普段でWeb系のコードを書いているときに、こういうのがよいのではないか?と考えていることを雑に書いてゆく。いわゆるクラスを使わず関数を主体にして実装するなんちゃって関数型モデルみたいなやつの話。雑に書いているのでところどころ変なかもしれない。コードはNext.jsを題材にして書いている。
端的に言うとSOLID を軸に、適切にDRY 、KISS 、YAGNI といった一般的な設計原則を織り込み、MVC のように役割分担のあるアーキテクチャを利用することや、実装方式を統一することを意識している。
実装方式、コーディングスタイルを統一することで、微妙な書き方の差異に起因する不具合や、レビュー時のコスト、新人が来たときの迷いを減らせる。恐らくこれこそが最も重要な設計原則だと思う。
例えば以下のコードは書き方は違うがやりたいことは似ている処理群だ。もしチームに新人が来た場合、新人はどちらを書けばよいだろうか?レビューの時に複数の実装パターンが混ざったときにレビュアーはどう対応すればいいだろうか?
// undefinedの判定方法の違い。よほど特殊なことをしているのでなければ、基本的に後者でいい
if (typeof hoge === 'undefined') { }
if (hoge === undefined) { }
// 関数の定義方法の違い。どちらかに統一するほうが望ましい
function func1(param: T) { }
const func1 = (param: T) => {}
// 仮引数の定義方法の違い。これは分割代入とそれ以外で致命的に振る舞いが変わることがあるので統一することが望ましい
const func2 = ({ hoge, piyo }: { hoge: string, piyo: number }) => {}
const func2 = (param: { hoge: string, piyo: number }) => {}
type Func2Param = {
hoge: string;
piyo: number;
}
const func2 = (param: Func2Param) => {}
何よりこれらの処理は同じような処理に見えて、微妙に振る舞いが変わるものがある。それを意識せずコードスタイルとして表現していた場合に不具合を引き起こすトリガーになりやすい。特に分割代入はオブジェクトの参照が切れるので予期せぬ動作になりやすいし、関数のスコープが長くなってきたときに由来が解りづらくなるケースがある。逆に分割代入をしないことによって変数名が冗長になることもある。
こういった問題を解決するために、コードの書き方をあらかじめチームで決めておくのがよい。特にチーム開発でコードの書き方に秩序がないプロジェクトは品質が低い傾向があると感じる。例えば車のタイヤを全て別のメーカーにしていても車は走行できるが、基本的にメーカーが違う場合、品質などの差異があるので、追々予期せぬ問題が発生する可能性がある。それと同じ問題がコードにもあると私は考えている。
他にも同じことがしたいのに複数の実装方法があるとgrepしづらかったり、直感的ではないなど、コードを読んだ人間の認知負荷の増大に繋がるため、基本的には統一されていたほうがよいだろう。
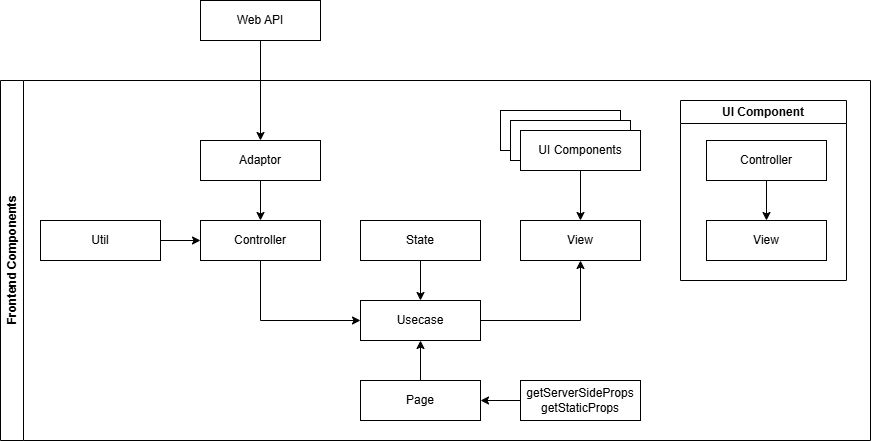
私が普段考えているレイヤリングはMVCとClean Architectureを足して二で割ったようなものだ。DDDや厳密なClean Arctectureだと複雑で重くなりがちなので、このくらいが丁度いいのではないかと考えている。これでも十分複雑なのは承知している。
コンポーネント
役割
Adaptor
APIコールなど、外部と接続するためのアダプタ関数。呼び出し処理以外を一切含まない。
Util
全体的な共通処理や、画面単位の細かいロジック類
Controller
画面で利用するイベントコールバック処理。useEffect()みたいなのもここ
State
画面で利用する状態
View
画面のビュー、ほぼ純粋なJSX/TSXで、booleanによる表示分岐のうち、単純なもののみ扱う。ネストしたり、複合条件を使った分岐は扱わず、必要に応じてUI Components側に移譲する
UI Components
画面のビューで利用するUI部品、状態はすべてprops経由で受け取り、自身では持たない
Usecase
Pageコンポーネントに埋め込む存在。画面のController, State, Viewの繋ぎ合わせと、Pageコンポーネントから来たgetServerSideProps()やgetStaticProps()の結果を適切なコンポーネントに注入する
Page
ページコンポーネント。Usecaseコンポーネントの埋め込みとgetServerSideProps()やgetStaticProps()の呼び出しのみを行う。
getServerSideProps
getServerSideProps()やgetStaticProps()で処理するコードを書く
リスコフの置換原則と、インターフェース分離の原則については、今回のケースでは無視でいいと思っている。
原則
効能
単一責任の原則
関数の実装を単一責務として切り出すことで、関数の肥大化を防げ、再利用性を高めることができるほか、単体テストが書きやすくなる
開放閉鎖の原則
関数のインターフェースを抽象化し、不変のものとすることで仕様変更などの変化に対応しやすくなる
依存性逆転の原則
その関数に必要な依存性をインターフェース経由で注入することで、関数内の処理が関数本体に依存しなくなり、疎結合になるほか、注入する依存性をモックなどに変えることでテストが容易になる
一つの関数には一つの責務だけを持たせようという原則だ。
一例としてReactでよくみられるreducerは以下のように書ける。これはreducerはaction.typeに応じた関数を呼び出すことを責務として、実際の処理は関数に移譲するといった内容だ。
const reducer = (state, action) => {
switch (action.type) {
case 'update_account':
updateAccountProc(state, action.payload);
break;
...
}
}
この実装であればreducer関数のテストは呼び出す関数をすべてモックしておき、action.typeに応じた関数が、想定通りの引数で呼ばれているかどうかを確認するだけでいい。各関数は関数単体でテストが書けるのでシンプルだ。
もしこれが関数呼び出しではなく、処理がベタで書いてあると単体の規模が大きくなり、コードの見通しが悪くなり、比例してテストコードも長くなり、個人的にはあまりよくないと思っている。コードの見通しは良いほうがよいし、責務ごとに関数を切ることでコードマージ時のコンフリクトの規模を抑えられることや、Feature flagを導入しやすくなるなど、利点は多いと思う。
欠点としては細切れになることによって、パッと見何をしているかわかりづらくなることがあると思うが、適切に抽象化し、関数名をちゃんとつけていれば基本的にそこは考慮しなくてよいと考えている。
この原則は拡張に対しては開かれており、修正に対しては閉じられていないといけないということだ。
例えば以下のコンポーネントではUsernameという単語がAccountNameに代わったときにPropsを書き換える必要があるが、もしもuserNameというワードを使わずにonChangeやvalueといった抽象的な用語にしておけば、変更を不要にできる。
type Props = {
onUserNameChanged: (username: string) => void;
userName: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
props.onUserNameChanged(event.target.value);
};
return <input type="text" onChange={onChange} value={props.userName} />;
}
多くのライブラリやAPIではメソッド名やプロパティ名は汎用的な名称になっていることが多く、アップデートで名前が破壊されることはそこまで多くない。こういった風に実装しておくことで内部実装への影響なく処理ができるという寸法だ。
これは下位コンポーネントに実装を持たせず、上位コンポーネントから中小を介して実装を注入する原則だ。
例えば以下のような実装がある場合、「この辺りに長い色んな処理があるものとする」の部分を仕様変更などで書き換えないといけなくなることがある。
type Props = {
onChange: (value: string) => void;
value: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
/**
* この辺りに長い色んな処理があるものとする
*/
props.onChange(event.target.value);
/**
* この辺りに長い色んな処理があるものとする
*/
};
return <input type="text" onChange={onChange} value={props.value} />;
}
しかし、props.onChangeの中に前後の処理を挟んでいれば、これを回避することができるし、onChangeの中に処理がうじゃうじゃあるのも責務として過剰だと思うので、親からonChangeに対し何かしらの処理をすることが自明な関数を注入することで、こういった問題を回避できる。
この原則については、基本的に過度に意識する必要はなくシステム全体の共通部品以外は二重実装を許容して構わないと考えている。
これは余りにもDRYにしすぎると、仕様変更などで影響箇所が広がりすぎて修正が困難になるからというのと、共通部品が多すぎると探すのが大変で、最悪自力で実装されるケースもあるためだ。
程度問題ではあるが、DDDのような冗長で難解な設計原則は避け、ある程度単純なものにしたほうがいいというのは思っている。
べた書きをすることでコードジャンプが減って見通しがいいという意見は行き過ぎだと考えている。
これは技術選定フェーズで主に使うもので、何かの技術を入れるとき、その技術である必要がなければ使わないのがよいと考えている。
例えばWeb画面からAPIを叩くときにGraphQLを採用するケースがよくあると思うが、RESTやWebAPIで済むならそちらのほうがよい可能性がある。
GraphQLはWeb標準ではなく、ライブラリによって実装もまちまちで、複雑な仕組みが絡み合っており、全容を理解するのはなかなか難しいうえに、HTTPの上にあるため、使いこなすためには基礎の理解が必要だ。スキーマ設計も難しく、単純にやるとWebAPIと特に変わらないものができてしまう。そう考えたときに、絶対にGraphQLでないといけないというケースがないのであれば、より簡単な技術を使ったほうがよいと思っている。
複雑なものを作っている時間で休憩でもしたほうが頭がすっきりするだろう。
これはAPI通信など、外部から貰ってきたデータがあったときに、内部向けにデータ変換を行うということだ。
例えばAPIからisHoge, isPiyo, isFugaというデータが来るパターンがあり、この三つのフィールドはいずれか一つしかtrueにならないケースがあるとして、画面ではこれに対応するラジオボタンを持っている場合、trueだった項目を文字列として持っておくと便利だ。こういった場合に、使う場所で毎回変換処理を挟むと将来的に修正漏れが起きるリスクが増えたり、個々の場所で微妙に違う実装になって実装方式に統一がなくなったり。そもそも出現箇所が増えて認知負荷が増えるなど厄介だ。
これを防ぐために、一番最初にレスポンスを受けた時点で変換処理を挟み、以後それを引き回すというのがよいと考えている。APIに戻すときはisHoge, isPiyo, isFugaのフォーマットに戻す必要があるのが、その場合はAPIを叩く前に逆変換の処理を挟むと、データ変換処理が入り口と出口だけに存在することになり、データフローがシンプルになる。
他にもAPIと画面の境界でENUMの内容を変換する処理を入れておくとAPI側がしれっとリファクタなどで名称変更をしたときに、異常値を検出しやすくなるし、画面の開発者は基本的にAPIのことを考えなくてもよくなるので楽になると思っている(境界部分を設計する人間だけが考えればよくなる)
雑に書こうとしたものの、結局まとまりきらず、まとめようとしても永遠に終わらなかったので一旦吐き出してみた。多分全部話そうとすると発散しすぎて収拾がつかなくなるので、個々について深ぼったことを書いて、最後にそれをまとめたほうがいいのかもしれない。
といっても何を書くかが問題になってくるので、日々思ったことを雑にアウトプットしつつ、あとで振り返ってまとめていくのがいいのかもしれない。