最近二つほどツールを作り、Webツール置き場 に配置したので、そこで得た学びや、作る時に意識したことについても書いてゆく。
まずENV Checker を作った話。
端的に言うとCyberSyndrome : ENV Checker - 環境変数チェッカー のパクリである。但しJSがないと動かない。
違いとしてはCyberSyndrome側で見れる情報のうち、ユーザー環境に起因しない情報を大幅に削り、ユーザー環境をメインに出せるようにしているほか、IPv4とIPv6の表示にも対応している。
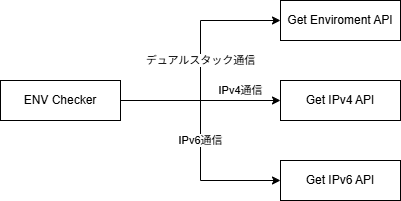
作りとしては必要な情報を返すAPIを3つ用意し、ページを表示したときにJSがそれぞれを叩きに行き、その結果を表示している。
Get Enviroment APIはIPアドレス以外の環境変数を返却するもので、Get IPv4 APIはIPv4アドレスとホスト名、Get IPv6 APIはIPv6アドレスを返すように作ってある。
なぜこの様な分け方にしたかというと、Get Enviroment APIはIPのバージョンを問わない情報しか返さないが、IPアドレスまで返すようにするとIPv4に付随する情報やIPv6アドレスを返すことになるため処理が煩雑になる。
これは実装としてはCGIの環境変数をそのまま返しているのでREMOTE_ADDRに:が含まれているかどうかを見てIPv4か、IPv6かを振り分ける処理が必要になるからだ。
一方でGet Enviroment APIが環境変数だけを返すことに専念できるのならば、IPv4に付随する情報はGet IPv4 APIを叩けば取れるし、IPv6はGet IPv6 APIを叩けば取れるため、分岐処理が不要になる。
これによって各APIは単一の責務だけを持つことになり、コードの複雑化を回避できるといった寸法だ。この程度のシンプルな実装に求めることではないし、現状では無価値ではあるのだが、常日頃から意識することで、より複雑なものを作る時にも生かせるだろうし、将来何か改修するときにも作りが単純なほうが理解しやすいと思うので、こうしている。
IPv4とIPv6のAPIをどう分けているかというと、これはDNSレベルで解決している。Get IPv4 APIのエンドポイントにはAレコードのみを、Get IPv6 APIのエンドポイントにはAAAAレコードのみを設定することで、クライアントが接続する際に使用するIPバージョンを強制している。
こうすることで、各APIは単純にREMOTE_ADDRをそのまま返すだけでよくなり、IPバージョンの判定ロジックを一切持たなくて済むのが利点だ。欠点としてはAPIの数が一つ増えるため、管理コストは増えているといえるだろう。しかし分岐ロジックというのは往々にしてバグを生む存在であり、ないに越したことはないと思い、こういう設計にした。
また画面の描画をJavaScriptにさせているのも、こういったいわゆる関心の分離の思想によるところが大きい。やろうと思えばIPアドレス以外はCGIで表示して、IPアドレスのところだけをJSで書き換えることも、当然できる。出来るのだが、責務を分けるにはデータを返すだけのエンドポイントと、それを受けてJSで書き換える手法のほうが、より責務がはっきりしていて、わかりやすいのでこうしている。疎結合ということでもある。
項目値をダブルクリック・タップすることで値をコピーできるようにしているのも、地味だがこだわりポイントだ。
余談だが、先日Value-DomainでcertbotのDNS Challengeをやるスクリプトを書き直した のは、このドメインにTLS証明書を付与したり、DDNSできるようにする目的があったのが大きい。
というのも、このENV Checkerの開発にはipv4.lycolia.infoとipv6.lycolia.infoというドメインが関係しており、私の自宅サーバーの環境はIPv4がコロコロ変わるためDDNSが必須だった。
私が利用しているDNSレジストラであるValue-DomainはDDNS用のエンドポイントがあるのだが、1回1ドメインしか更新できず、60秒に1度しか叩けないという制約があり、これを回避するためには、Value-DomainのDNS APIに対して、一回で複数ドメインのAレコードを書き換える必要があった。
また同時に、以前使っていた、TLS証明書更新ツールである、value-domain-dns-cert-register (vddcr) はNode.jsのアップデートなどに伴う頻繁なメンテナンスが必要だったり、動作検証不足があったり、様々な面倒ごとがあり、これ以上触りたくなかった 。
そんなこんなの流れがあり、ENV Checkerを作る中でOpenWrtからValue-Domainに複数サブドメインのDDNSを行うツールを作った り、新たなTLS証明書更新ツールを作り、その検証をしたりした のだ。
もう一つはQRコードジェネレーター を作った話。
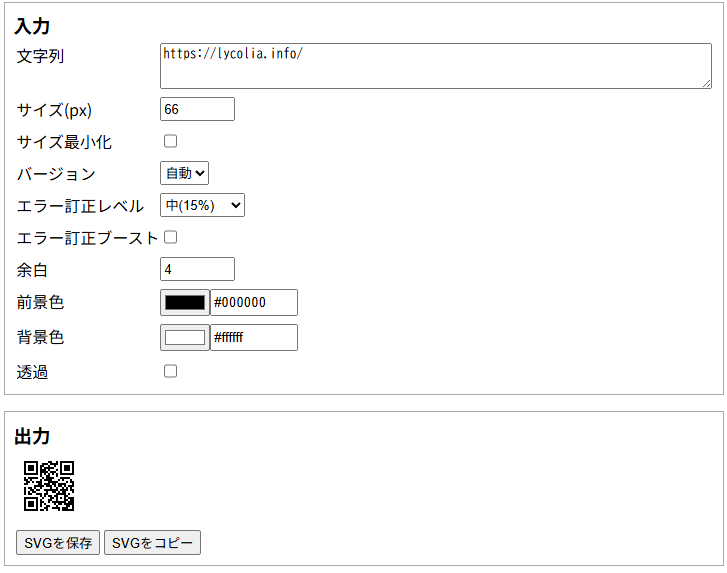
QRコードジェネレーターなどググれば無数に出てくるわけだが、意外と読み取り可能な最小サイズかつ、それをSVGで出力できるものを見つけることができなかった。そこで作ることにした。
とはいえ、作ったのはフロントエンドだけで、QRコードの生成自体はqrcode-svg を使わせてもらっている。これはこのライブラリのデモサイト で、理想の要件のものが作れることが分かったからだ。
なぜデモサイトで使えるのに、わざわざ作ったかだが、まずこのデモサイトでは最小サイズのQRコードを簡単に得ることが困難だったほか、256px以下のサイズにすることが想定されていないように見えたからだ。少なくともUIをクリックしてDIMENSIONを256px未満にしようとしても出来なかった。
また、デモサイトはいつか消える可能性もあるし、ブックマークするのも面倒なので、自分でホスティング出来るなら、それをするに越したことはなかったというのもある。
これを作っている中で得た学びとしては、カラーパレットの入力UIがWeb標準で可能になっていたことだ。そこら中で見かけるし標準であるんちゃうか?と調べたらあったので採用した。こういう複雑なものは昔であれば恐らく何かしらのライブラリを使うか、気合で作る必要があったと思うが、全く世の中は便利になったものだ。
また、こちらの実装方法については、HTMLの標準機能でカラーパレットを使ったカラーコード入力UIを作る方法 の記事で紹介している。
他にもQRコードの周りには余白が必要ということも知れた。QRコードの開発元であるデンソーウェーブでは余白の求め方の計算式 が解説されている。仕様上は適切な余白がない場合、読み込めない可能性があるようだ。これは恐らく周囲の図形とQRコード本体を光学的に分けて認識させるために必要なのだと思う。
なお、今回作成したQRコードジェネレーターには余白の自動調整機能は実装していない。理由は単純でサイズを自由に変えられる仕様上、帳尻をつけるのが面倒だからだ。要は手抜きである。
Webツール置き場 のドメイン配下は元々全てペラのHTMLで実装していたのだが、ページが増えるごとに共通部分のhead要素の管理が煩雑になっていた。そこで、PHPに置き換えることにした。
結果として、以下のように、head要素の中身を共通化することができた。
まぁやっていることとしては高校時代にPHPで静的HTMLの内容を共通化していたのと何ら変わらないので、何故今更そんなことを…という感じだが、元々は静的HTMLで済むものは静的HTMLのほうが表示速度が速くシンプルでよいよなという意図で、静的HTMLにしていたのだが、数が増えてくるとそうも言ってられないということで対応した形だ。こういうのは事前に考慮しすぎると、早すぎる共通化やKISSの法則的なリスクを孕むと思っていて、定期的に振り返り、都度対応するほうが良いと感じている。いや、この程度の内容でそこまで考える必要はないと思うが…w
<!DOCTYPE html>
<html lang="ja">
<head>
- <meta charset='utf-8'>
- <meta http-equiv='X-UA-Compatible' content='IE=edge'>
- <title>Slackのリマインダーコマンドを作るやつ</title>
- <meta name="referrer" content="no-referrer-when-downgrade"/>
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <meta name="author" content="Lycolia Rizzim">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <meta property="og:site_name" content="Lycolia">
- <meta property="og:title" content="Slackのリマインダーコマンドを作るやつ">
- <meta property="og:description" content="必要事項を埋めることでSlackの/remindコマンドを生成するやつ">
- <meta property="og:type" content="website">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <link rel="stylesheet" href="style.css">
- <script src="check.js"></script>
- <!-- Matomo -->
- <script>
- var _paq = window._paq = window._paq || [];
- /* tracker methods like "setCustomDimension" should be called before "trackPageView" */
- _paq.push(['trackPageView']);
- _paq.push(['enableLinkTracking']);
- (function() {
- var u="https://analytics.lycolia.info/";
- _paq.push(['setTrackerUrl', u+'matomo.php']);
- _paq.push(['setSiteId', '3']);
- _paq.push(['enableHeartBeatTimer', 10]);
- var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
- g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
- })();
- </script>
- <!-- End Matomo Code -->
+<?php
+require_once('../template.php');
+
+renderCommonHead(
+ thumbnail: 'https://tool.lycolia.info/slack-remider-creator/OGP.png',
+ title: 'Slackのリマインダーコマンドを作るやつ',
+ description: '必要事項を埋めることでSlackの/remindコマンドを生成するやつ'
+);
+?>
</head>
template.phpの中身
関心ごとに関数を切り分け、呼び出される側は呼び出す側に依存するように設計することで、親が子の変更に引きずられないように保守性を意識した設計にしている。他にもほとんど固定値であるものについては運用を平易にする観点からOptional化して、初期値を設定している。
<?php
function buildMatomo() {
return <<<END
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://analytics.lycolia.info/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '3']);
_paq.push(['enableHeartBeatTimer', 10]);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
END;
}
function buildCommonMeta(string $title, string $thumbnail) {
return <<<END
<meta charset='utf-8'>
<meta http-equiv='X-UA-Compatible' content='IE=edge'>
<title>$title</title>
<meta name="referrer" content="no-referrer-when-downgrade"/>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="author" content="Lycolia Rizzim">
<meta name="thumbnail" content="$thumbnail">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-32x32.png" sizes="32x32">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-192x192.png" sizes="192x192">
<link rel="apple-touch-icon" href="https://lycolia.info/assets/brands/lycolia-180x180.png">
END;
}
function buildOG(
?string $thumbnail,
?string $site_name,
?string $title,
?string $description,
?string $type
) {
$tags = " <meta property=\"og:type\" content=\"$type\">\n";
$tags .= " <meta property=\"og:site_name\" content=\"$site_name\">\n";
if ($thumbnail !== null) {
$tags .= " <meta property=\"og:image\" content=\"$thumbnail\">\n";
}
if ($title !== null) {
$tags .= " <meta property=\"og:title\" content=\"$title\">\n";
}
if ($description !== null) {
$tags .= " <meta property=\"og:description\" content=\"$description\">\n";
}
return $tags;
}
function renderCommonHead(
?string $thumbnail = 'https://lycolia.info/assets/brands/lycolia-OGP.png',
?string $site_name = 'Lycolia.info',
?string $title = null,
?string $description = null,
?string $type = 'website'
) {
$head = buildCommonMeta($title, $thumbnail);
$head .= buildOG(
thumbnail: $thumbnail,
site_name: $site_name,
title: $title,
description: $description,
type: $type
);
$head .= buildMatomo();
echo $head;
}
また他にも、ドメイン直下にあるページの構造を見直した。
具体的にはulとliでリストにしていた部分をdl dt ddに直し、各ツールの内容を少し解りやすくした。ただ余りにも見た目が殺風景すぎるので、liに戻してカードUIをはめ込むようにするかもしれない。
変更前
変更後