去る6月28日、日曜日のお話。
この日は13時に起床し、なんとなく外出したくなったので福良を検討していたが渦潮クルーズに行くには微妙すぎる時間だったので、淡路島のどこに行こうかなと思って考えていたら、そういえば淡路市に行ったことがないなと思ったので、淡路市に行ってきた話。
淡路島に行くなら鉄板といえる神姫バス三宮BT。バスの入出庫風景が非常に独特でうなぎの寝床ともいわれる場所だ。
ここに入るバスは手前の狭い道からバックで曲がりながら入庫するのだが、前の道がお世辞にも広くないので偶に入庫が上手くいかず何度も切り返しをしているバスを見ることもある[1]
バスターミナルに入ると五色・高田屋嘉兵衛公園行きのバスがちょうど出るところで、悠長に写真を撮影していたら搭乗口の発車案内から消滅したので軽く焦った。
高速バスのところに書かれている「五色・高田屋嘉兵衛公園」「洲本バスセンター」「福良」は全て淡路島行きのバスで、それが三連で、それも30分以内に並んでいることから淡路島行きのバスの多さがよく分かる。実際三宮から淡路島に行くのは簡単で、思い立ったらバスターミナルに行けば行けるレベルだ。
余談だが神戸市内から淡路島に向かうバスは平日の6:55~7:50の55分間が最も本数が集中しており、この時間帯には9本ものバスが存在し、5分に一本出ている。休日にはこれだけの本数が存在しないことから通学・通勤用だと思われる。
休日でも洲本行は毎時2-3本、福良行きは1本程度存在し、他の方面も毎時一本程度はあるので、思いついたら淡路島は意外と簡単だ。
また今回の目的である淡路市は淡路島の入口にあたる地点に存在するため、一部を除いて大抵が止まるためアクセスが容易である。
という訳で無駄に行灯のフォントがかっこいいバスに乗車する。発車一分前。
ニジゲンモリバスがすれ違う地味に貴重なシーンに出会えた。ニジゲンモリは淡路市に存在するテーマパークで、淡路島を代表する大規模観光施設となっている。
ニジゲンノモリの運営は元を辿るとパソナで、パソナは淡路市内で複数の観光施設を運営しており、この関係でパソナが本社事業の一部を淡路島に移したことから、パソナの島と呼ばれるようになった要因の一つとなっている。
生田川出入口から阪神高速に入ったところ。淡路島行きのバスは大体ここから高速に入るが、稀に反対方向の山手方向から行くこともある。
高速に上がってすぐの港。この辺りは倉庫が多いためか、荷役用の船っぽいのがよく見える。
ここはゴルフショップの倉庫と打ちっぱなしが融合してるのが凄いと思う。
上組 のロゴがあるのでずっと上組の施設だと思っていたのだが、調べたところつるやゴルフの施設らしい ?
もしかしたら上組がつるやゴルフに土地と建物を貸しているのかもしれない。
この打ちっぱなしは駐車場に屋根があり、屋根に太陽光パネルが貼ってあるのが合理的だ。車が熱くなるのを防ぎ、ついでに発電もできるというのはいいアイデアだと思う。
ポートアイランドの手前に来ると複数の高架が入り交ざり、入り組んだ光景が垣間見える。目の前の道は二階建てになっていて、下側が西行き、上側が東行きの構造になっている。
この辺りは衛星写真で見るといかに複雑かがよく分かる。
しばらく行くとメリケンパークやポートタワーも見える。
そしてすぐにumieの看板が見え、万葉俱楽部とハーバーランドを過ぎ去る。
この万葉俱楽部は中に映画館があると聞くが、まだ行けていないのでいつか行きたい。偶に万葉倶楽部の温泉輸送車も見るし、家のポストに割引券が入っていることもあるのだが、なんとなく行けていない。
兵庫区感の漂う景色を眺めていると神戸市バスの基地を発見した。
周囲にはデンソーテンやバンドー化学など、重工業の町らしい建物が目立つ。
車窓からの景色はすぐに川崎車両に移り、京阪の車両らしきものが見えた。構内には線路があるのにタイヤを履いていたのでちょっと不思議だなと思った。手前にトレーラーらしき車両が見えるので、ひょっとしたら陸送するために置いているのかもしれない。
川崎車両本社ビルは何度見てもいい感じだ。
須磨の辺りで山が開けるとクレーン船が見えた。この後もう一隻のクレーン船を見ることになるが、どこかで工事した帰りだろうか?
垂水JCTの前に入ると混んできた。
この辺りは山にへばりつく住宅地と明石海峡大橋、そして淡路島が見えて眺望がいい。
垂水JCT内の分岐。改めて考えると淡路島というICや自治体があるわけではないので、淡路島という括りは雑だなと思うものの、直感的で解り易くもあるなと思うなどした。淡路島は淡路島だもの。
垂水JCTは日本最大のジャンクションとして知られており、非常に複雑で迷子になりやすいらしい。このバスは右下から入ってきて左下に出る感じ。
何度見ても神戸淡路鳴門道という全部くっつけましたみたいな道の名前がいい。
ゲートをくぐると事故車両が安置されていた。
三宮を出て初めての停留所、高速舞子に到着した。
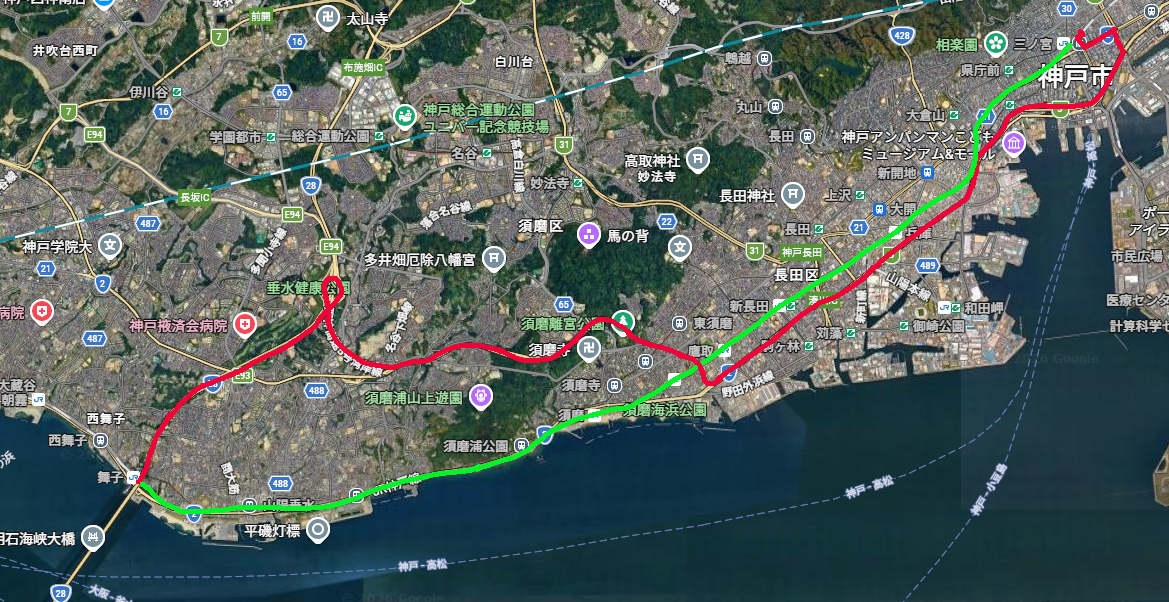
余談だが高速舞子で乗る方が運賃が安く、所要時間も短くなる。理由は単純でバスは三宮を抜けるのに渋滞にハマり、高速道路に乗ってからも山側に大きく迂回するからだ。鉄道に渋滞はないし、海沿いをずっと走るため、明石海峡大橋の付け根にある高速舞子バスストップまでの所要時間が短い。
参考までにバスと鉄道で、三宮から高速舞子までどれだけ差があるか図にしてみた。赤がバス、緑が鉄道だ。これでバスが鉄道に勝つ方が無理である。
但し高速舞子から乗る場合、一度JRに乗り、舞子で下車し、そこから凄く高い場所にある高速舞子バス停まで登らないといけない。エレベーターはあるが面倒である。そもそもバスと接続する鉄道のダイアを調べる時点でもう面倒である。
しかし安くて速い上に、周囲は住宅街なのもあり、ここでの乗客は写真の通り多い。神戸市内発淡路島経由のバスのおおよそ全て、つまり淡路島行きのほかに、徳島、香川、愛媛、高知行きのバスもここに止まる。このため連休の時などは人が柵からあふれかけていたり、バスが本線上で渋滞していたりするので、一種の名所みたいなところだ。
三宮から乗る利点はこの面倒な乗り換えがない点だ。そして高速舞子から乗るということは多客時に乗れない、補助椅子になるリスクも孕んでいる。
因みにこのバス停は乗車専用のため降車できない。更にここを出るとその後のバス停は降車専用になるため、降りる客がいないほどバスが速くなる。ただ台風で無客でもない限りほぼすべてのバス停に止まるため、あまり期待しないほうがいい。
平日で明石海峡大橋封鎖の噂が流れるほどの天気で、淡路島内の企業が出社自粛を出しているときに乗ると三宮→洲本が高速舞子を除いてノンストップになり30分くらい早着することも経験上あったが、まずそんなことはない。
さて、高速舞子を出るとバスはすぐに明石海峡大橋に差し掛かる。ここからはひたすら景色がいいゾーンだ。海を見るとまたクレーン船がいた。さっき見たときから一分しか経っていないため、恐らくさっき見たものと同じ船だろう。
対岸に見えるのが国の海の島として知られる淡路島である。他にも花とミルクの島とか玉ねぎの島とかパソナの島とか様々な異名を持つが、個人的には玉ねぎの島である。
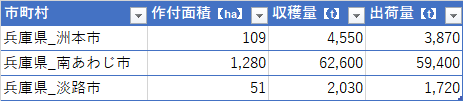
政府統計によると昨年の兵庫県全体での玉ねぎ出荷量は77,600t 、淡路島三市で69,180t ということで、約89%を淡路島が占めている。特に南あわじ市が突出して多い。恐らくこれは淡路島の中でも平野部が多いからだろう。
都道府県別だと4位の長崎が28,500tらしいので、淡路島単体で長崎県の2.4倍ほど作っていることになる。
眼下に垂水の明石海峡大橋関連の観光施設が見える。
海を眺めるだけでいろいろな船が見えて面白い。デカい船が目立つのでプレジャーボートがミニチュアに見えてくる。
陸の方を見ると目的地である淡路市の観覧車が良く見える。ここから向かうのはあの観覧車のある場所だ。
クレーン船に近づいてきたのでズームで撮ってみた。土を積んでいるので浚渫船か何かだろうか?左下の黄色いバケットみたいなやつがかっこいい。たぶんクレーンの先に取り付けて掘るのに使うのだろう。
そしてバスは淡路島に上陸した。橋の上を走っている時間は短いのでつかの間だった。
横の一般道を見ると島なのに自転車レーンが整備されていて驚いた。淡路島にはアワイチと呼ばれる自転車で淡路島を一周する企画があるからかもしれない。
淡路SAの観覧車が近づいてきた。
淡路ICで下車。このバス停は恐らく淡路島の中で最も非島民の降車が多いバス停の一つだと思う。理由として淡路ICバス停は淡路SAに直結しており、淡路SAは観覧車を有するほどに観光地として整備されているほか、ニジゲンノモリの入口にもなっているからだ。
私は淡路島には年数回来ているが、ここで降りるのは初めてだ。十中八九は洲本に行くからだ。一応福良も二度いったことがある。ただ福来行きについては一回は陸の港西淡で係員の人と歓談してたらバスが通り過ぎた結果、未遂に終わっている…。
よって今回が淡路市初上陸となった。
この時刻表を見た感じ、どうやら洲本方面行のバスで淡路ICで客を拾うバスが一日一便だけ設定されているらしい。破れてて読み取れないが、どうも最終的に淡路に戻ってくるように見える。他にも地味に洲本方面行で途中のバス停で客を拾うやつがあるらしい。淡路島内の高速バス停はどれも住宅地から離れた不便な場所にあり、どれほど需要があるのかは謎である。
衛星写真で見ると解るのだが、淡路島内の高速バス停の大半は駐車場を併設しているので、パークアンドライドが基本になっている。これは自家用車で島外に出ようとすると高速代と明石海峡大橋が高く、更に明石や神戸、梅田に出ると駐車場代もかかるため、バスに乗って節約するためだと思う。また島外への通勤通学の場合は定期を使うことで島外にタダで出放題になるのもある。つまり島内を移動するだけなら高速バスを使う意味は薄い。
淡路サービスエリアへはまずこの細い階段を下りていく。知識として知ってはいたが、いざ実物を見るとわくわくしてくる景色だ。
階段を降りると道案内が書いてある。ニジゲンノモリ1,600mは割と気が遠くなる数値だが、無料シャトルバス が運行されているらしいので、これに乗っていくことができるようだ。本数はかなり多い。岩屋港が始発らしいので、明石からジェノバラインを利用していくのも一つだろう。
因みに今回ニジゲンノモリ方面に行っていた人は一人だけに見えた。
ニジゲンノモリ方面。このトンネルを抜けた先に無料送迎バスのバス停があるようだ。
サービスエリア方面。私がまず向かうのはこちら。
トンネルを出ると丁度乗ってきたバスが出発したところだった。
下を見ると明石海峡大橋を描いたマンホールが設置されていた。
前を向くと夢にまで見た観覧車が見えた。いつもここを通るたびに、垂水から淡路島を見るたびに、あのデカい観覧車に乗りたいなぁと思っていたものが、今まさに眼前にある。つまり乗れる!!
もうこの時点でワクワクしてきた。
進んでいくと明石海峡大橋とデカい船が見えた。左手にやたら派手な家が見えるが、これはカフェらしい。
道に北淡運送と大きく書かれたトラックが見えるが、北淡は「ほくだん」と読む。淡路島には北淡(ほくだん)、南淡(なんだん)、西淡(せいだん)という地名があり、これらの「淡」を「だん」を読むのが特徴だ。なお東淡は聞いたことがない。たぶん東は東浦だと思う。
私は西淡という異名を始めて音で効いたとき結構驚いた。
余談だが淡路島は鉄道貨物や運送トラックでよく見るAKC の本社[2]
そんなこんなで観覧車の下に来たが、いったん観覧車を後にして景色を眺めに行く。
山に埋もれた高速道路がいい感じだ。スタジアムの照明みたいなやつは何だろう?
明石海峡大橋が良く見える。夜に着たら絶対に景色がいいやつだ。
手前の港は恐らくジェノバライン が発着する岩屋港だと思われる。
実は明石海峡大橋は夜になるとライトアップされるのだが、私はいつもバスの中から見ており、バスは動いているのでライトアップを撮ろうにも上手く撮れないうえ、そもそもこの瞬間が見えるのが淡路島側からだと一秒もないのである。
恐らく淡路島側からライトアップを見たり撮るなら夜に淡路SAに着て撮影して帰るのが最も無難だろう。本土側からなら垂水からいくらでも好きなだけ見れるので造作もない話だが、私は夜中に明石海峡大橋を率先して見に行こうとしたことがないため、大抵電車の車窓から見ており、まともに撮影できたためしがない。
よく使うジャンボフェリーの夜行便からでも見れるとは思うが、寝てるので難しい。明石海峡大橋の手前まで起きてたら寝る時間が無くなってしまう。
反対側にはスタバとミスドがあり、客でごった返していた。
様々な船が往来しており、何時間でも眺めていられるような風景だ。本土側からだと海に近い高台から見れる場所がないため、ここは非常にいいスポットだ。
二枚目は須磨浦山上遊園や神戸市街の方までよく見える。
いい感じの撮影スポットもあった。まぁまぁ並んでて大変だった。
この辺りで飯を食ってると食べ物がトンビに攫われることがあるらしい。まるで漫画の世界だ。
さて、海ばかり見ていても仕方がないので大観覧車へ向かう。
振り返ると駐車場があったが、見事に満車だった。
という訳で観覧車へ向かう。絶対に高いやつと思いながら向かっていた。
観覧車の手前には淡路島の観光マップがあった。属島がしっかり書かれているほか、その土地の果物や魚介なども書かれていて面白いと感じた。
観覧車の手前には小さな遊園地もあり、ちびっ子たちが遊んでいた。全てコイン式で、係員がいなくても動くやつである。鉄道の奴もコイン式っぽかった。
観覧車の料金は意外と安く良心的に感じた。しかもキャッシュレス対応である。ここ島だぞ?
立派なチケットが出てきて感動した。
さて観覧車に乗車する。客は多くなく、一組しか並んでいなかった。たぶんゴンドラの3割くらいしか乗ってないと思った。しかしスタッフは多く、3人もいたうえ、専用のユニフォームまであったので力が入っていた。
ゴンドラが徐々に高度を上げ、駐車場の混み具合がよく分かるようになってきた。手前のドッグランには犬が放たれていた。
海側に目をやると、この日二隻目のクレーン船を見ることができた。FUKADA SALVAGEと書かれているので深田サルベージ建設のもののようだ。恐らくさっき見たのも同じ奴だろう。
この手のクレーン船は西日本に多いことが知られているが、この理由は恐らく西日本には大型の橋脚が多数あり、その建設需要が高いためと思われる。
例えば大きなものでは関門橋、瀬戸大橋や明石海峡大橋、大鳴門峡、しまなみ海道などがあるし、小規模なものでも神戸大橋や神戸スカイブリッジなど、多分無数にある。
深田サルベージ建設公式サイトを見るとその需要が西日本に集中していることがよく分かる 。
面白いのは橋をくぐるときはクレーンのアームを下ろしているのに、橋を通過しきってしばらくすると上げていたことだ。さっきのクレーン船もアームが上がっていた。もしかすると下げていると都合がよくないのかもしれない。
もう一度駐車場に目を見やると車がどんどん入ってきていた。よく見ると大型車のところに乗用車が息を吸うように止まっていることに気が付いた。あと「えひめ」と書かれたトラックのフォントが可愛いなとか。
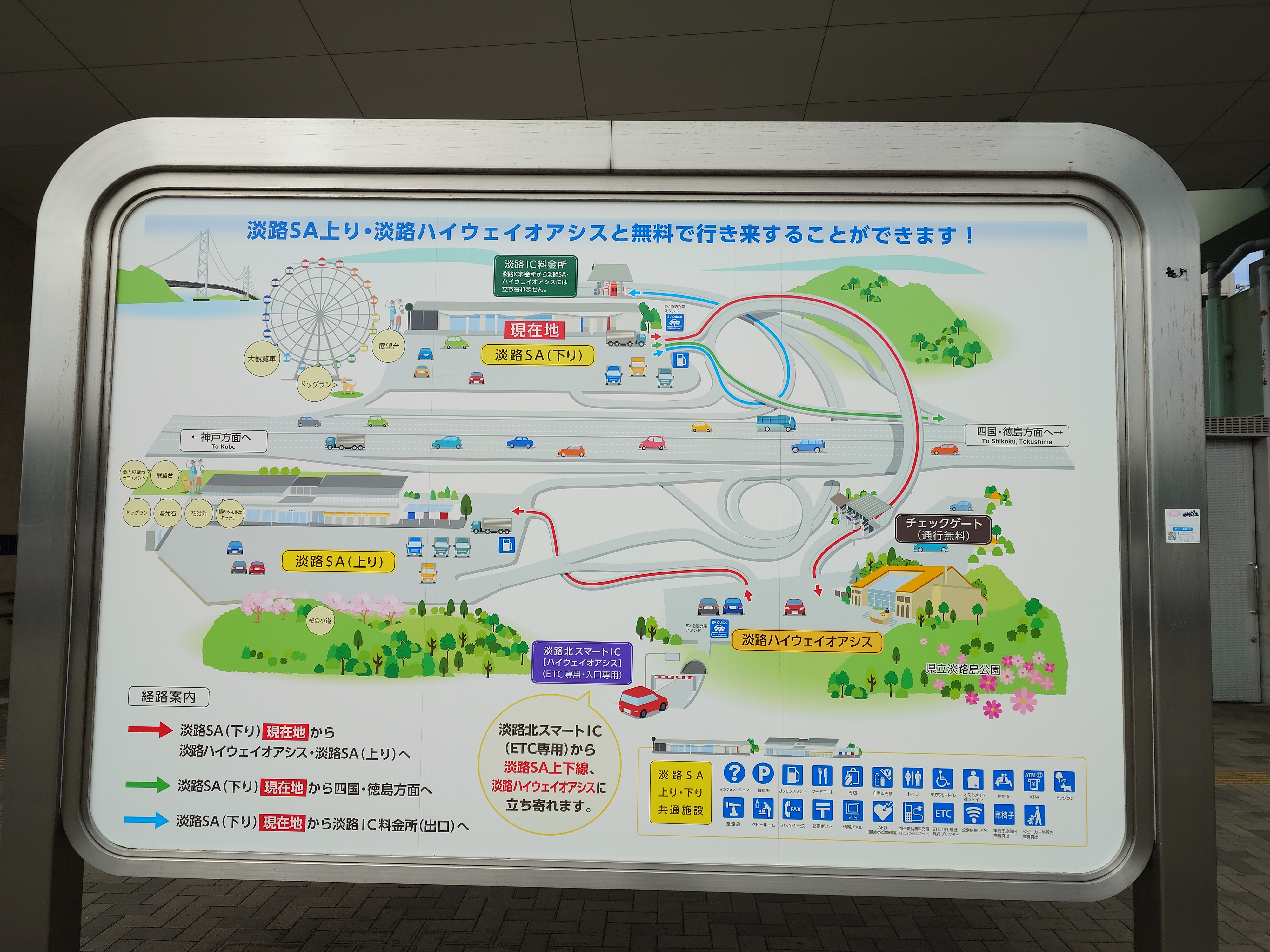
奥にやたら湾曲した高架橋が見えるが、これは上下線にあるサービスエリアを連絡する橋で、上下線は無料で往来できるらしい。この橋は観覧車同様かなり目立ち、本土側からもよく確認できるので、事情を知らないと謎の巨大モニュメントに見えるやつだ。
ここでUターンして入ってきたICで出るとどうなるのだろう?と思ったがJB本四高速によるとしっかり料金を取られるらしい 。
淡路SAで折り返し走行される場合は、入口ICから淡路ICまでの料金と淡路ICから出口ICまでの料金を合算した料金が必要です。
間に検問所があるので、そこでETCが通過した記録を取っているのだと思われる。
また海へ視線へ戻すと、明石海峡大橋の付け根辺りに大きめの船がやっていているのが見えた。もしかしてこれがジェノバラインだろうか?
こうやって視線を回していると色々見えて飽きないものだ。
上り側のSAの手前にため池があるのに気づいた。淡路島はため池の数が多いと聞くが、まさか高速道路の中にまであるとは…。
SAの裏には従業員用の駐車場に見えるものもあって、なるほどここから通勤しているのかと思ったりもした。
眺めていて後で向こう側にも行こうと思った。
海に視線を戻すと先ほどの船が岩屋港と思われる場所にやってきており、サイズ的にこれはジェノバラインだなと思った。
何やら立派な施設が見えたが、これはTHE PASONA natureverse retreat というパソナのリゾートホテルで、6月23日にオープンしたばかりの施設らしい。なんとなく大阪関西万博の大屋根っぽさがある。
公式サイトは横文字が多くて何を言ってるのかイマイチわからないが、恐らく自然と健康をテーマにした施設なのだろう。しかしホテルの名前にパソナとつけてしまうのはどうなのだろう?私はパソナというワードに良いイメージがあると余り思えないので割と不思議だ。まぁ、淡路市がパソナの天下にあるということを示すいいモニュメントにはなりそうだが…。
眼下を見下ろすと淡路ICの入口に「淡路SAには行けません」と書かれた看板が見えた。誤進入が多いのかもしれない。
再び駐車場に目をやると、大型車のとこへ入っていく乗用車が見えたので、多分止めるところを探すのが面倒だし、ここ空いてるから止めようという感じなのかなと思った。
観覧車を降りると先ほど観覧車の中から見た立派な建物の案内があった。淡路ハイウェイオアシスというらしい。
以前調べたときに、向こう側に鰆の刺身が食べられる店があることを発見したので昼食に利用しようと思った。
さて、何はともあれ下り線のサービスエリアの中に入っていく。
入口の案内を見ると中には名物的な料理店が多くあるように見えたが、ここでは食べないので飲食店はスルーする。
昔福良で買った善太の乾燥玉ねぎを切らしていたので土産屋に入ると、淡路島ムードが迎えてくれた。
こちらは関西から四国に行くルートのため、大阪、神戸、京都の土産も目立つ。
淡路は徳島に近いためか、徳島土産も多くあった。半田そうめんまであった。
京都や神戸のパンも売られていたが、神戸で全く見たことがないパンだったので個人的には謎だった。
淡路に因んでなのか淡路屋の駅弁も売られていた。この小ロットをよくここまで持ってくるなと感心した。淡路屋は神戸市東灘区の弁当屋であり、朝に新神戸に行くと納入風景を見ることができるのだが、やはりここにも自社で運んできてるのだろうか…。
しかしいくらどれほど島外の土産物があったところで、淡路島特産品の強さは健在である。
最後に食堂を一瞥。ほどほどに淡路島らしいラインナップがあった。同時にもう一押し足りない気もした。淡路島バーガーを名乗るなら玉ねぎと肉をもっとプッシュしてほしいなとか、そういうのがもっと欲しかった。オニオンリングだけじゃねぇ…。
外には屋台のような店もあり、下りSAは全体的に軽めな感じだなというのを覚えた。屋台は余り淡路感がなかった。
さて、下りサービスエリアを満喫したところで、最初来たトンネルに戻り、逆方向へ進んでいく。
トンネルを抜けるとすぐにバス停があり、土日祝のみの運行ではあるものの、運行本数が毎時一本とかなり多い観光用のバス停を見かけた。
またここには一切かかれていないのだが、ニジゲンノモリのシャトルバス時刻表 もここに来るらしく、シャトルバスの方はパソナ関連施設を周遊する経路 になっており、平日にも走っている ようだ。こちらは毎時一本以上あり、20時便があることから、遅くまで使えて便利かもしれない。
ハイウェイオアシスの看板を見て、すぐ横を見ると謎の階段があったので上ってみることにした。もしかするとショートカットかもしれない!
一体この先に何があるのか…!と登っていくと…。
なんとこんなところに稲が植わった田んぼがあった。ここまで田植えしに来てるの凄くない?
恐らく高速道路の工事か何かで様々な事情により残った田んぼなのだろうか?農機具のタイヤ痕が見えるため、多分あの階段を使ってアクセスしているわけではなさそうだ。
こんなところ私しか来ないだろうなということで景観写真も撮っておいた。
降りてきたので道案内通りに進むが、空から葛の蔓が垂れ下がっており、人が通っているのか怪しい歩道だ。
少し歩くとハイウェイオアシスの看板と入口が現れた。
めちゃくちゃ高速道路の入口っぽい。いやまぁ、サービスエリアに入れるんだからそうか。
ひとまず道なりに歩いていく。車道はまっすぐなのにやたら遠回りでぐにゃぐにゃしている。
案内標識が乏しくてわかりづらいのだが、ここが淡路ハイウェイオアシスの歩行者入口である。車は入口からまっすぐ進めば入れるが、歩行者は何故か駐車場のような場所を大回りさせられる。
ここだけ案内看板がなく、何も考えず道なりに進むとハイウェイオアシスはここを戻るみたいな看板があるので案内に従ってると、ここを進むとここを戻るの間で無限ループになってしまう。ここを曲がるの看板が足りない。
先へ進むと妙に手入れされた看板とトンネルに出会う。ここを抜けると淡路ハイウェイオアシスだ。
トンネルを抜けると丁度ニジゲンノモリバスが止まっていた。
駐車場には奈良観光、みつわバス、湖国バス、ニシワキ観光バス、大上観光バス、帝産観光バスが止まっていた。奈良、大阪、滋賀、西脇、丹波篠山、京都辺りから来ているものと思われる。
奥に行くとありがちな寂れたゾーンが現れたが進撃の巨人コラボイベント受付徒歩15分という文字が見えるので、恐らくニジゲンノモリ入口と思われる。たぶんバスが来た直後だけ賑わってるような場所。
こちらは下りSAと異なり、だいぶん雰囲気がいいところだ。
下りより高台にあるため眺めもいいが、海が遠いのであまりよく見えない。
建物が無駄にいい。下りSAから見たときもかなりいい感じだった。
なんというかガラス張りの温室と西洋の農家の家を合体させたような、風情のある建物だ。
中も雰囲気があるし、募金したくなる変な仕掛けがあるのも面白いと思った。
起きてから何も食べてないのと脚が痛いのもあり、私は鰆の刺身を求め飲食店へと向かった。
店への道中にはAI感の漂う地方創生ゲーム的な何かの掲示があった。ふと「淡路島日本遺産RPG はじまりの島 」のことを思い出したりした。
個人的にはゲームにするとプレイ時間が取られて面倒なのでスタンプラリーにするなら素直にスタンプラリーにした方が開発費がかからず、誰でも参加できるので良いのではないかという気もしている。
景品も洲本オリオンの銀幕を新しくするとか、コモード56の空き店舗レンタル一ヶ月無料とかみたいなのがあると面白くなったりしないかなとかは思った。
さて妙な御託は脇に置いておき飯屋へ入る。
生さわら丼御膳と迷ったが、さわらが入っている淡路玉葱御膳を選ぶことにした。
大変たまねぎな御膳。器からすべてがたまねぎである。左上の玉ねぎはお土産用らしい。
真ん中のどんぶりは玉ねぎのかき揚げがメインだが、鱧の天ぷらも入っていてた。
みそ汁はねぎとたまねぎとわかめしか入っておらず、これ以上なくたまねぎだった。
右上のは玉ねぎを丸ごと使った煮物で、玉ねぎはそのまま食べられるよう、ホロホロになるまで煮込まれていた。
これでもかというほどの玉ねぎ尽くしだったが、いずれの玉ねぎもおいしく、とてもよかった。ここまで玉ねぎ尽くしな料理を食べれる場所も中々ないと思う。
そして夢にまで見た生のさわら!柔らかく甘みがあってよかった。
さわらは炙りやたたきであれば割と見かけるのだが、生となるとなかなか貴重である。
食事を終え店を出るとジャンボフェリーのあおいが航行していた。まさか淡路島から間近に見れるとは思わなかったので思いがけない出会いだった。
建物の外に出ると中々インパクトのある顔ハメ板があった。
奥の方には淡路島生パスタと窯焼きピザのお店があり、更に奥にはペット同伴化のレストランもあった。
ここからの眺望も乙なものだ。
水飲み場があったのでお金がなくても水が飲めて安心!
駐車場とオアシスを結ぶエスカレーターは下りが故障していた。
駐車場に降りると超巨大なトイレがあった。このサイズなら何人トイレに行きたくなっても大丈夫かもしれない。いや実は見せかけだけで意外と便器はないかもしれないが…。
ここでは上りのSAへの道を探してみたものの見つからないので断念した。
帰る途中でGoogle Mapsを見たりググって調べたりしたが、どうやら上りのSAは徒歩では行けないようだった。
最後にハイウェイオアシス内の土産店を見ていくことにした。淡路島を出るときに通るところだけあり、淡路島土産の多さは下りより良く目立つ。
四国土産と並んでもなお圧倒する淡路島土産。微妙に明石が混ざっている。
淡路島土産のいもけんぴは高知のはりま屋から来ていた。高知の日記も書けていないのでまた書きたいものだ…。はりま屋にも行ったのだ。
たまねぎみたいなバウムというのがあり、淡路島の玉ねぎを使ってないなら一体淡路島要素はどこにあるのだろう…と思ったら、公式サイトによると淡路島産のコメを使った米粉や、淡路島産の鶏卵、淡路島の酒粕やはちみつが使われている らしい?
しかし淡路島の牛乳は使われていないっぽい?
玉ねぎも売っていた。しかも安い。買おうか悩んだが1kgも食べれないのでやめた。
他にもひたすら淡島のお土産がこれでもかと並んでいた。
食べ物以外にも瓦もあった。つるぎ町観光記 にも書いたが、淡路島は瓦が伝統工芸の一つにあるので、その関係だろう。
しかし瓦からこれだけのグッズをひねり出せるのも大したものだ。
松山にあるみかんの蛇口の玉ねぎ版があった。しかもなんと無料である。かなり熱いので落とさないように注意しないといけなかったが、美味しかった。
飲み終わった容器でどこから来たかのアンケートも取っていた。兵庫に入れたが、今写真を見たら神戸があることに気が付いたので惜しかった。
大まかには兵庫や阪神圏から来ている人の比率が多いようだ。基本的にこの手の観光地は地元の人間が一番多いと思う。国宝姫路城ですら姫路市民の利用が最多だったはずだし。
美味しそうなアイスもあったがどう考えても持って帰れないこと、ここで食べると太ることから購入を断念した。
この箱の厚みにたまねぎが丸ごと一個!?嘘やろ!?と思ったら、そんなものは入っていなかった。
オアシスの一角では七夕の準備がされていた。
時刻は18:40。いい時間になってきたので淡路島から帰路に就く。
バスで帰るのも無粋なので、運動も兼ねてジェノバラインに乗るべく岩屋港へ向かう。
なおこのルートはニジゲンノモリ公式サイトによると危険 [3]
淡路ICに帰りのバスがいるように見えるが、無視して通り過ぎる。
岩屋港が見えてきた。
観覧車から見た十字路に入る。道の駅あわじというのが気になる。
どことなく南国の空気が漂う太い歩道を降りてゆく。
住宅街に近づくと葛の蔓がもじゃもじゃしてきていた。道が葛で覆われていないことから草刈はされているものと思われる。
ヤンマーのトラクタを置いている家があった。カッコイイ。
こんな観光客が来ないであろう場所から眺める明石海峡大橋とアンカレイジも悪くない。
ここから生活道路に入るので速度に気を付けないといけない。いや、私は歩行者なので関係ないが…。
降りていくので当然だがここの道はそこそこ坂である。
降りていくと古めの住宅が並ぶ住宅街に入ってきた。手前の家庭菜園の規模がデカいのと、右手の廃アパートのような建物が哀愁を誘う。
ここから道が細くなり坂の急さも増し、軽トラの通り道みたいになってきた。
坂の傾斜がきついからか、1Fが車庫で家本体はその上にあるデカい家があった。こういう家は神戸でも西岡本とか、急斜面にある高級住宅街に行くとよく見るが、この家は上に載っているのが従来型の日本建築というのが特筆すべき部分だろう。
西岡本にある家は基本洋風というか、漆喰や焼杉などのない普通の家だ。
廃アパートのような建物の横に来ると、なんと二棟が合体していることが分かった。ちなみにこの時点で一部屋に灯りが点いており、人が住んでいることが確認できた。
アパートが気になりすぎたので回り込んでみようとしたら手前にデカい家があった。この辺りは地味に高級住宅街っぽさがあるのかもしれない。
そしてアパートの前には数台の車が確認できた。この時点で廃アパート疑惑がだいぶ薄れたが、駐車場として使われているだけの可能性もあるので接近してみることにした。
普通にめちゃくちゃ人が住んでおり、大変失礼だった。
1、2とあるので公営住宅かな?と思ったが、アパート名が見当たらなかったので何なのかはわからなかったが、ググった感じしあわせハイツ淡路岩屋1と2らしい。
この辺りは昭和に良くあったであろう細い路地がまだ残っていてよかった。中途半端な地方都市だとこういう場所は雑草で藪になっていたり蜘蛛の巣が張っていたり、ごみが捨てられていたりでまともに通れないのだが、ここは現役の通路として生きていると思った。恐らくこの通りにある家は、こちら側に玄関があるのだと思う。
淡路市立石屋小学校の連絡通路の下をくぐる。この辺りは岩屋という地名のはずなのに小学校の名前が石屋なのは面白いなと思った。
この辺りは昔ながらの後継が残っていて非常にいい地域だ。
廃墟があったので表札を見てみた。どうやらこの辺りはかつて津名郡淡路町だったらしい。
道や景色が渋い…。
ビールケースや椅子の置いてある建物は地域の老人とかの集会所だろうか?
まっすぐ突き進むと廃材置き場のようなところに出てきた。
この辺りは二車線道路で、幹線っぽさがある。ビデオ・酒と書かれた店も気になる。
適当に港がありそうな方角に進んでいると岩屋商店街の看板が現れた。恐らく先ほどの十字路の横道に繋がる場所だろう。
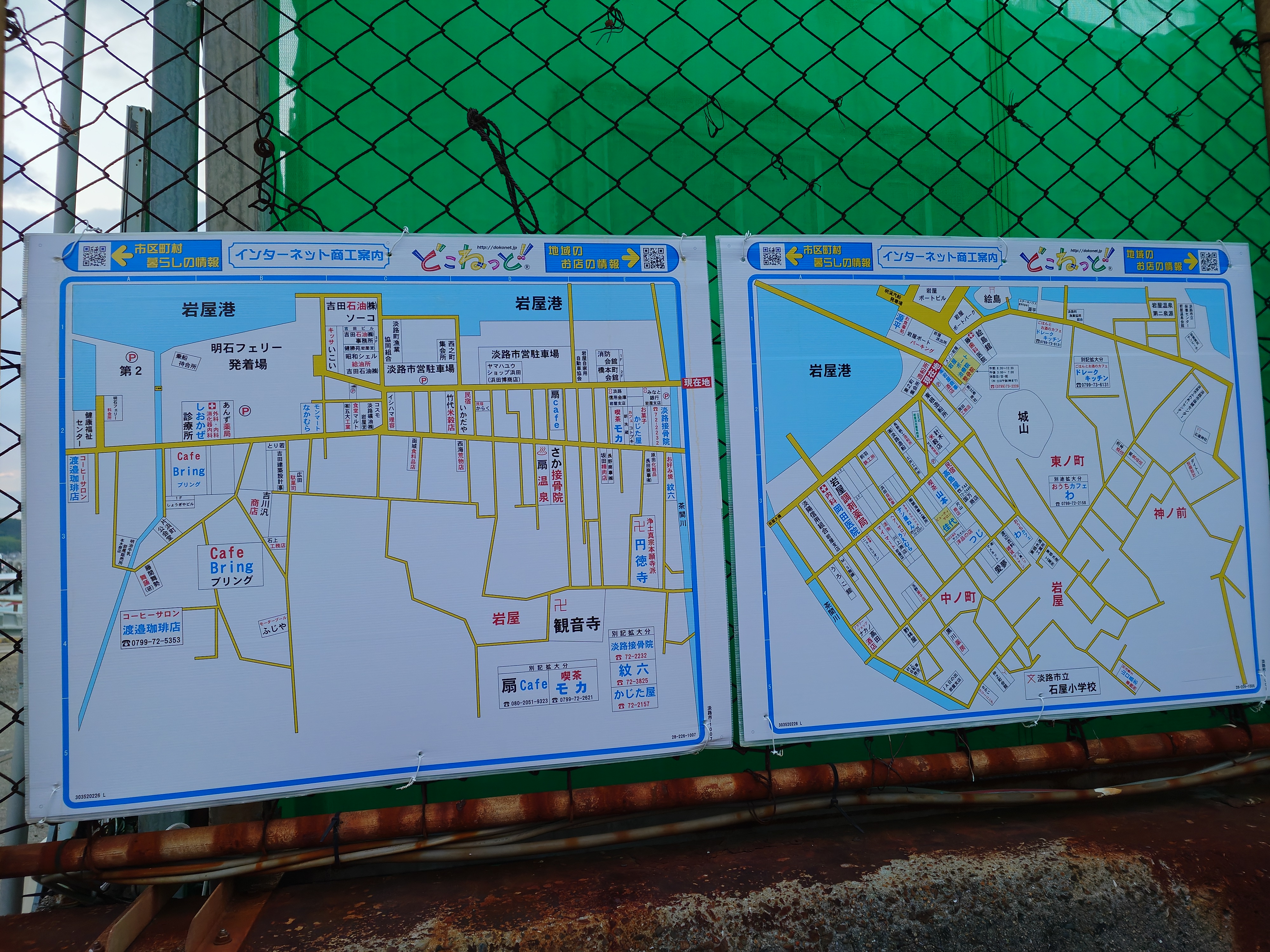
今はもう存在しない「淡路町」の文字がまだ残っているところが味わい深い。とはいえ、商店街によくある専用の街灯が残っているあたり、まだ有志によって景観や設備の維持はされているのかもしれない。
どこねっとの看板は新しく、これを見た感じ商店街にはまだ生きている商店が点在してそうだった。
恵比須神社があった。エビスは地方によって微妙漢字が違うので面白い。
そして荒廃しておらず、今でもちゃんと手が入ってそうなのがいい。
そしていよいよ岩屋港に着いた。
明石行き(13分)高速艇 ジェノバラインの文字がまぶしい。
駐車場はもう使われておらず、従業員用になっているように見えた。ここにも淡路町の名残があった。町営。
しかも町の文字が塗り替えられた痕跡があるので、かつては村営とかだった可能性がある。
恐らく元々は廃止されたたこフェリーの名残ではないだろうか?船に車を積むと高くなるから駐車場に入れて歩いて乗る的な。
岩屋港の前に着くとロータリーにはアワイチのモニュメントが置いてあった。時間があればこの向かいにある島に行きたいところだったが、もう時間が遅いことと、船が着岸していたため乗船を優先することにした。
ここがジェノバラインに乗船するための場所、岩屋ポートターミナルだ。新しく綺麗でいい感じの建物である。
生しらす丼ののぼりがあることから軽食も摂れるのかもしれない。
時刻は19:15。寄り道しながら写真撮りながらのんびりやってきて35分なので、普通にくればオアシスから徒歩15分そこらで来れるだろう。
ターミナル内はこんな感じで、自販機に机があり、ゆったりできそうな感じだった。
コインロッカーもあるので荷物を預けることもできる。写真は見切れているが、切れている部分をよく見ると中型くらいのロッカーもあるように見える。
シャッターが色々閉まっているが、日中なら食堂や受付窓口が開いている感じだろうか?
見た感じ乗船客はそこそこおり、列ができていた。
切符売り場は現金のみだが、新札に対応していた。
切符は回収されるので持ち帰れなかったが、写真を撮っておいた。700円で船旅ができるなら安いものである。
どうでもいいがジェノバと言うとFF8を連想してしまう。
悠長に写真を撮っていたら出航しそうだったので改札へ向かう。
今回はまりーんふらわあ2という船に乗る。現在通常運航の船がドック入りで原付が乗れない案内がされていたので、これは予備船らしい。
車を積めない分、旅客定員は217人と多い。
階段を上ってみると風通しのいいデッキ席があったのでこちらを利用することにした。
目の前にまりん・あわじと書かれた船がいたが、恐らくこれが通常運航で使われている船だろう。横にドックらしきものが見えるので入渠中なのだと思われるが、淡路市の名前が書かれているのが面白い。
どうやら淡路市の建造した船 をジェノバラインが運行しているようだ。
まりーんふらわあ2のデッキ席には簡易ではあるもののペットボトルホルダーがあり、充実していた。
(Browser not support video tag) pub/lycolia/image/adiary/2026/06/jenova.mp4
これは特に意味もなく岩屋港から明石港までを録画したもの。淡路島ののどかな風景が徐々に明石市の都会な景色に代わっていくような感じがある。
よく見ると明石海峡大橋の下をくぐれるので回数券を買って往復しまくればくぐり放題である。
途中で阪九フェリーともすれ違っている。
明石港に着いたので下船してゆく。
1Fの通常座席はこんな感じ。
時刻表を見ると平日の多い時では時間3本も出ていてかなりの本数だ。解り易さのためだろうが、小型船という船名すらない船がいるのも面白い。
明石港側にも結構客がいて、橋があって自転車やバイクが載せられない状態でも需要はあるんだなというのを感じた。
淡路港側のターミナルはしょぼく、待合室という感じだった。
岩屋港とは異なり券売機も二台中一台が旧式で、旧紙幣や硬貨は使えなかった。
建物はいい感じなので勿体ないなと思った。子午線ラインという愛称も明石らしくていい。
建物の前は広めになっていてロータリーとして使えそうな感じがあった。
明石市側の乗り場周辺は飲み屋くらいしかなかったので、何か食べたい場合は事前に持ち込んでいるといいかもしれない。
今年も魚の棚で半夏生七夕夜市が開かれるようで交通規制の案内が出ていた。夜市とかもうずいぶん長いこと来てないし来てみるのもありかもなぁとか思った。
道なりに交差点に出ると駅の案内が出ていて便利だった。
三白館の前では解体工事か新築工事がされていた。恐らくマンションか住居ができると思うので、明石駅前とはいえ商店街の衰退は避けられない宿命であることが垣間見える。
魚の棚までやってきたらあとはもう余裕である。全然関係ないが私は魚の棚を「うぉんたな」と読む明石の習わしが好きだ。
魚の棚の雰囲気はいつ来てもいいものだ。
淡路島を出て明石に着き、一気に都市部に出てきたような景色だ。
前は歩道橋に名前がついていなかった気がするが、いつの間にか名前がついていた。
都会だ…。
パピオス明石には明石高校の生徒が描いたかわいらしいイラストが掲示されていた。真鯛に真蛸に天文台、そして明石海峡大橋。まさに明石である。なお明石海峡大橋の本土側所在地は神戸市であり、明石市からは単に橋が見えるだけである。
おしゃれで広いスペースの奥に駅が見え、都会を感じる。神戸の人間が何言うてんねんという感じではあるが、まぁはい。
照明のいい感じの明るさと景色。
都会的な電光表示!
駅!鉄道!
改札に吸い込まれると丁度いいタイミングで新快速が来ていた。岩屋港に着いた時もちょうどいいタイミングで船がいたし、この日はタイミングがとてもいい日だった。
そして三宮に帰ってきて、旅は終わりを告げた。
大体たまねぎ。四国成分ちょっぴり。
玉ねぎ系は神戸でも物産店に行けば買えたりするので特に買って帰る意味もなかったが、なんとなく買って帰ってきている。
淡路島なら善太の乾燥玉ねぎが手に入らないかな?と思っていたが、それが手に入らなかったのは残念だった。たぶん善太のは南あわじ市までいかないと難しいのだと思った。
何はともあれ、これにて淡路市、洲本市、南あわじ市のすべてに上陸したので、自治体レベルでは淡路島完全制覇である。
今回の収穫としては淡路市には岩屋港周辺に道の駅などの面白スポットがありそうなことが分かったので、気が向いたら運動がてらまた行くかもしれない。ただこの手の旅ブログネタが蓄積しすぎて書けていないので、まずはそっちを吐き出したいところもあり…難しい。行けば行くほど溜まっていってしまうというか…。
そういえばどこねっとの看板は全国津々浦々で見かけるが一度もHPを見たことがないので見てみたら、東京にある株式会社JKK なる会社がやっていることが分かった。小字未満の粒度で存在すると思うが、よく作ってるなと感心する。どこにでもあるので登録料で稼いでいるとも思えないし、どうなっているのだろう?
2026-07-02追記
なんか知恵袋とかを見ると営業マンが来て登録料を取ってるらしい…。全国津々浦々にあって無数の商店が載っているのに、とんでもない所業だ…。
半年で3000円ほどらしいが確かに膨大な掲載店から取れればかなりの収益になりそうだ。しかも淡路市の文字が入っていたあたり、自治体の公認をとってやってる可能性もある。
プラ段製看板の制作費はしれてると思うので、いい事業なのかもしれない。
他にも追加料金でブログとかも作れるそうだが、どれほどの店がやってるのかは果たして謎である…。