2026/07/08(水)nginxにクライアント証明書認証の設定をした
投稿日:
管理領域など、自分以外などにアクセスを許可したくない場所にパスフレーズ付きクライアント証明書で制限を掛け、自分以外アクセスできないようにしたので、そのログ。
確認環境
サーバーと証明書作成環境
| Env | Ver |
|---|---|
| OS | Ubuntu 24.04.4 LTS |
| nginx | 1.24.0 |
| OpenSSL | 3.0.13 30 |
クライアント証明書を設定してアクセスした環境1
| Env | Ver |
|---|---|
| OS | Windows 11 Pro 25H2 (OSビルド 26200.8783) |
| クライアント | Microsoft Edge バージョン 150.0.4078.48 |
クライアント証明書を設定してアクセスした環境2
| Env | Ver |
|---|---|
| OS | Android 16 |
| クライアント | Microsoft Edge バージョン 149.0.4022.105 |
手順
CAやクライアント証明書の作成
ここから行うコマンドはその全てでパスワード入力プロンプトが出るため、個別に流す必要がある。
- 判別しやすくするためにファイル名の頭に付与する接頭辞を決める
file_prefix=lyco_ CA(認証局)を作成する
- CAの秘密鍵の作成
# -pass=pass:<PASSWORD>でもパスワードを掛けられるが平文になるらしいので-aes-128-cbcでパスワードを掛ける openssl genpkey \ -algorithm EC \ -pkeyopt ec_paramgen_curve:P-256 \ -out ${file_prefix}ca.key \ -aes-128-cbc CAの証明書署名要求の作成
# 適当に好きな値を設定(以下は私の設定例) # 最低限CommonNameさえあればあとは何でもいいらしい? CountryCode=JA # 国コードを指定するっぽいが多分何を指定してもいい Province=Hyogo # たぶん県を指定するっぽいが多分何を指定してもいい Location=Kobe # たぶん市区町村を指定するっぽいが多分何を指定してもいい Organization="Lycolia Rizzim" # 組織を設定を指定するっぽいが多分何を指定してもいい CommonName=lycolia.info # FQDNを指定するっぽいが多分何を指定してもいい # CA証明書署名要求作成 openssl req \ -new \ -key ${file_prefix}ca.key \ -out ${file_prefix}ca.csr \ -subj "/C=${CountryCode}/ST=${Province}/L=${Location}/O=${Organization}/CN=${CommonName}-CA"- CAの証明書の作成
openssl req \ -new \ -x509 \ -key ${file_prefix}ca.key \ -out ${file_prefix}ca.crt \ -subj "/C=${CountryCode}/ST=${Province}/L=${Location}/O=${Organization}/CN=${CommonName}-CA"
- CAの秘密鍵の作成
クライアント証明書作成
クライアントの秘密鍵の作成
# -pass=pass:<PASSWORD>でもパスワードを掛けられるが平文になるらしいので-aes-128-cbcでパスワードを掛ける openssl genpkey \ -algorithm EC \ -pkeyopt ec_paramgen_curve:P-256 \ -out ${file_prefix}client.key \ -aes-128-cbcクライアントの証明書署名要求の作成
openssl req \ -new \ -key ${file_prefix}client.key \ -out ${file_prefix}client.csr \ -subj "/C=${CountryCode}/ST=${Province}/L=${Location}/O=${Organization}/CN=${CommonName}-CLIENT"クライアント証明書の作成
openssl x509 \ -req \ -in ${file_prefix}client.csr \ -CA ${file_prefix}ca.crt \ -CAkey ${file_prefix}ca.key \ -CAcreateserial \ -out ${file_prefix}client.crt \ -subj "/C=${CountryCode}/ST=${Province}/L=${Location}/O=${Organization}/CN=${CommonName}-CLIENT"
- クライアントに食べさせる用の証明書を作る(PKCS12形式)
openssl pkcs12 \ -export \ -out ${file_prefix}client.pfx \ -inkey ${file_prefix}client.key \ -in ${file_prefix}client.crt CA証明書の配置
sudo mkdir /etc/nginx/ca sudo cp ${file_prefix}ca.crt /etc/nginx/canginxのsnippetsの作成
cat <<EOF | sudo tee /etc/nginx/snippets/ssl_verify_client.conf ssl_verify_client on; ssl_client_certificate "ca/${file_prefix}ca.crt"; EOF- 各vhostの設定に埋め込む。https環境でないと設定しても意味ないので注意
server { ... include snippets/ssl_verify_client.conf; ... } - 設定を再読み込み
sudo systemctl reload nginx - 疎通確認
curl -v \ --cert ${file_prefix}client.crt \ --key ${file_prefix}client.key \ --cacert ${file_prefix}ca.crt \ https://hoge.example.com/
WindowsのEdgeからアクセスする
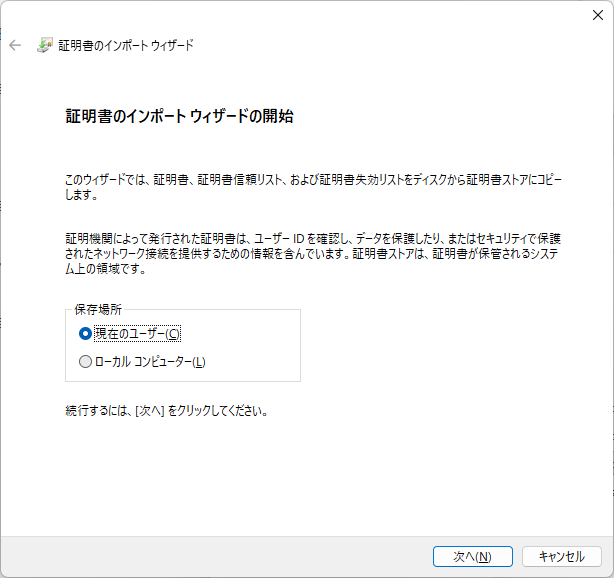
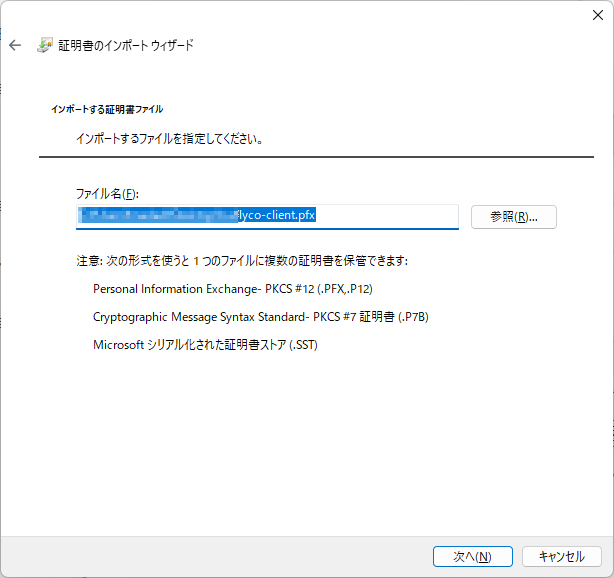
- 作成したPKCS12形式の証明書をWindowsにもってきてダブルクリックする。保存場所→現在のユーザーで次へ
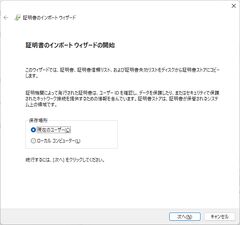
- 何もせず次へ
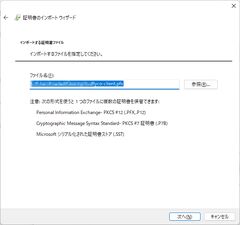
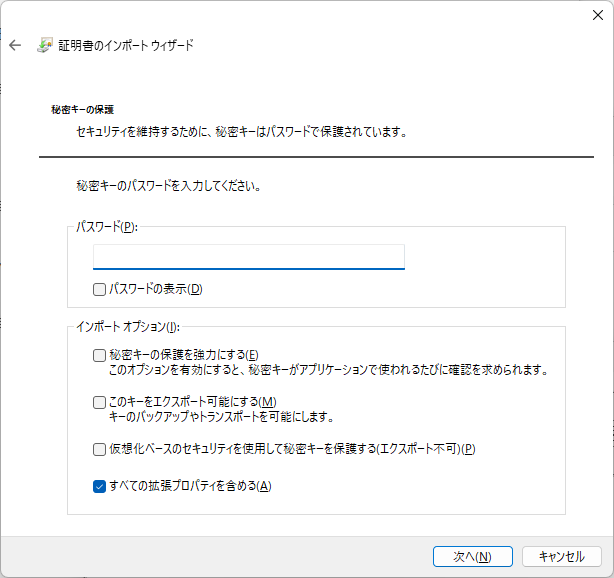
- パスワードを入力して次へ
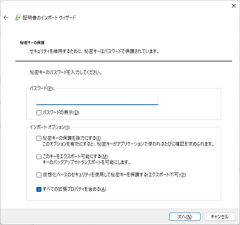
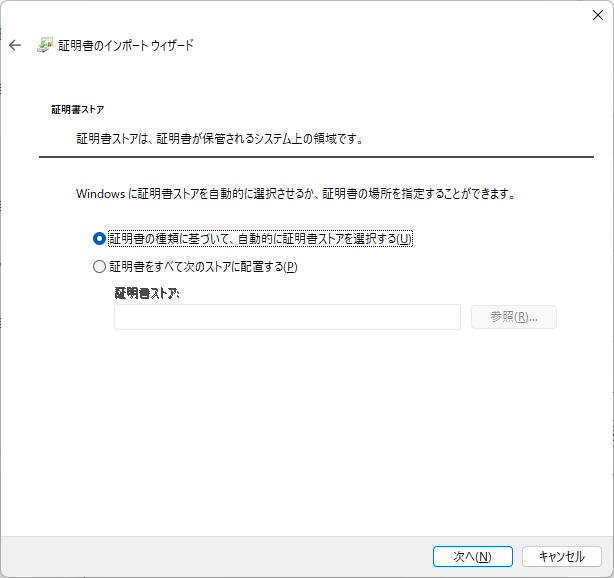
- 何もせず次へ
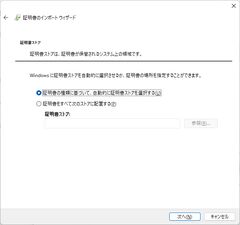
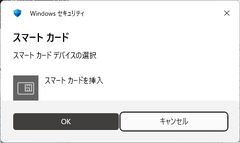
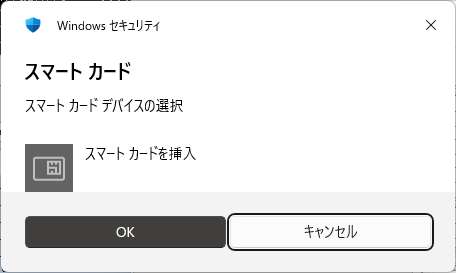
- スマートカードを挿入をキャンセルする
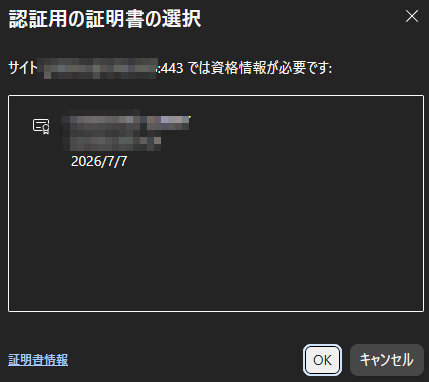
- プライベートモードでEdgeを開き設定したvhostにアクセスして証明書を選択しなかったときに400エラーが出ることを確認
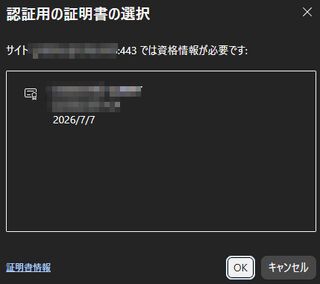
- プライベートモードを閉じて再度アクセスしたときに証明書を選択したときに正常にアクセスできることを確認
AndroidのEdgeから確認する
- 作成したPKCS12形式の証明書をAndroidにもってきて開く
- 適当にインポートする
- プライベートモードでEdgeを開き設定したvhostにアクセスして証明書を選択しなかったときに400エラーが出ることを確認
- プライベートモードを閉じて再度アクセスしたときに証明書を選択したときに正常にアクセスできることを確認
メモ
genrsaよりgenpkeyを使った方がいい
Generation of RSA Private Key. Superceded by genpkey.
トラブルシューティング
証明書の選択画面が出ない
httpsになってないと出ない。
http://localhostとかhttp://dev.localみたいなアクセスをしていると出てこない。
HTTPSでアクセスしているのに400エラーが出る
CAの証明書とクライアントの証明書でCNの値が同じだと自己署名証明書扱いされて上手くいかないのでCNの値を変える。
今回手順に書いた内容ではCAとクライアント用でCNの値が相違するよう書いているので手順通りにしていれば起きない。
ED25519で証明書を作ったらなんか動かない
openssl genpkeyで-algorithm ed25519にするとEdgeは上手く解釈できないっぽいので-algorithm EC -pkeyopt ec_paramgen_curve:P-256として作る必要がある。
今回手順に書いた手順通りにしていれば起きない。
参考記事
- とほほのOpenSSL入門 - とほほのWWW入門
- OpenSSL Quick Reference Guide - digicert.com
- 自己署名でクライアント証明書の作成方法(オレオレ証明書) | VPS Life
- #google_vignetteによる全画面広告出るので注意
- Module ngx_http_ssl_module - nginx.org
- openssl-genpkey - OpenSSL Documentation - openssl.org