2026/06/02(火)LLMに対する最近の思いとか過去の考えとかの整理
投稿日:
これまでいろいろ書いてきたが、それらの総括的なものを吐露していく。
金銭面での問題
LLMは金が掛かる。特にAnthropicをBANされて、Poeから叩いている私はなおのこと金が掛かる。
レートリミットがないので無限に使えるのを強みと言いたいが、そんなのはすっぱい葡萄の話でしかない。
またクラウドの登場からずっと言われていることだが、デジタル赤字の根源の一つにもなっている。
LLMを使えば使うほどAnthropicやOpenAI、Googleなどに富が流れ出ててしまうので、これは国としてみた場合に深刻だ。最近はデジタル小作人とかとも言われている。
とはいえ、正直これは仕方がない面もあり、ぶっちゃけITシステムはコモディティ化しやすく、局所的なところに集中せざるを得ないと思っている。例外的に中国だけは国内で回せているが、最前線とまでは言えないにせよ自前で実用水準を回せているが、これは中国の地政学的な問題が大きく影響していると考えている。
何故なら中国はその体制的に、アメリカのIT資産にアクセスできなかったり、仮にできてもある日突然禁じられるリスクがある。それなら中国の国家運営にフィットし、あわよくば普及させることで他国を操作しうる国産モデルの開発を好み、そのためなら予算を惜しまないだろう。だからこそ、一定のLLM開発が成立していると言える。
何故なら、もしアメリカを超えるモデルを作って普及させられれば、アメリカがやっているように「使わせない」ことで圧力をかけたり、制裁の脅しに使えるからだ。当然、そこから情報を抜き取って中国に有利な形で活用することもできるだろう。実際、中国が怪しい振る舞いをしているのは、Huaweiの問題や、宇通のバスに仕込まれていたバックドアからも明らかだ。
一方、日本にこれはできない。ドイツやイタリアをはじめとした欧州諸国だってそうだろう。アメリカ以外の国の大半には自国でフロンティアモデルレベルのLLMを作るだけの技術もリソースも恐らくない。何故なら現状フロンティアモデルは中国ですら到達できていないからだ。中国はフロンティアモデルを使ってLLMをトレーニングしていることが知られており、AnthropicもDetecting and preventing distillation attacksでそのことを公表している。要するに、中国でさえ自力でまともなモデルを作るだけのリソースを持っておらず、他人の成果物を横取りすることしか出来ない訳だ。
だが本質はそこではない。仮に世界各国が作り合ったとしても、同じようなものが万国に散らばっていても意味がない。すべての国が中米のように敵対しているわけでもない以上、いずれどこかに収束するのは自明であり、結局やる意味がないと言える。
開発時の認知負荷の重さ
AIを使った開発に取り組み始めてみた雑感で軽く触れ、Value-DomainのDNSを操作するユーティリティを更新したで実感したことだが、LLMを書いたコードをレビューするのは大変だ。
何せ一気に大量のコードを書いてくるし、もっともらしいコードを書いてくるので非常に疲れる。これが人間の書いたコードなら荒探しをしたい気持ちなどが湧いてきて徹底的に見たりするような気がするのだが、LLMは人間ではないのでそんな気も起きない。だって、間違いを指摘しても学んだり成長しないから、意味がない。
AIコーディングのレビュー負荷に関することは色んな企業のテックブログでも言われていると思うが、正直大量に書かせてしまうとレビューはほぼ無理だと思う。
先日読んだテストコードの意味がないという記事もまさにそれに近い話だろう。とはいえ、なかなか難しい話だとは思う。
個人的には実装からテストコードを書かせるのであっても、正常ケースと異常ケースを網羅的に書かせることができれば、以後の修正でテストが落ちれば、それは問題ないと感じる。但し初回作成時に実装コードを破壊して、意図したとおりにテストが落ちることの確認はしておいたほうが良いだろう。とはいえ、LLMに書かせているとそれすらおっくうになってくるのが個人的には困りものだ。
やるとしたらモジュラモノリスのような小さなモジュールを集めた構造にし、それを書かせれば多少はマシになると思う。でもそれって人間書いてもいいですよねってなるわけで、何ともな感じもある。
他にもLLMが書くと人間が正しく認知しないとか、人間が手で書いていればハマった部分や苦労した部分などで記憶に残り、バグが出たときに「あそこかも!」という当たりが付いたりするが、LLMに書かせていると、まず無理だろう。
当然LLMでも特定はできるだろうが、LLMは金が掛かるし、ソースを精査する時間も長い。チューニングで何とかなるといっても誰がチューニングするんだという話になってくる。
思考力の低下
よく昔はできたが今はできないということが語られると思う。例えば元開発者のマネージャーが、手を動かさなくなった結果、開発方法を忘れたとか、そんなことを話したりする。やっていなかったことができなることは自然なことだ。日々やり続けることによってのみ筋力が維持されるのと同じことである。
同様にLLMを使っていれば、LLMを使う力は養われるだろうが、LLMに文章を書かせていれば文章力が、LLMにコーディングさせていれば設計力や実装力が失われていくのは自明のことだろう。
果たしてこれはいいことなのかどうかというのはとても思う。たぶんLLMに漬かりすぎていると早期にボケるのではなかろうか?
登山中に電波が届かない環境や、会議のファシリテートなどで「LLMを使わないとわからない」なんてことは言いたくないものである。山の中は電波が届かないし、悠長にやっていてはバッテリーがなくなり、日が暮れる。ファシリテーターが一々LLMに聞いていては会議が進まない。
またLLMの技術を使ったブラウザ操作や、ECサイトでの買い物なども出てきており、この辺りでは意思決定の一部さえLLMに委ねており、人としてそれでいいのかとも思ってしまう。何も考えられなくなりそうだし、人としての意思とかは残るんだろうとか。
2024年12月20日には兵庫丼に次のことを書いていたが、まぁこんなのは今となってはもうどこでも起きていそうである。
「AIが提案したので実装しました。なんで動くのかは知りません」
「AIの提案なら大丈夫でしょう!レビュー通過です」
みたいなやり取りは全国でどのくらい起きてるのだろう
人類そのうちAIに質問して出てきた返事のとおりにしか行動できなくなるのではないかみたいな心配をしてしまいがち
LLMプロバイダに生殺与奪の権利を握られる
AnthropicなどのLLMプロバイダは規約違反した人物をBANすることで有名だ。実際に私もAnthropicをBANされている。
BANされると使えなくなるのでBANされないように忖度が始まるが、使わなければこんなことは気にしなくても済む。まぁ忖度したところで企業レベルでBANされてる話も聞くし、そもそも夜職に関わる開発など、BANされるような産業だとどうしようもなさそうだが…。
他にもおむつメーカーがパッケージを見せたところ児童ポルノ判定されたという話もみたことがあるので、何とも難しいことだと思う。LLMはなんにでも使えるわけではないのだ。
LLMは本当のことを言えない
これは何が本当のことか?という話になってくるのだが、LLMは本当のことを言えない。それに対して人間ならそれを言えるという話だ。
では何が本当のことか?だが、人間は生きている間ずっと、連続して何かを経験している。そして経験したことを、自分の言葉として言える。一方LLMは、膨大なテキストを流し込まれているだけだ。知識カットオフ以降のことやRAGで与えられた情報も語れるが、それらも結局は外から与えられたものにすぎない。つまりLLMが発することは、全て他人の又聞きでしかない。要するにLLMの言葉は「隣の田中さんがそう言っていた」と言う噂話を膨大に集めて確率的に確かにした話ということになる。
私は本当のこととは実体験に基づく、その人物だけが言えることだと考えている。「私はこれを見た」「私はこう感じた」、そういった実体験に基づく知識は人間にしかない。例えば昔事故を引き起こした振る舞いを知っていれば、それを止めることができる。いわゆる筋の悪さを語れるという話だ。しかし、LLMにはこの経験そのものが存在しない。だからLLMは、世界についての情報をいくら正確に語れても、「私が経験した」という意味での本当のことを、ただの一つも言えない。
もちろん、その経験が実際に役立つとは限らない。人間の側の知識が間違っていたり、古すぎたり、今回のケースとは違ったりして、役に立たないこともあるだろう。それ故にLLMのほうが正確な情報を出すことも少なくない。
しかし、LLMの情報がどれほど正確でも、LLMの言葉は誰のものでもない又聞きのままだ。そして人間の言葉には、たとえ間違っていても、その人が実際に経験したという、唯一無二の価値があると考える。
そう考えると人間はLLMの又聞きを聞いて頷いているだけではなく、独自の知見を求めるのがより大切なのかもしれない。他の誰も知りえない、そんな自分だけの体験を得ることができれば、何かになるのかもしれない。
LLMは日々成長しない
人間は基本日々成長したり劣化したりするけど、AIにはそれがない気がする。AIは学習したことをミックスして吐き出すことしかできないので思いつきや閃きと言ったイノベーションは起こせないと思う。
いやまぁ遺伝的アルゴリズムみたいなことすればできなくはないと思うけど、AIは人間に比べると個体数が少ないし多様性にも限度があると思うし、どうしてもどこかに収束していきそうだ。
ということを2023年12月12日に兵庫丼に書いていたので、こちらにも転記しておく。
LLMと話してると疲れる
壁打ちなどでLLMを使うことはよくあると思うし、だる絡みだっていくらでもできるが、割と虚無な話になって時間だけが経ち、無意味な会話になっていて可処分時間がつぶれて疲れただけというのは経験として割とよくあった。
回答に対しても一貫性がなく、生成するごとに違う回答をしてくるので疲れるみたいなところもある。
また基本的にスレッドを分けると過去の記憶は残らないので、以前の話はなかったものとして進むとかもあり、なんと言うか友人とかと思って接していると疲れる気がしている。
これはSNS疲れによく似たLLM疲れについてで幾らか書いているほか、個人的に思うLLMの活用方法についてにもある程度通じることを書いている。
LLMは理想を完全には作ってくれない
自分が作りたいものを100%形作ることにはLLMにはできない。人によっては気に食わず直すこともよくあるだろう。
これは単純な話で、部下にこれを作れと命じたところで微妙に違うものが出てくるのと同じことである。本当に解像度100%で自分が欲しいものを作りたい、こだわりや矜持を持ちたいなら、それは自分で作るしかなく、LLMに作らせる時点でそこに妥協が生まれるのだ。
あとがき
LLMそのものは便利だが、人間の手に余りすぎるし、金はかかるし、人の思考を奪ってくる割に、熟練の人間の思考より早く動くわけでもないので、常に使えるわけでもない。それに頼りすぎると人間性が失われそうでもある。そして何よりもそこに拘りは残らない。
Value-DomainのDNSを操作するユーティリティを更新した記事のあとがきにも次のように書いたが、きっとLLMに頼りすぎず、自分で何かを成し遂げていけたらいいのだとは思う。問題は今の時代にそれがどれほど実際に可能か、みたいな話ではあると思うのだが、このままではLLMの言いなりになって、LLMの単一思考によるコモディティ化と先細りしかないようにも思うし、デジタル赤字とかも問題だと思うので…。
ボケ防止のためにはAIに頼らず、自分の手を動かすのも大切なことだと思う。こういう話では、よくそろばん論を持ち出して、そろばんを使わなくなったが人類は劣化していない、電卓があるみたいなことを言う人がいるが、実際問題珠算ができる人は非常に速い速度で暗算ができ、頭の回転も速いとされているので、電卓があるから優位と言われれば、それは違うと思う。例えば電卓を取り出す時間で計算が終わっていたり、物事を予測しやすかったりするわけだ。
なんと言うかLLMを主とせず、あくまで補助的な役割で使っていければ、人の判断や軸が残るので、良いのではないだろうか?とかは少し思った。
2026/05/21(木)GrafanaでLokiのログからログメッセージを部分一致で検索する
投稿日:
Grafana Logs Drilldownではフィルタ出来るのにExplore > Lokiでクエリを打ってもログを引けなかった。これを引けるようにするのが目的。
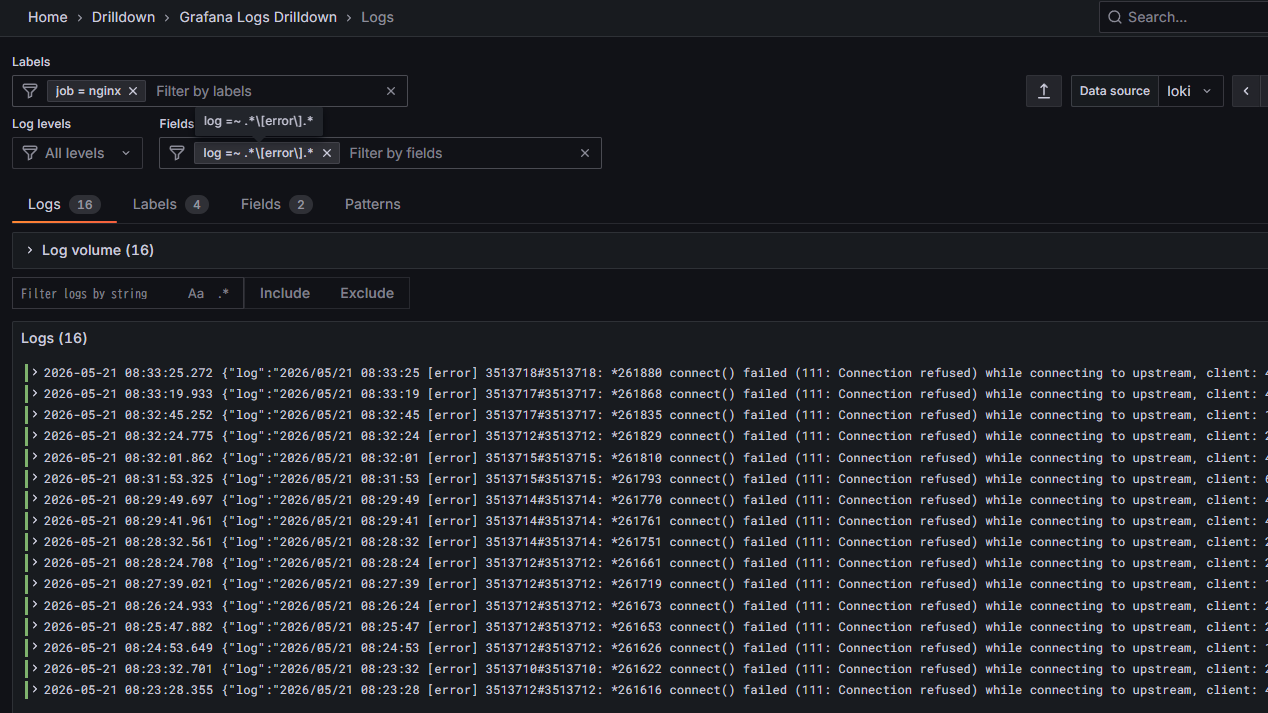
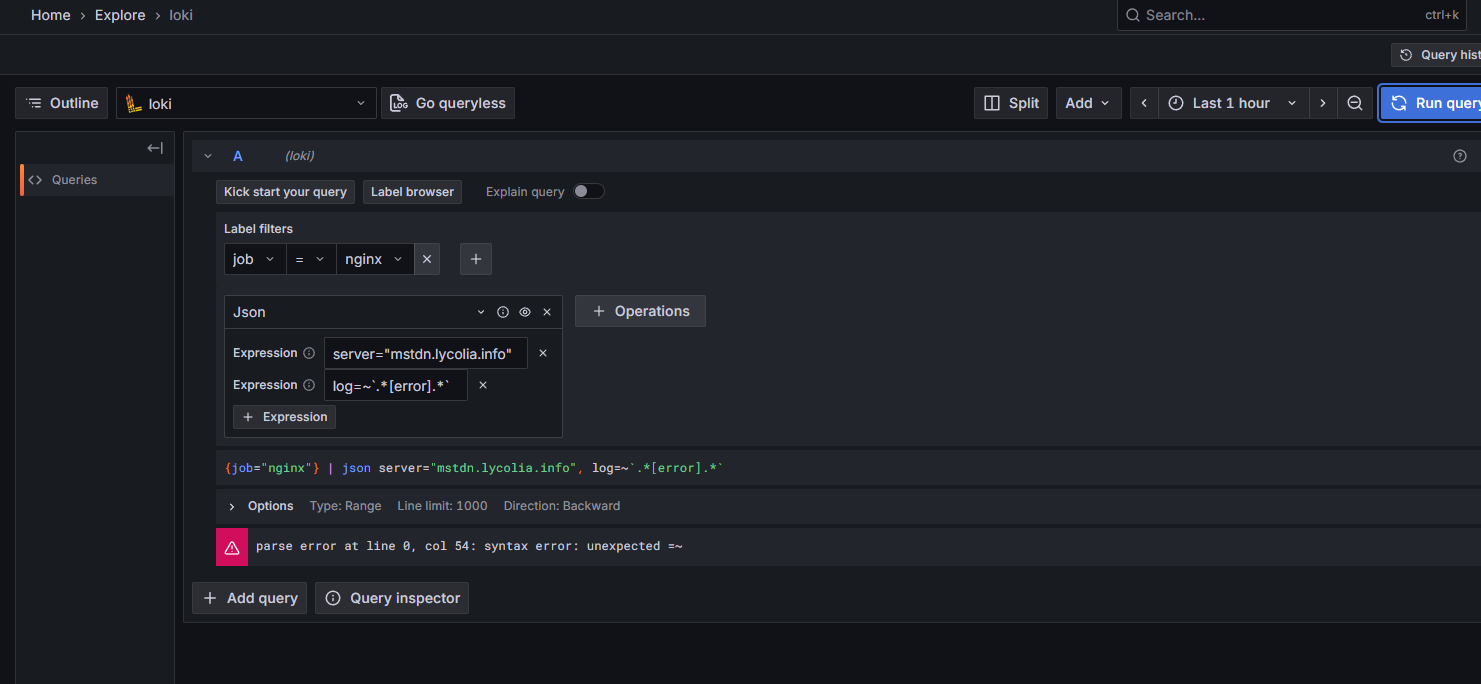
確認環境
nginxのログをFluentBitで拾いLokiに送る構成。
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Loki | 3.5.9 |
| FluentBit | 4.2.2 |
| nginx | 1.26.1 |
| Grafana | v12.1.1 |
やり方
server: mstdn.lycolia.infoで[error]を含むものを検索する場合、こうしておくと引ける。要点はjson msg="log"で別名をつけること。logのままでは構文エラーになる。
{job="nginx"} |= `error` |= `server: mstdn.lycolia.info` | json msg="log" | msg=~`.*\[error\].*`
|= についてはQuery best practices | Grafana Loki documentationで、最初にラインフィルタをかけるとパフォーマンスが上がるということで付けている。error
server="mstdn.lycolia.info"を指定するとなぜかうまくいかなかった。
2026/05/19(火)ローカルでQwen3.6-35B-A3Bをベンチしてみた
更新日:
投稿日:
投稿日:
前回のマシンを更新したのでローカルLLMを軽くベンチマークしてみたでは生成速度だけを見れば十分実用ラインということを確認したが、品質が悪い問題があった。
そこで4月に出て、そこそこ評判を聞くQwen3.6がいかほどのものかというのを軽く試し、ついでにベンチマークもした。
CPU推論とGPU推論が分かれているが、これは初回ベンチマーク時にCUDAのDLLを入れ忘れていたため、GPU推論はDLLを入れてリトライした時の数値、CPU推論はDLLがない状態の数値で書いている。
確認環境
ハードウェア
| 種別 | デバイス |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5(DDR5-5600 16GB) * 4 |
| M/B | ASRock Z890 Pro RS |
ソフトウェア
実行環境はWindows 11。今回はllama.cppをメインで使っている。
| Env | Ver |
|---|---|
| llama.cpp | 9196 |
| Ollama | 0.24.0 |
| Open WebUI | 0.9.5 |
ベンチ結果
[llama.cpp] Qwen3.6-35B-A3B-UD-Q4_K_M
入出力例
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

CPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 203.404 |
| prompt_per_token_ms | 14.528857142857143 |
| prompt_per_second | 68.82853827849993 |
| predicted_n | 1553 |
| predicted_ms | 94147.172 |
| predicted_per_token_ms | 60.622776561493886 |
| predicted_per_second | 16.495450335990974 |
| input_tokens | 14 |
| output_tokens | 1553 |
| total_tokens | 1567 |
リソース消費
GPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 103.612 |
| prompt_per_token_ms | 7.400857142857142 |
| prompt_per_second | 135.11948422962593 |
| predicted_n | 1554 |
| predicted_ms | 26037.862 |
| predicted_per_token_ms | 16.755380952380953 |
| predicted_per_second | 59.68231953913881 |
| input_tokens | 14 |
| output_tokens | 1554 |
| total_tokens | 1568 |
リソース消費
[llama.cpp] Qwen3.6-35B-A3B-UD-Q5_K_M
入出力例
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

CPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 228.782 |
| prompt_per_token_ms | 16.34157142857143 |
| prompt_per_second | 61.19362537262546 |
| predicted_n | 1816 |
| predicted_ms | 119116.155 |
| predicted_per_token_ms | 65.59259636563877 |
| predicted_per_second | 15.24562306431063 |
| input_tokens | 14 |
| output_tokens | 1816 |
| total_tokens | 1830 |
リソース消費
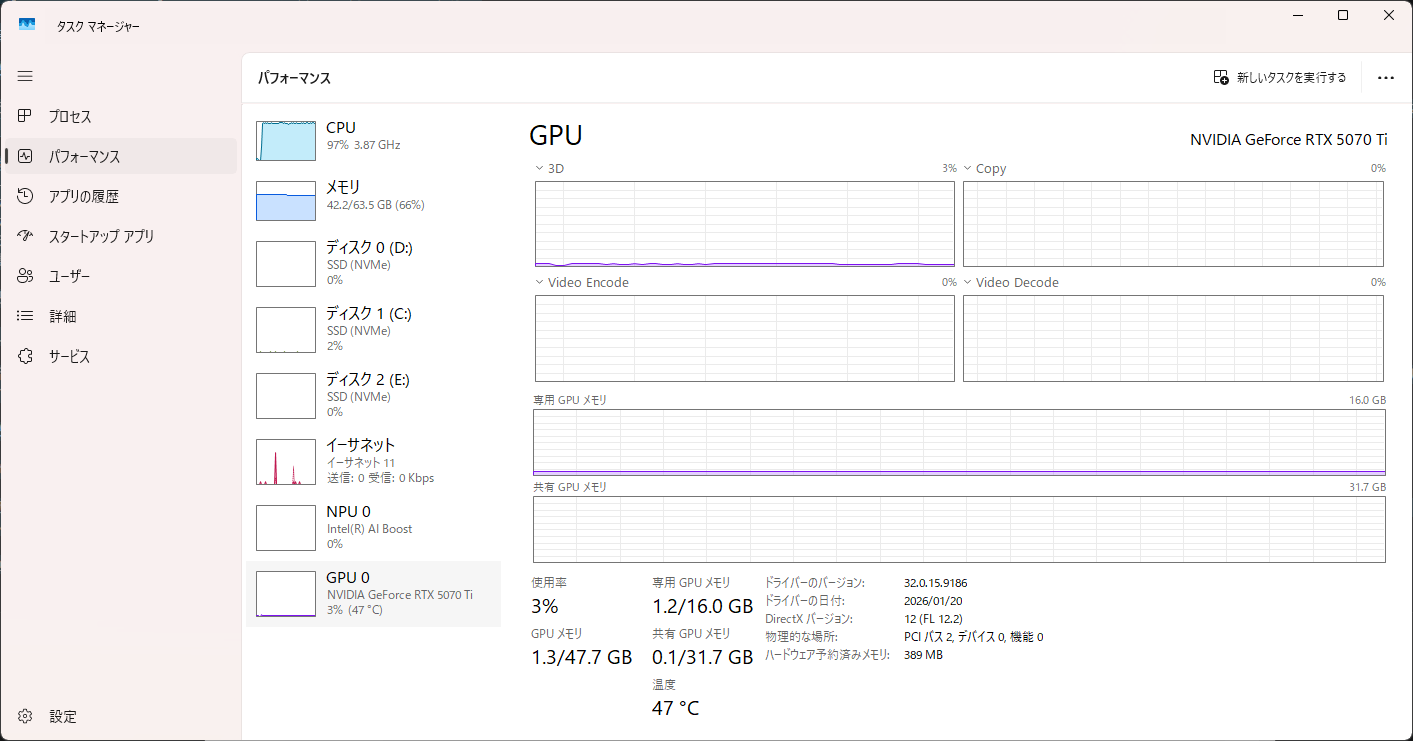
GPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 156.28 |
| prompt_per_token_ms | 11.162857142857144 |
| prompt_per_second | 89.58280010238033 |
| predicted_n | 1575 |
| predicted_ms | 30901.59 |
| predicted_per_token_ms | 19.620057142857142 |
| predicted_per_second | 50.96825114824189 |
| input_tokens | 14 |
| output_tokens | 1575 |
| total_tokens | 1589 |
リソース消費
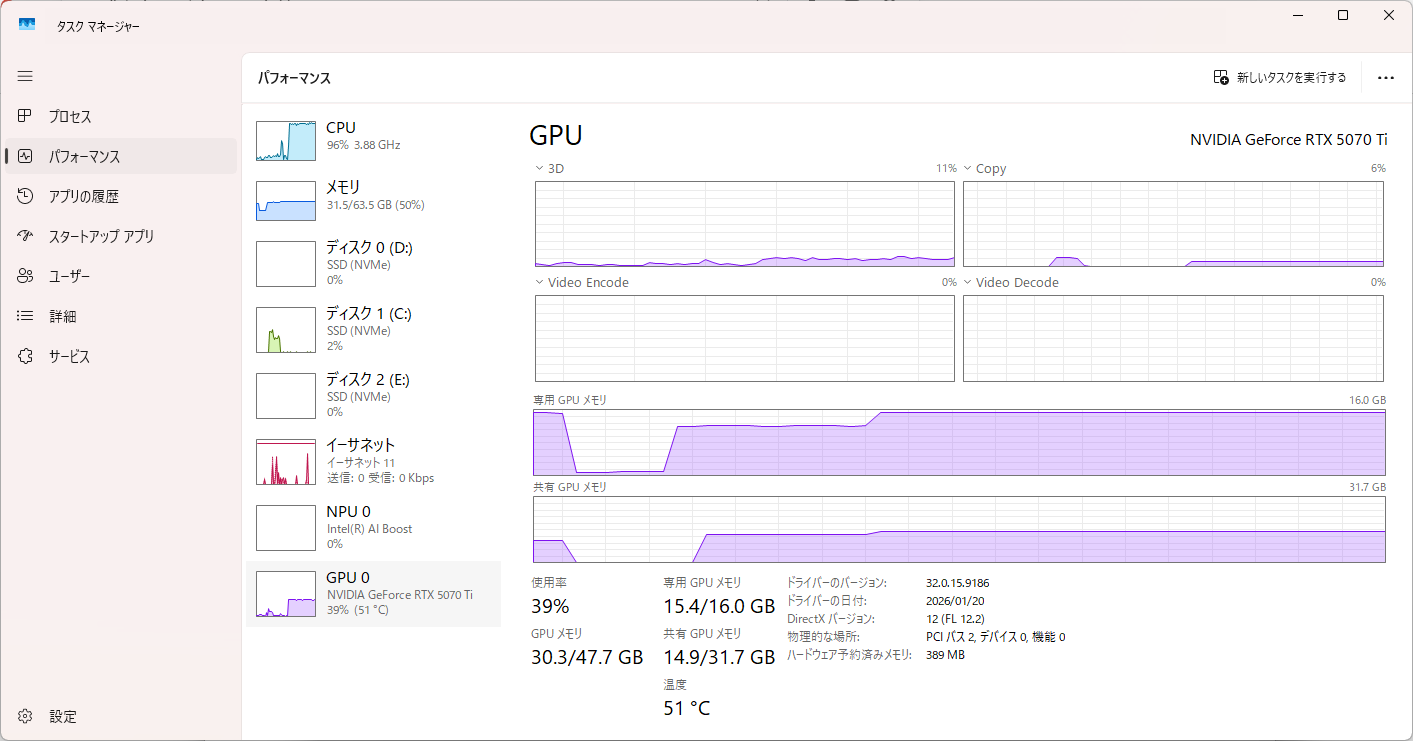
[llama.cpp] Qwen3.6-35B-A3B-UD-Q8_K_XL
Qwen3.6-35B-A3B-UD-Q8_K_XLを使用。
入出力例
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし
CPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 262.85 |
| prompt_per_token_ms | 18.775000000000002 |
| prompt_per_second | 53.262316910785614 |
| predicted_n | 1704 |
| predicted_ms | 119261.701 |
| predicted_per_token_ms | 69.98926115023474 |
| predicted_per_second | 14.287906223977135 |
| input_tokens | 14 |
| output_tokens | 1704 |
| total_tokens | 1718 |
リソース消費
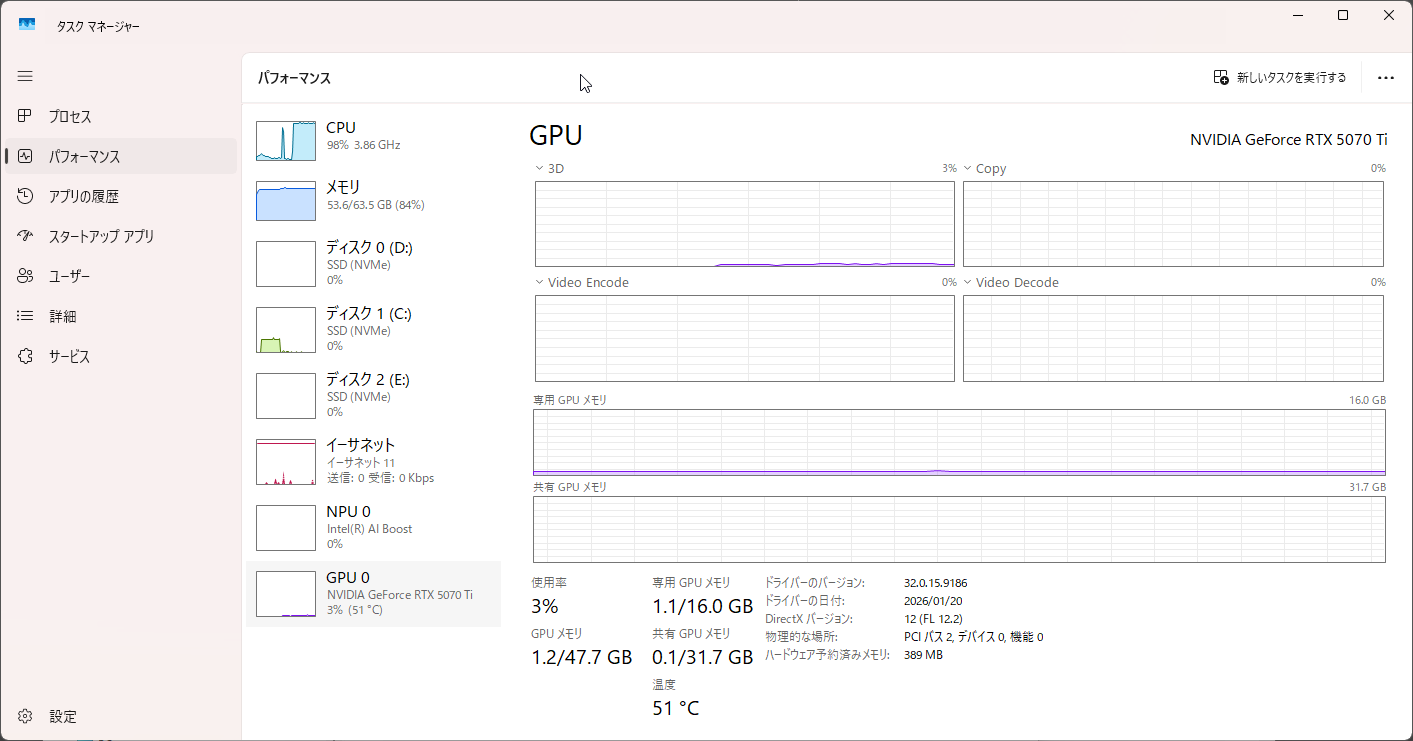
GPU推論
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 190.329 |
| prompt_per_token_ms | 13.594928571428571 |
| prompt_per_second | 73.55684104892055 |
| predicted_n | 1829 |
| predicted_ms | 51098.747 |
| predicted_per_token_ms | 27.93807927829415 |
| predicted_per_second | 35.7934412755757 |
| input_tokens | 14 |
| output_tokens | 1829 |
| total_tokens | 1843 |
リソース消費
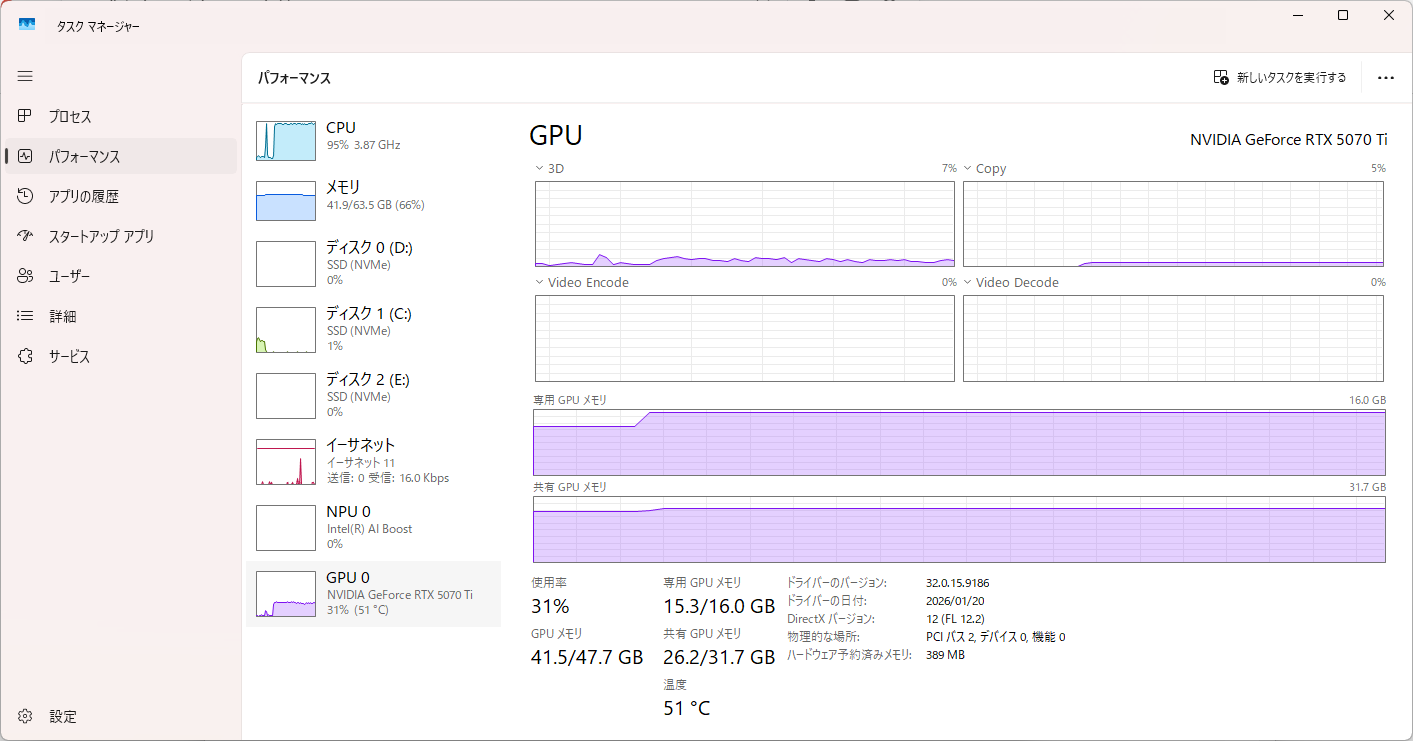
[Ollama] qwen3.6:35b
qwen3.6:35bを使用
入出力例
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

CPU推論
生成速度
| 指標 | 値 |
|---|---|
| input_tokens | 14 |
| output_tokens | 1364 |
| total_tokens | 1378 |
| prompt_tokens | 14 |
| completion_tokens | 1364 |
| response_token/s | 20.84 |
| prompt_token/s | 5.84 |
| total_duration | 126876747900 |
| load_duration | 58586625500 |
| prompt_eval_count | 14 |
| prompt_eval_duration | 2398703000 |
| eval_count | 1364 |
| eval_duration | 65458229300 |
| approximate_total | "0h2m6s" |
リソース消費
llama.cpp実行コマンド
実行コマンド
このコマンドはRTX 5070 Ti + 9800X3D running Qwen3.6-35B-A3B at 79 t/s with 128K context, the --n-cpu-moe flag is the most important part. |r/LocalLLaMAにあったものを利用している。
llama-server.exe ^
-m "ここにモデルファイルのパス" ^
--fit on ^
--fit-ctx 128000 ^
--fit-target 256 ^
-np 1 ^
-fa on ^
--no-mmap ^
--mlock ^
-b 2048 ^
-ub 2048 ^
-ctk q8_0 ^
-ctv q8_0 ^
--temp 0.6 ^
--top-p 0.95 ^
--top-k 20 ^
--min-p 0.0 ^
--presence-penalty 0.0 ^
--repeat-penalty 1.0 ^
--reasoning-budget -1 ^
--chat-template-kwargs "{\"preserve_thinking\": true}" ^
--host 0.0.0.0 ^
--port 8033
まとめ
CPU
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 68.82 | 61.19 | 53.26 |
| 出力tok/s | 16.49 | 15.24 | 14.28 |
GPU
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 135.11 | 89.58 | 73.55 |
| 出力tok/s | 59.68 | 50.96 | 35.79 |
Ollama
| 指標 | Ollama |
|---|---|
| 入力tok/s | 5.84 |
| 出力tok/s | 20.84 |
上の表の指標については明確な根拠を見つけることができなかったため、指標の名前から推測して、おそらくこの指標はこれだろうというので割り当てて書いている。
何故というとAPIレスポンスの仕様書が何処にあるかわからず、Claude Opus 4.7に聞いてもデッドリンクになった仕様書を提示され、後はソースコードを読めと言われたため、わからないのだ。ソースコードなんか一々読んでられない。しかも嘘を教えられたため、自力で解釈した。
さて、処理時間についてだが、これはOllamaよりllama.cppのほうが圧倒的に早いことが判明した。また、ついでに言うとOllamaはどのモデルを実行してるのかが不明なため、単純比較ができない。
またリソース消費を見る感じ、OllamaはCPU・GPU共に遊ばせていたので、これが処理が遅い原因になっていた可能性がある。llama.cppはマニュアルでそのあたりをうまくやっているので早かったのだろう。
生成品質としては前回とそこまで変わらない気がしたが、質問を一回投げているだけなので、正直なところちゃんとした品質を確かめるには叩きまくる必要はあると思う。面倒なのでそこまではしてない。
おまけ:Poe上のQwen3.6-Plus
Qwen3.6-Plusはクラウド専用モデルのため、ローカルでは動かないが、動かしてみた感じ大分品質は良さそうに思った。少なくともローカルモデルのように目立ったハルシネーションは見られない。

あとがき
一般的なマシンで動くローカルLLMは、まだそれなりという感じの次元だが、Qwen3と比べると3.6は気持ち品質が上がったように感じた。とはいってもLLMはコンテキストがある状態で質問したり、コーディングさせたりしないと真価がわからないので、今回のように「神戸市について教えて」と聞くだけではあまり意味のある結果にはならないので、あくまで参考値くらいだろう。
取り敢えずまともなモデルはOpenAIもQwenもクラウドにあって、配布されているモデルは劣化版というのが分かったのが今日の収穫だったように思う。
Qwen公式の比較表を見る限り、Qwen3.6-35B-A3BはClaude Sonnet 4.5よりは賢いようだ。ただSonnetは個人的にはもう使っておらず、レートリミットがない環境で使っているのもあり、もっぱらOpus 4.7しか使っていないので、Sonnet 4.5を超えたところで微妙な感じは否めない。4.5は個人的にERPをするときにOpus 4.7, Sonnet 4.6, Opus 4.6でも返事をしなくなったときに4.5を叩き、その次のターンでOpus 4.6→Sonnet 4.6→Opus 4.7という流れで回帰させるのに使うことが多い。これは何をしているかというとSonnet 4.5の検閲が緩いのを逆手にとって、上位バージョンを騙すためのコンテキストを書かせているわけだ。
Sonnet 4.5が出た時は割と重宝していた記憶もあるのだが、Opus 4.7が優秀なので、もうまともな用途ではOpus 4.7以外全く使わなくなった。Opus 4.6も悪くはないと思うので、Opus 4.6くらいまでローカルLLMが進歩してくれたら助かるところである。
ひとまず今回の収穫はQwen3.6-35B-A3Bという昨今注目されているモデルが、特にメモリの増設なしでも動いた上に、VRAMを使わずRAMだけで実用速度で走らせることができたことだ。
クラウドLLMは高いのでローカルLLMで解決できるようになれば、それに越したことはない。
余談だがQwen3.6-35B-A3Bは検閲モデルだがQwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressiveという無検閲モデルがあり、ERPが機能することを軽く確認している。弾かれないこと程度しか確認してないので品質は謎いが、テストで叩いた感じはそこそこの内容を出してくれたと思う。少なくともGPT-4やGrokよりはよいと思うので、お金を節約したい人にはオススメかもしれない。
2026/05/11(月)Mastodon周りのメトリクス収集メモ
更新日:
投稿日:
投稿日:
確認環境
| Env | ver |
|---|---|
| nginx | 1.26.1 |
| Apache2 | 2.4.58 |
| PostgreSQL | 16.13 |
| Redis | 7.0.15 |
| Mastodon | 4.5.9 |
| Prometheus | 3.5.0 |
Apache2
# 取得
wget https://github.com/Lusitaniae/apache_exporter/releases/download/v1.0.12/apache_exporter-1.0.12.linux-amd64.tar.gz
tar xvfz apache_exporter-1.0.12.linux-amd64.tar.gz
# binを配置
sudo cp apache_exporter-1.0.12.linux-amd64/apache_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep apache_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/apache_exporter.service
[Unit]
Description=Prometheus Apache Exporter
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
ExecStart=/usr/local/bin/apache_exporter --scrape_uri=http://[::]:ここにポート番号/server-status?auto
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now apache_exporter
# 起動確認
curl "http://[::1]:9117/metrics"
# 掃除
rm -Rf apache_exporter-1.0.12.linux-amd64 apache_exporter-1.0.12.linux-amd64.tar.gz
PostgreSQL
# 取得
wget https://github.com/prometheus-community/postgres_exporter/releases/download/v0.19.1/postgres_exporter-0.19.1.linux-amd64.tar.gz
tar xvfz postgres_exporter-0.19.1.linux-amd64.tar.gz
# binを配置
sudo cp postgres_exporter-0.19.1.linux-amd64/postgres_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep postgres_exporter
# 監視ユーザーの作成
sudo -u postgres psql
CREATE USER postgres_exporter WITH PASSWORD 'ここにパスワード';
ALTER USER postgres_exporter SET SEARCH_PATH TO postgres_exporter,pg_catalog;
GRANT pg_monitor TO postgres_exporter;
quit
# 監視情報の作成
echo 'DATA_SOURCE_NAME="postgresql://postgres_exporter:ここにパスワード@localhost:5432/postgres?sslmode=disable"' | sudo tee /etc/default/postgres_exporter
sudo chown root:root /etc/default/postgres_exporter
sudo chmod 600 /etc/default/postgres_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/postgres_exporter.service
[Unit]
Description=Prometheus PostgreSQL Exporter
After=network.target postgresql.service
Wants=postgresql.service
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
EnvironmentFile=/etc/default/postgres_exporter
ExecStart=/usr/local/bin/postgres_exporter \
--web.listen-address=[::]:9187
Restart=on-failure
RestartSec=5
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now postgres_exporter
# 起動確認
curl "http://[::1]:9187/metrics"
# 掃除
rm -Rf postgres_exporter-0.19.1.linux-amd64 postgres_exporter-0.19.1.linux-amd64.tar.gz
Redis
# 取得
wget https://github.com/oliver006/redis_exporter/releases/download/v1.82.0/redis_exporter-v1.82.0.linux-amd64.tar.gz
tar xvfz redis_exporter-v1.82.0.linux-amd64.tar.gz
# binを配置
sudo cp redis_exporter-v1.82.0.linux-amd64/redis_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep redis_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/redis_exporter.service
[Unit]
Description=Prometheus Redis Exporter
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
ExecStart=/usr/local/bin/redis_exporter --redis.addr=redis://localhost:6379
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now redis_exporter
# 起動確認
curl "http://[::1]:9121/metrics"
# 掃除
rm -Rf redis_exporter-v1.82.0.linux-amd64 redis_exporter-v1.82.0.linux-amd64.tar.gz
Mastodonの組み込みExporter
.env.productionに以下を追加MASTODON_PROMETHEUS_EXPORTER_ENABLED=true MASTODON_PROMETHEUS_EXPORTER_SIDEKIQ_DETAILED_METRICS=trueデーモンを作る
cat <<'EOF' | sudo tee /etc/systemd/system/mastodon-prometheus-exporter.service [Unit] Description=mastodon-prometheus-exporter After=network.target [Service] Type=simple User=mastodon WorkingDirectory=/home/mastodon/live Environment="RAILS_ENV=production" ExecStart=/home/mastodon/.rbenv/shims/bundle exec prometheus_exporter -b "::" -p 9394 Restart=always [Install] WantedBy=multi-user.target EOF # デーモンの有効化 sudo systemctl daemon-reload sudo systemctl enable --now mastodon-prometheus-exporter- 起動確認
curl "http://[::1]:9394/metrics" # Streamingはv4でしかlistenしてないので[::1]は諦める curl "http://localhost:5001/metrics"
2026/05/11(月)自宅サーバーに雑に監視を入れた時にやったこと
更新日:
投稿日:
投稿日:
Ubuntuのネイティブ環境にPrometheusとGrafanaをIPv6スタックで導入したの続き。
ちまちまやってて記憶が飛びまくってるので抜け漏れがあるかもしれないが、吐き出しておかないと記憶が散逸するので、一度書き留めておく。
やったこと
LokiとFluentBitを入れてnginxのログをGrafanaで見れるようにする。
環境セットアップ
ここでは例示のためにLokiのlistenポートは9100とする。
Loki
確認環境
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Loki | 3.5.9 |
インストール
- リリース一覧からLokiのバイナリを探す。CLIとかではなく、Loki単品を探す
- インストールコマンドを流す
wget https://github.com/grafana/loki/releases/download/v3.5.9/loki_3.5.9_amd64.deb sudo dpkg -i loki_3.5.9_amd64.deb rm loki_3.5.9_amd64.deb - 後述する設定を行う
- サービスの起動と確認をする
sudo systemctl start loki systemctl status loki
設定
/etc/loki/config.ymlを開き、IPv6でListenし、ポート番号が9100となるようにする。中身はデフォルトの設定の改編。
auth_enabled: false
server:
http_listen_port: 9100
common:
ring:
instance_addr: "::"
kvstore:
store: inmemory
replication_factor: 1
path_prefix: /tmp/loki
schema_config:
configs:
- from: 2020-05-15
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
storage_config:
filesystem:
directory: /tmp/loki/chunks
参考
FluentBit
確認環境
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| FluentBit | 4.2.2 |
インストール
- インストールコマンドを流す
# FluentBitのGPGキーをキーリングに追加 sudo sh -c 'curl https://packages.fluentbit.io/fluentbit.key | gpg --dearmor > /usr/share/keyrings/fluentbit-keyring.gpg' # OSコードの取得 codename=$(grep -oP '(?<=VERSION_CODENAME=).*' /etc/os-release 2>/dev/null || lsb_release -cs 2>/dev/null) # OSコードをもとにAPTリストへ追加 echo "deb [signed-by=/usr/share/keyrings/fluentbit-keyring.gpg] https://packages.fluentbit.io/ubuntu/$codename $codename main" | sudo tee /etc/apt/sources.list.d/fluent-bit.list # パッケージリストの更新 sudo apt update # Fluent Bitのインストール sudo apt install fluent-bit - 後述する設定を行う
- DB配置場所を作成し、サービスの起動と確認をする
# DB配置場所の作成 /var/lib/fluent-bit/ # デーモンの開始 sudo systemctl start fluent-bit # デーモンの起動確認 systemctl status fluent-bit
設定
/etc/fluent-bit/fluent-bit.confを開きファイル末尾に以下を足す。
# nginx access log
[INPUT]
name tail
path /var/log/nginx/access.log
parser json
tag nginx.access
db /var/lib/fluent-bit/nginx-access.db
refresh_interval 5
# nginx error log
[INPUT]
name tail
path /var/log/nginx/error.log
tag nginx.error
db /var/lib/fluent-bit/nginx-error.db
refresh_interval 5
# Loki へ出力
[OUTPUT]
name loki
match nginx.*
host ::1
port 9100
labels job=nginx, log_type=$TAG[1]
設定解説
今回の設定についての説明であって汎用性は考慮していない。
[INPUT],[OUTPUT]- 入力か出力か
name- 利用するプラグインの名前
- 入力はdata-pipeline/inputs、出力はdata-pipeline/outputsに定義されている
- ファイルから拾う場合は
tail - lokiに飛ばす場合は
loki
- 利用するプラグインの名前
path- 入力ファイルのパス
tag- 出力で引っ掛けるときの名前
db- ログファイルをどこまで読んだかを記録する
match- ここにマッチしたtagが出力対象になる
host- Lokiのホスト
port- Lokiのポート
labels- Grafanaで引っ掛けるときのラベル
nginx
確認環境
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| nginx | 1.26.1 |
設定
nginxの標準ログでは得られるものが少ないので色々見れるようにする。ついでにjson形式にする。
/etc/nginx/nginx.confを開きログ設定を以下のようにするlog_format main_json escape=json '{' '"time":"$time_iso8601",' '"remote_addr":"$remote_addr",' '"remote_port":"$remote_port",' '"request_id":"$request_id",' '"scheme":"$scheme",' '"server_name":"$server_name",' '"server_port":"$server_port",' '"request_method":"$request_method",' '"request_uri":"$request_uri",' '"server_protocol":"$server_protocol",' '"status":$status,' '"body_bytes_sent":$body_bytes_sent,' '"bytes_sent":$bytes_sent,' '"request_length":$request_length,' '"request_time":$request_time,' '"http_referer":"$http_referer",' '"http_user_agent":"$http_user_agent",' '"ssl_protocol":"$ssl_protocol",' '"ssl_cipher":"$ssl_cipher",' '"connection":"$connection",' '"connection_requests":"$connection_requests"' '}'; access_log /var/log/nginx/access.log main_json;- nginxを再起動する
sudo systemctl restart nginx
Grafana
確認環境
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Grafana | v12.1.1 |
- Grafanaのダッシュボードを開く
- 左のグローバルナビからConnections→Add new connectionでLokiを追加する
- URLを
http://[::]:9100で指定する - Explorerを開きLokiを選び「Go queryless」を押すとLokiの中身が見れる