27bよりやや低く、GPU負荷が少し上がる傾向があった。
マシン負荷


うちのマシンは200mmファンを四基、CPUにはNoctuaのヒートシンクに120mmファン、リアには140mmファンを装備しているが、gemma3:27bだとこれらがフル回転するので凄まじかった。
StableDiffusionやFF14ベンチ程度ではフル回転することはない。