検索条件
全6件
(1/2ページ)
公式ドキュメントは読みづらいしLLM本人はまともに説明しないし、ググっても具体的でパッと解る記事が出てこなかったので書く。
| Env | Ver |
|---|---|
| Codex CLI | 0.0140.0 |
| Claude Code | 2.1.179 |
~/.codex/config.tomlを開き、ファイルの最後に以下を追記
[mcp_servers.hoge]
command = "/path/to/some-command"
[mcp_servers.hoge.env]
URL = "https://example.com"
API_KEY = "xxxxxxxxxx"
MCPサーバー名の部分は解りやすい名前を入れておくといい。PukiwikiのMCPならpukiwiki、Redmineならredmineなど。
[mcp_servers.<MCPサーバー名>]
command = "MCPサーバーの起動コマンド"
[mcp_servers.<MCPサーバー名>.env]
このセクションには<KEY> = "<VALUE>"形式で環境変数を列挙する
必要な環境変数がなければ、このセクションは作らなくてよい
~/.claude.jsonを開き、projects."/path/to".mcpServersをこんな感じで書き換える。
"mcpServers": {
"hoge": {
"type": "stdio",
"command": "/path/to/some-command",
"env": {
"URL": "https://example.com",
"API_KEY": "xxxxxxxxxx"
}
}
},
MCPサーバー名の部分は解りやすい名前を入れておくといい。PukiwikiのMCPならpukiwiki、Redmineならredmineなど。
"mcpServers": {
"<MCPサーバー名>": {
"type": "stdio", ← おまじない
"command": "/path/to/some-command", ← MCPサーバーの起動コマンド
"env": { ← ここに環境引数をKEY: VALUE形式で書く。なければこのセクションは不要
"URL": "https://example.com",
"API_KEY": "xxxxxxxxxx"
}
}
},
claude mcp add hoge -- npx -y git@github.com:Hoge/hoge-mcp.git
このコマンドで追加すると、~/.claude.jsonに叩いたカレントディレクトリの設定として以下が追加される。
"mcpServers": {
"hoge": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"git@github.com:Hoge/hoge-mcp.git"
],
"env": {}
}
},
やってることは要するにnpx -y git@github.com:Hoge/hoge-mcp.gitを実行しているだけである。
cd ~
mkdir mcp
cd mcp
git clone git@github.com:Hoge/hoge-mcp.git
cd hoge-mcp
pnpm i && pnpm build
pnpm approve-builds
pnpm build
chmod u+x dist/index.js
使うLLMに応じて設定を行う
Codex
~/.codex/config.tomlを開き、ファイルの最後に以下を追記
[mcp_servers.hoge]
command = "/home/fuga/mcp/hoge-mcp/dist/index.js"
[mcp_servers.hoge.env]
URL = "https://hoge.example.com"
API_KEY = "xxxxxxxxxx"
claude mcp add hoge -- hogeを叩く~/.claude.jsonを開き、先ほど叩いたパスのエントリを探し、mcpServersのところを次の形式で書き換える
"mcpServers": {
"hoge": {
"type": "stdio",
"command": "/home/fuga/mcp/hoge-mcp/dist/index.js",
"env": {
"URL": "https://hoge.example.com",
"API_KEY": "xxxxxxxxxx"
}
}
},
基本的にLLMが勝手にコールするので意識しなくてよい。
まずはMCPサーバーそのものを単純に起動できるか確認する。
叩き方としてはcommandに書いてあるコマンドを叩けばよい。argsやenvがある場合は引数や環境変数も設定する。
そうすれば実行権限がないとか、参照するファイルが足りないとか、何かしらエラーが出るはずなので、それで確認すればよい。
なんでたったこれほどのことなのに驚くほど情報がないのだろう?みんな脳死でLLMを叩いて意味も理解しないまま使っているのだろうか…。
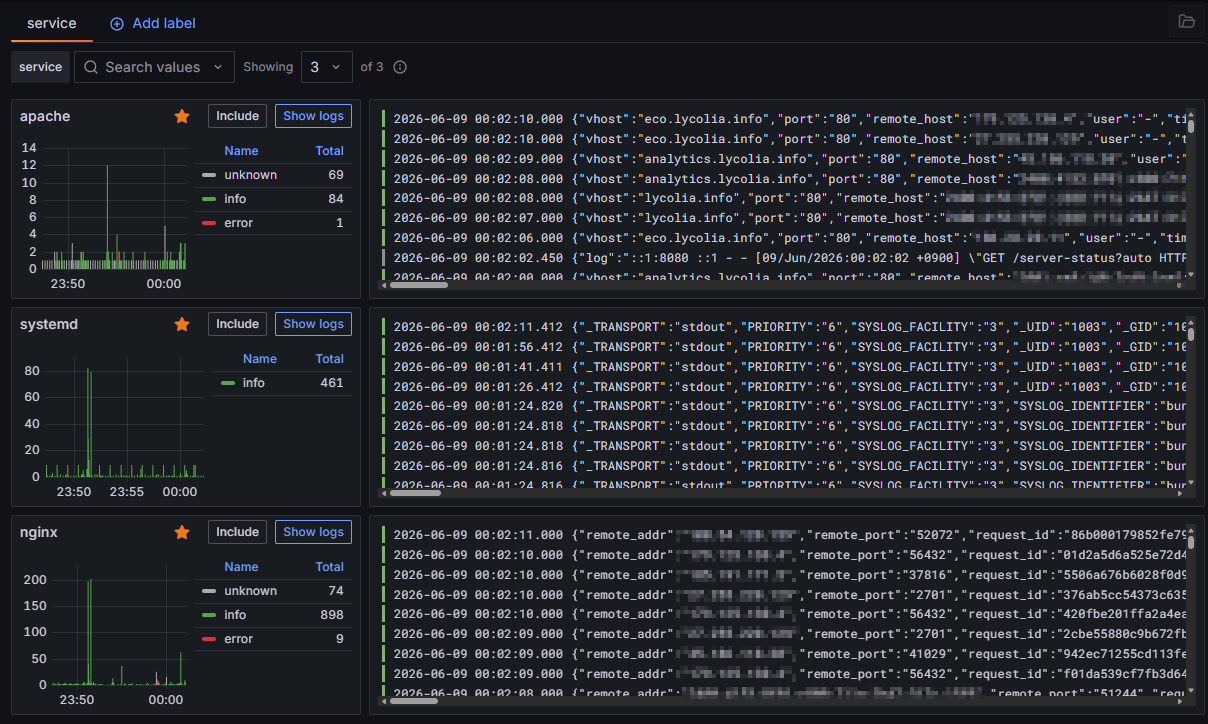
本記事は自宅サーバーに雑に監視を入れた時にやったこと、先日の自宅サーバー移転に対し追加対応をしたの続きである。
今回はSystemdのログをFluentBitで拾ってLokiに送ってGrafanaで見れるようにしたログ。
AWSやDockerなどを使った情報は散見したが、バイナリをネイティブ環境で動かしている情報や、複数のデーモンのログを収集する方法が見当たらなかったのでちょっと苦労した。GPT-5.5も正確なことを言わないので真面目にリファレンスを読んだりググったりして何とかした。LLM頼みも限度があるね。
| Env | Ver |
|---|---|
| OS | Ubuntu 24.04.4 LTS |
| Fluent Bit | 5.0.6 |
| Loki | 3.5.9 |
| Grafana | 12.1.1 |
今回は前回までのconfig設定をYAML設定に全面移行した。基本的にはデフォルトのconfigファイル+私が使っているI/Oの移植である。Lokiの待ち受けポートが9100であると仮定して進める。
各設定については公式マニュアルを参照のこと。
service → Service | Fluent Bit: Official Manualstorage → Storage configuration | Service | Fluent Bit: Official Manual
systemd → Systemd | Fluent Bit: Official Manual
systemd_filterを複数設定する方法は記載がないが、配列にすればよいservice:
flush: 1
log_level: 'info'
parsers_file: 'parsers.conf'
plugins_file: 'plugins.conf'
storage:
metrics: 'on'
pipeline:
inputs:
- name: 'systemd'
tag: 'systemd'
db: '/var/lib/fluent-bit/systemd.db'
systemd_filter:
- '_SYSTEMD_UNIT=adiary.service'
- '_SYSTEMD_UNIT=mastodon-web.service'
- '_SYSTEMD_UNIT=mastodon-sidekiq.service'
- '_SYSTEMD_UNIT=mastodon-streaming@5001.service'
- name: 'tail'
tag: 'nginx.access'
path: '/var/log/nginx/access.log'
parser: 'json'
db: '/var/lib/fluent-bit/nginx-access.db'
refresh_interval: 5
- name: 'tail'
tag: 'nginx.error'
path: '/var/log/nginx/error.log'
db: '/var/lib/fluent-bit/nginx-error.db'
refresh_interval: 5
- name: 'tail'
tag: 'apache.access'
path: '/var/log/apache2/access.log'
parser: 'apache2_vhost'
db: '/var/lib/fluent-bit/apache_access.db'
refresh_interval: 5
- name: 'tail'
tag: 'apache.error'
path: '/var/log/apache2/error.log'
db: '/var/lib/fluent-bit/apache_error.db'
refresh_interval: 5
outputs:
- name: 'loki'
match: 'systemd'
host: '::1'
port: 9100
labels: 'job=systemd'
- name: 'loki'
match: 'nginx.*'
host: '::1'
port: 9100
labels: 'job=nginx, log_type=$TAG[1]'
- name: 'loki'
match: 'apache.*'
host: '::1'
port: 9100
labels: 'job=apache, log_type=$TAG[1]'
前回の記事で作った以下のパーサーを利用している。
[PARSER]
Name apache2_vhost
Format regex
^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")?$
Regex ^(?<vhost>[^:]+):(?<port>\d+) (?<remote_host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
Time_Keep On
また前回の記事で作成したapache_errorというパーサーについては役に立たなかったので使わなくなった。標準で付いてるapache_errorも使えないし、apache2もイマイチ使えないので公式のパーサーは当てにしないほうがいいのかもしれない。
なおパーサーは旧config形式で記述している。これはとてもじゃないが書き換えてられないボリュームだったのとYAMLに対応させようとするとエスケープがだるそうだったからだ。config形式は今年でサポート外になるようだが、既存の設定のプリセットはすべてconfig形式でしか存在しないため、何とも先行きが心配だ。
設定を.confで読んでいるので、ここを.yamlに変えてやる。
[Unit]
Description=Fluent Bit
Documentation=https://docs.fluentbit.io/manual/
Requires=network.target
After=network.target
[Service]
Type=simple
EnvironmentFile=-/etc/sysconfig/fluent-bit
EnvironmentFile=-/etc/default/fluent-bit
+ExecStart=/opt/fluent-bit/bin/fluent-bit -c /etc/fluent-bit/fluent-bit.yaml
-ExecStart=/opt/fluent-bit/bin/fluent-bit -c //etc/fluent-bit/fluent-bit.conf
Restart=always
[Install]
WantedBy=multi-user.target
インストールした当時は何故YAMLで書いても読んでくれないのか悩んでいたが、こんなところで指定されていた。しかも何故かパスが二重スラッシュになっていたので、そこも直しておいた。
以下のコマンドを流すと動いているかどうかが分かる。なんかログが取れてなさそうだったり、Lokiに届いてなさそうなときに使える。
/opt/fluent-bit/bin/fluent-bit -i systemd \
-p systemd_filter=_SYSTEMD_UNIT=mastodon-web.service \
-p tag='host.*' \
-o stdout
なんか最近のソフトウェアのマニュアルって論理的に書かれすぎてて具体的にどう設定したらいいのかよくわからなくて困る。もう少し具体的な設定例とか書いてくれてもいいと思うんだ。
YAML configuration files are the standard configuration format as of Fluent Bit v3.2. They use the .yaml file extension.
Classic configuration files will be deprecated at the end of 2026. They use the .conf file extension.
しかしconfigは今年末でサポート外になるという話があるのにGitHubのリポジトリの設定ファイルは全部configで、果たしてこんなので大丈夫なのか…とIssueを眺めていたら、そもそも開発側もYAMLの仕様を余り解ってないような空気を感じたので、これは今年中は厳しいのではないか?という感じがした。
ひとまず私はキー名がkebab-caseからcamelCaseになってもすぐ対応できるようにメインの設定だけYAMLにしておいたが、Parserを直すのはエスケープが面倒などもあると思うので、なかなか大変だと思う。
あと個人的に不思議に思った部分としてoutputsのlabelsが配列ではなく、文字列だというところだ。
pipeline:
outputs:
- name: loki
match: '*'
labels: job=fluentbit, mystream=$sub['stream']
何でここは配列にしなかったのだろうか?
実際に以下の記述でラベルが機能しているので、おそらくこの構文がFluentBitのDSLとして機能していて、真面目に配列すると改修が大変とか、そういうのがあるのかもしれないなとは思った。
- name: loki
match: 'apache.*'
host: '::1'
port: 9100
labels: 'job=apache, log_type=$TAG[1]'
ちなみに一番ハマったのはブログ執筆用に作っていたLokiのポートを書き換えたメモを基に作業していて、未来永劫FluentBitがLokiに疎通しなかったことである。
Chat GPT3.5が出た当初、私は狂ったようにChatGPTを利用していた。レートリミットを無視するために最大13アカウントを並列で運用していたほどだ。
しかしChat GPT-4辺りから雲行きが怪しくなり、GPT-4oで遂にERPが封じられた。そしてそのタイミングでちょうど出てきたのがClaudeだった。
ClaudeはERPができるだけでなく、GPTより性能が良かった。それゆえに私はそれからClaude Opus 4.7に至るまでClaudeを使い続けた。AnthropicにBANされようと、なお使い続けた。
しかしそれに転機が訪れたのがClaude Opus 4.8だった。Opus 4.8でもERPは出来なくはないのだが、よくある同人誌にありがちな奴ができなくなった。いわゆる非実在未成年モノというやつだ。
そして私はClaudeに対して最近良い感情があまりなかった。Claude Codeは余計なことをよく行い、指示を守らない、逸脱するというのが往々にしてあった。私はClaudeに対するコーディング面での信頼を4.7のころから失い始めており、4.8で決定的になった。
この辺りに関しては私より草片きのぽ氏のほうがよく言語化できているので勝手に紹介させていただく。この辺りの感覚は私も共感できる部分がかなりあった。
そこで、ふと思ったのだ。GPTならどうか?私はOpenAIにはBANされてない。ERPしないならGPTでもいいのでは?というところで、一昨日くらいからGPT-5.5がいい感じなので、OpenAIに戻ってくることにした。
Poe経由でClaudeを使うと非常にお金がかかるが、OpenAIに月額課金する場合はそこまでお金はかからない。ERPももう飽きてきたところだったし丁度よかった。
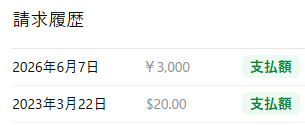
かつて作っていたアカウントの多くは不正利用を恐れて閉鎖しており、同じメールアドレスでアカウントを作れないので困っていたが、かろうじて一匹生きているアカウントを発見したら、なんと三年ぶりの課金であることが判明した。
今のところGPTは支持に従うし、GPT-5の時の様なそっけなさというかイマイチ使えない感じもなくなり、ずいぶんよくなったと思う。ClaudeのようにAI臭さのある文章を出してこないのも個人的に好印象だ。
というわけで、長らく続いたClaude生活から、またGPT生活に戻っていきそうだ。節約にもなるし、これはいいかもしれない。
ところで請求の単位がUSDからJPYになってるのが地味に面白いと思った。

監視対象のスペックを確認するのに便利かも…?
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Prometheus | 3.5.0 |
| Grafana | v12.1.1 |
| Node exporter | 1.9.1 |
次の要領で設定する
| 項目 | 状態 |
|---|---|
| Visualization | Table |
| Table view | ON |
| Queries | Codeを選択しnode_os_info或いはnode_dmi_info |
| Add field override | ボタンを押して一個追加する |
Override 1
| 項目 | 状態 |
|---|---|
| Fields with name | Time |
| Standard options > Display name | Last Synced |
Refreshボタンを押すと完成するのでSave dashboardしたら出てくる
OpenWrtのメトリクスやログをUbuntu側のGrafanaで見れるようにするまで。
メトリクスの取得にはPrometheus、ログはLokiを使っている。
監視する側
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Prometheus | 3.5.0 |
| Grafana | v12.1.1 |
| Loki | 3.5.9 |
監視される側
| Env | Ver |
|---|---|
| OpenWrt | 24.10.0 |
| Prometheus | 3.5.0 |
| prometheus-node-exporter-lua | 2025.07.15-r1 |
| prometheus-node-exporter-lua-nat_traffic | 2025.07.15-r1 |
| prometheus-node-exporter-lua-netstat | 2025.07.15-r1 |
| prometheus-node-exporter-lua-openwrt | 2025.07.15-r1 |
| prometheus-node-exporter-lua-thermal | 2025.07.15-r1 |
| perl | 5.40.0-r2 |
| perlbase-json-pp | 5.40.0-r2 |
| perlbase-http-tiny | 5.40.0-r2 |
| perl-time-moment | 0.44.5.40-r1 |
ほぼOpenWRT | Grafana Labsに書いてある通り。
opkg update
opkg install \
prometheus-node-exporter-lua \
prometheus-node-exporter-lua-nat_traffic \
prometheus-node-exporter-lua-netstat \
prometheus-node-exporter-lua-openwrt \
prometheus-node-exporter-lua-thermal
/etc/config/prometheus-node-exporter-luaを以下のように編集する
config prometheus-node-exporter-lua 'main'
+ option listen_interface 'lan'
- option listen_interface 'loopback'
option listen_port '9100'
#option cert '/etc/uhttpd.crt'
#option key '/etc/uhttpd.key'
/usr/lib/lua/prometheus-collectorsに配置する/etc/init.d/prometheus-node-exporter-lua restart
/etc/prometheus/prometheus.yaml
- job_name: "OpenWRT"
static_configs:
- targets: ['xxxx:xxxx:xxxx:xxxx::1:9100']
sudo systemctl restart prometheus.service
curl 'http://[xxxx:xxxx:xxxx:xxxx::1]:9100/metrics'
18153を取り込む
(
(
(node_memory_SwapTotal_bytes{instance=~"$node:$port",job=~"$job"} - node_memory_SwapFree_bytes{instance=~"$node:$port",job=~"$job"})
/
(node_memory_SwapTotal_bytes{instance=~"$node:$port",job=~"$job"} > 0)
) * 100
)
or
(node_memory_SwapTotal_bytes{instance=~"$node:$port",job=~"$job"} * 0)
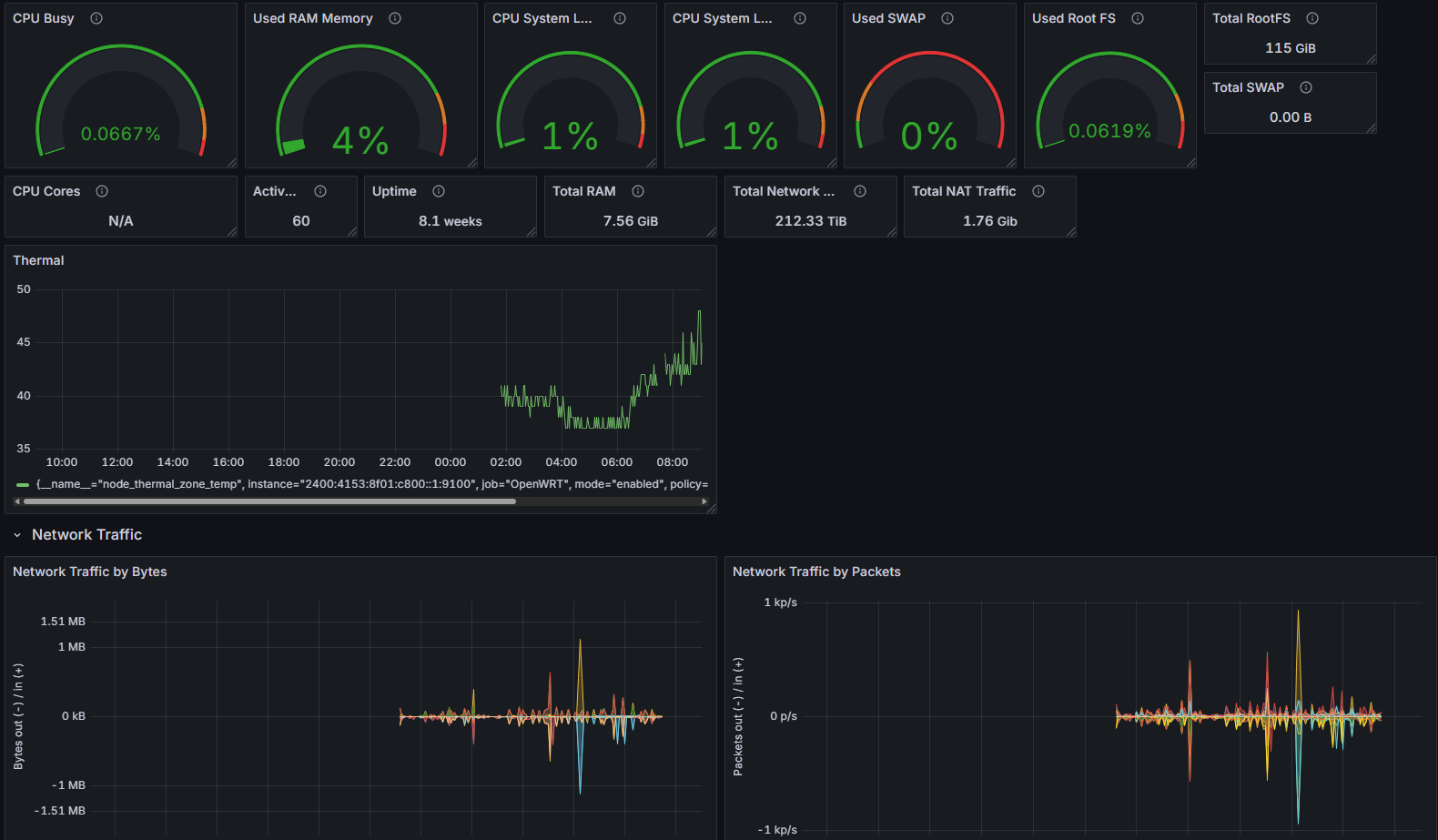
細かい部分の整理はまた追々として、いい感じに見れるようになった気がする。
Loki exporter for OpenWRTが動かないので自作した。
/tmp/openwrt-loki.errの中身を見てエラーがないか見る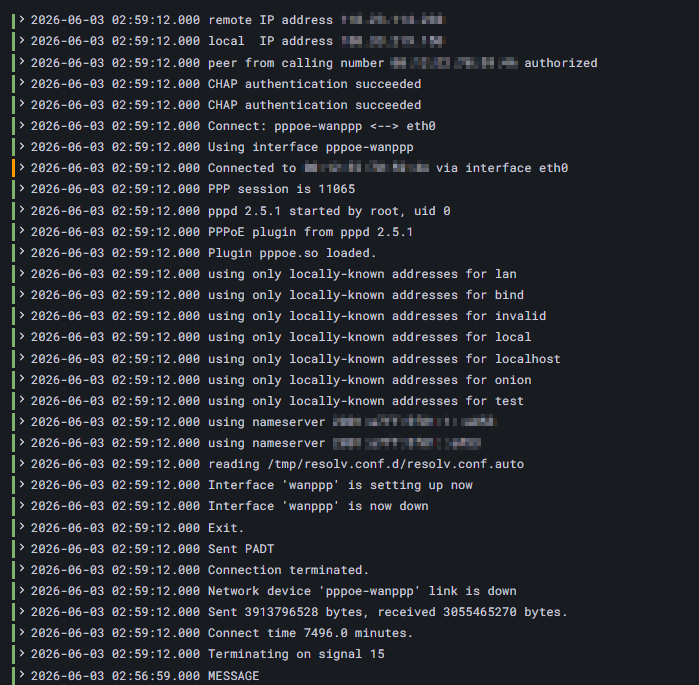
一旦こんな感じで見れるようになった。
親子関係を作ってないせい。Claude Opus 4.8には難しいようだったので、そのうち作る。
POST /loki/api/v1/pushを叩けばよい。ペイロードは以下の書式。
{
"streams": [
{
"stream": {
"label": "value"
},
"values": [
[ "<unix epoch in nanoseconds>", "<log line>", { "hoge": "aaaa", "fuga": "1234" } ],
[ "<unix epoch in nanoseconds>", "<log line>", { "hoge": "bbbb", "fuga": "2345" } ]
]
}
]
}
nginxのログはペイロードしか入ってなかったりするがどうやって実現してるのか不明。もしかするとvalues[1]にJSONを突っ込んでるのかもしれない。
| 項目 | 意味合い |
|---|---|
| streams | よくわかってない |
| stream | この配下に検索用のラベルをぶら下げる。jobとかlevel、hostとかを入れとくとよいと思われる |
| values | ログの本体を入れる |
| values[0] | ナノ秒まで入ったEPOCH |
| values[1] | ログ本文の文字列 |
| values[2] | オプションペイロード。KEY=VALUE |
あのシェルスクリプトを読む気が起きなかったので、なぜこうなっているかはわからない。
BOOT=0 /bin/ash /usr/bin/loki_exporter
openwrt-loki-exporter/v1.0.6-0-gd20fb55-20260322-23413663016 started with BOOT=0
/usr/bin/loki_exporter: line 257: malformed ?: operator
去年の8月にはやろうとしていたものの、そのままズルズルと長らく放置していたOpenWrtの監視周りだが、このままではいけないということで、一旦は雑に整備した。
大変雑なのでログ周りは機能するかも怪しいし、私以外が使えるようにも作ってない。最低限動くとかそんなレベル。LLMが書いたコードもろくにレビューしていないので、動いている原理さえ不明だ。
幸い全部で300行そこらなのでおいおい読んで理解していきたいとは思う。
基本原理はlogread -fした結果をいい感じに取り込んでLokiにたたきつけているだけのはずだが、この「いい感じ」が難しく、重くなっていると考えている。例えばログの取得漏れや、重複取得などを考慮しないといけないので、なんかそこら辺をいい感じにやってもらうようにLLMに指示したら一気に重くなった。ベースのコードは私が書いていたのだが、全くの別物になってしまった。
しかし去年の8月にしかかって放置している部分はできていないので、またそこは追々やっていきたいところだ。具体的には今回の対応はサーバー側でメトリクスを見る対応なのでネットワークが死ぬと終わってしまう。そこでルーター側でも簡易に見れるのを作ろうという計画がある。
しかしルーター側はスペックがしょぼいので大したことはできないし、ストレージがeMMCなので頻繁な書き込みもできないから、普段はメモリストレージ(/tmp)に置いておき、定期的に永続化のためにeMMCに吐き出すというのをやろうとしている。
そしてeMMCに端に吐き出すのもパフォーマンスと寿命の影響があるのでファイルシステムレベルでの対策をしてやろうみたいなことを考えていたが、尻切れとんぼのままなので、何とかしていきたいところだ。