2025/05/16(金)Open WebUIでGeminiを使えるようにした
適当にググって見つかる記事が軒並み古くアテにならなかったのでやれるようにした記録として残す。
AI StudioのUIだと再生成時に前の内容が上書きされてツリーが作れないとか、モデレーションが厳しいとかあるのでOpen WebUIから扱えると何かと便利だ。
確認環境
| Env | Ver |
|---|---|
| Open WebUI | v0.6.6 |
手順
- Open WebUIを起動する
- 管理者設定→FunctuonsからFunctionの追加画面を開く
- gemini_manifold.pyのコードを貼り付けて保存する
- 本家と比較した場合、Function IDの文字列が作者の予期しない内容の時にError: Invalid model name formatが出ないように調整している
- 追加したFunctionの設定(歯車アイコン、Valves)にAPIキーを入れて保存
- モデル一覧にGeminiが出ていればOK
GeminiのAPIキーの作り方
Get API key | Google AI Studioを開きAPIキーを作成する。
画像も生成したい場合
このFunctionでは画像が生成できないので画像を生成したい場合はgemini_manifold_google_genaiを使うといい。ただこっちだとLLMが使えなかった。
またsafety_settingsを外すための設定がないため、モデレーションを回避するためには恐らくコードを書き換える必要があるが確認できていない。
おすすめの設定
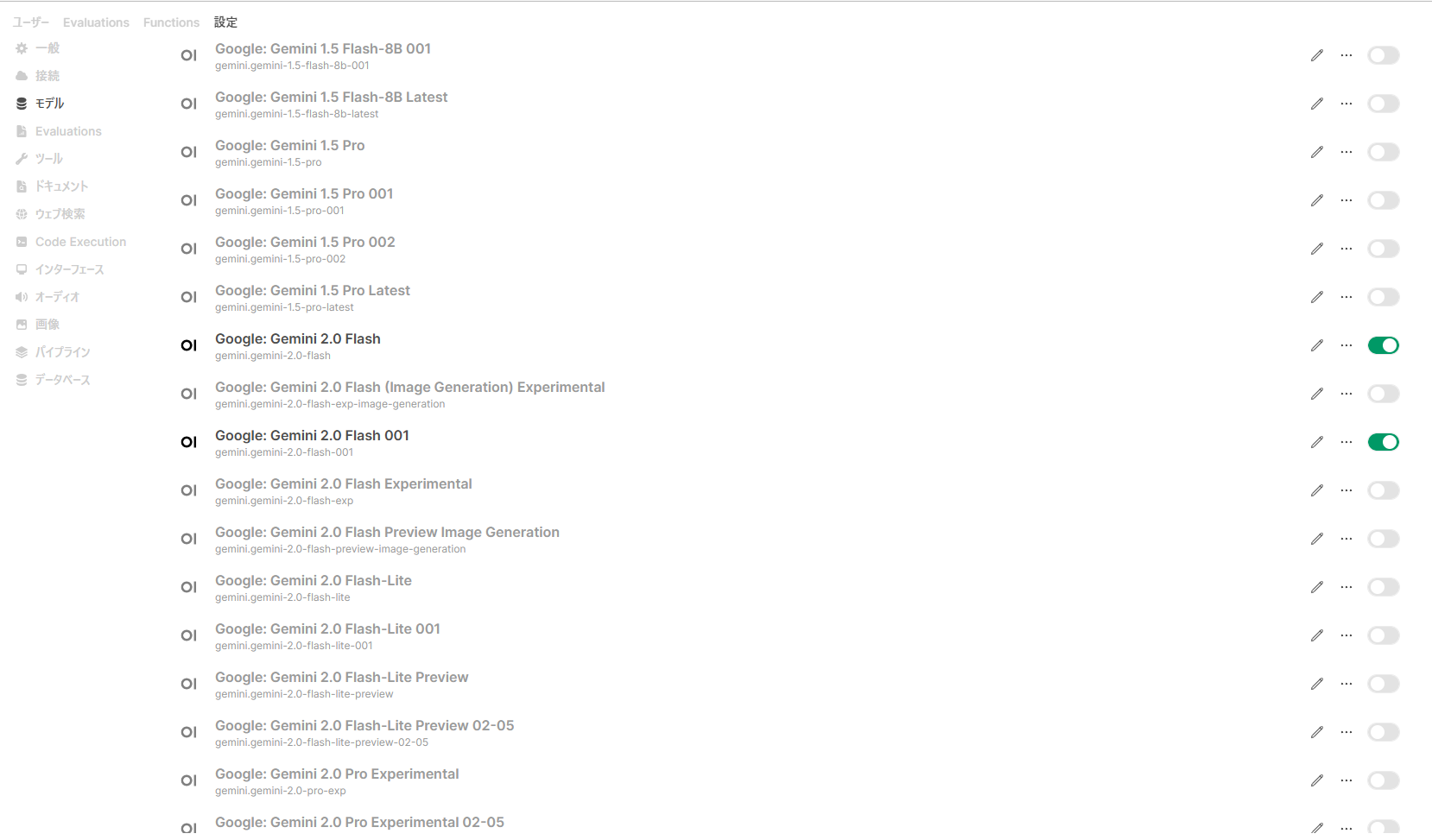
モデルの数が多すぎるので管理者設定にあるモデルを開き、使わないのはOFFにしておくとよい。
レートリミット緩和
そのままだとすぐレートリミットに引っかかるが、請求情報を紐づけると緩和できる。参考までに20k Tokens叩いた程度だと課金されなかった。
ClaudeやChatGPTと異なり従量課金に見えるため、Cloud Billingで予算アラートをしておくのが無難だ。
備考
条件はよくわかっていないが上記の手順で書いたFunctionを利用してNSFWコンテンツを生成するとGemini API側が応答の途中で何も返さなくなることがあることを確認している。この場合、続きを生成すると書いてくれることがあるが、書いてくれないこともある。また続きを書こうとしたときに現在の文章が破壊されることがあるのでバックアップを取って後で整理しなおすなど注意が必要。
LLMのやつに画像生成のやつをマージしてやれば全体的にいい感じになりそうだが、個人的にはStableDiffusionで事足りてるのでモチベーションは薄い。ついでに暇な人は画像生成のやつのsafety_settingsもいじればモデレーションを超えられるかもしれない。機能するかは確認していないが、この辺りが参考になりそうだ。