検索条件
タグで絞り込み
ジャンル::ベンチマーク(1)
ジャンル::自作PC(1)
ジャンル::自宅サーバー(3)
ソフトウェア(1)
ソフトウェア::Mastodon(1)
技術::LLM(1)
技術::監視(3)
全4件
(1/1ページ)
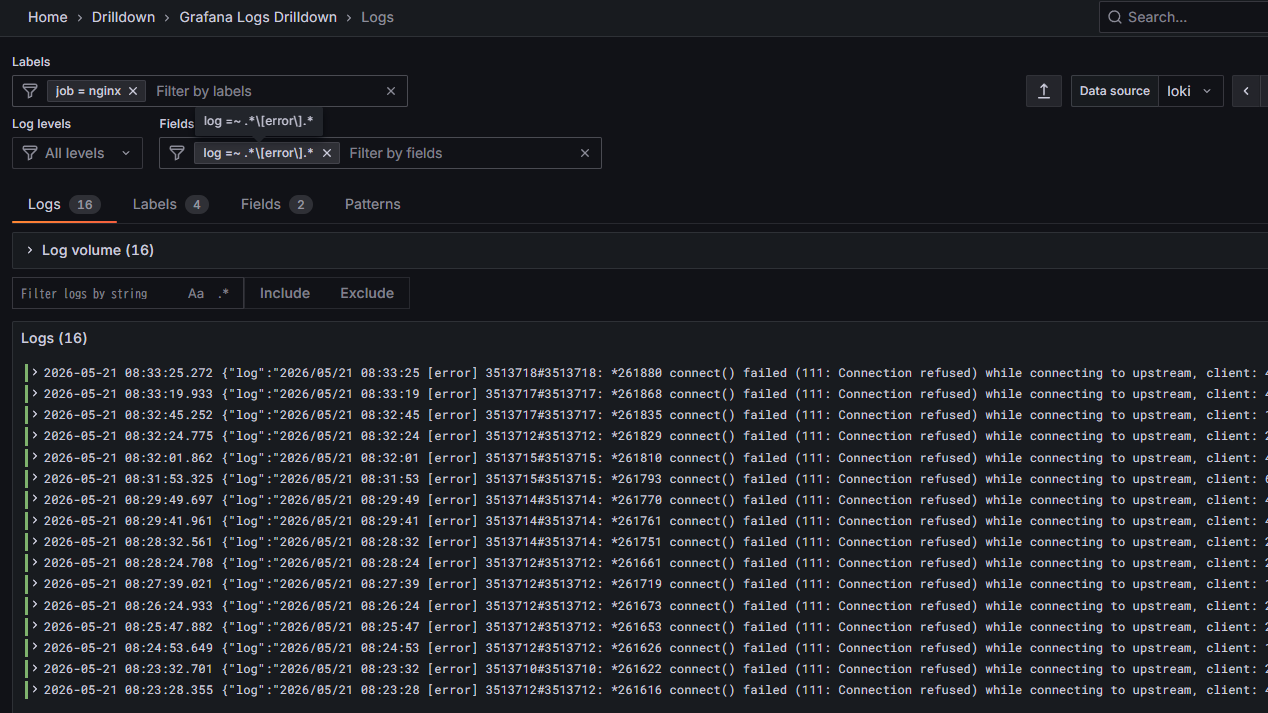
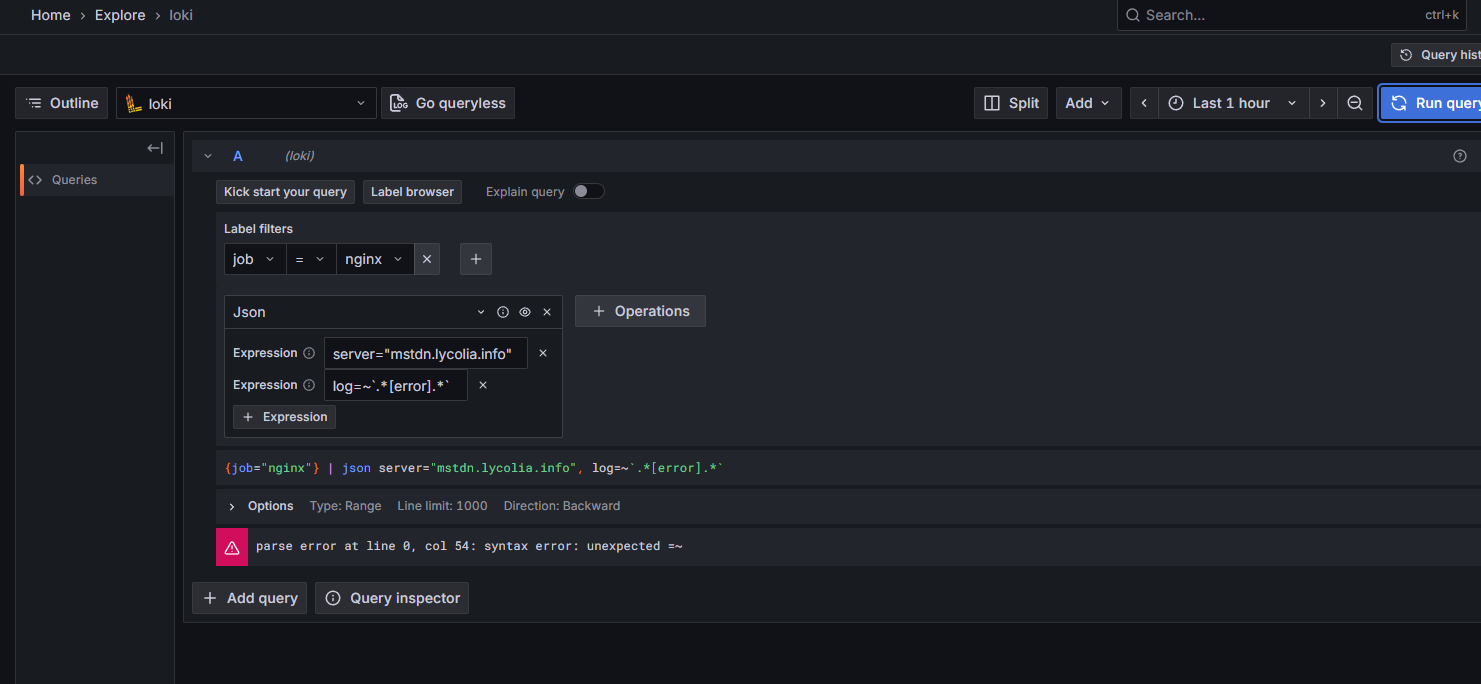
Grafana Logs Drilldownではフィルタ出来るのにExplore > Lokiでクエリを打ってもログを引けなかった。これを引けるようにするのが目的。
nginxのログをFluentBitで拾いLokiに送る構成。
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Loki | 3.5.9 |
| FluentBit | 4.2.2 |
| nginx | 1.26.1 |
| Grafana | v12.1.1 |
server: mstdn.lycolia.infoで[error]を含むものを検索する場合、こうしておくと引ける。要点はjson msg="log"で別名をつけること。logのままでは構文エラーになる。
{job="nginx"} |= `error` |= `server: mstdn.lycolia.info` | json msg="log" | msg=~`.*\[error\].*`
|= についてはQuery best practices | Grafana Loki documentationで、最初にラインフィルタをかけるとパフォーマンスが上がるということで付けている。error
server="mstdn.lycolia.info"を指定するとなぜかうまくいかなかった。
前回のマシンを更新したのでローカルLLMを軽くベンチマークしてみたでは生成速度だけを見れば十分実用ラインということを確認したが、品質が悪い問題があった。
そこで4月に出て、そこそこ評判を聞くQwen3.6がいかほどのものかというのを軽く試し、ついでにベンチマークもした。
CPU推論とGPU推論が分かれているが、これは初回ベンチマーク時にCUDAのDLLを入れ忘れていたため、GPU推論はDLLを入れてリトライした時の数値、CPU推論はDLLがない状態の数値で書いている。
| 種別 | デバイス |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5(DDR5-5600 16GB) * 4 |
| M/B | ASRock Z890 Pro RS |
実行環境はWindows 11。今回はllama.cppをメインで使っている。
| Env | Ver |
|---|---|
| llama.cpp | 9196 |
| Ollama | 0.24.0 |
| Open WebUI | 0.9.5 |
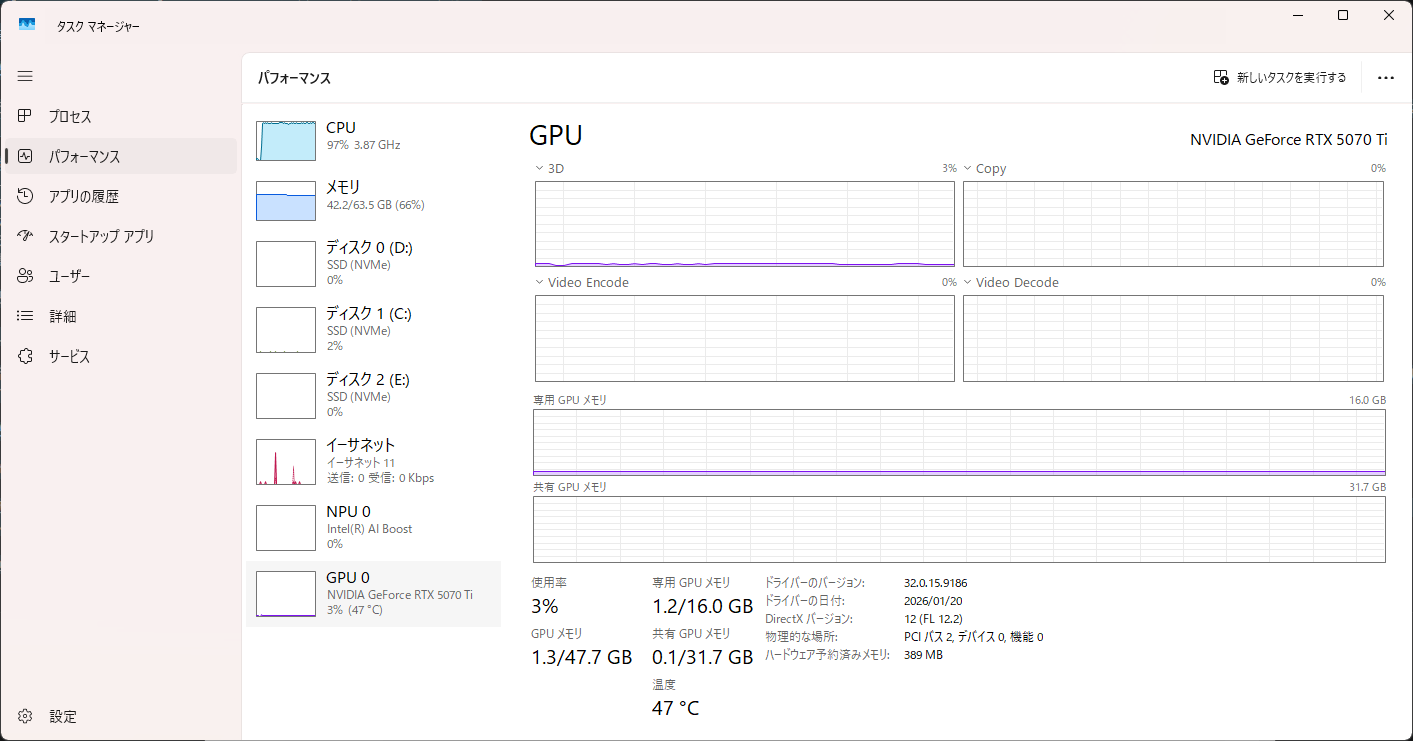
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 203.404 |
| prompt_per_token_ms | 14.528857142857143 |
| prompt_per_second | 68.82853827849993 |
| predicted_n | 1553 |
| predicted_ms | 94147.172 |
| predicted_per_token_ms | 60.622776561493886 |
| predicted_per_second | 16.495450335990974 |
| input_tokens | 14 |
| output_tokens | 1553 |
| total_tokens | 1567 |
リソース消費
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 103.612 |
| prompt_per_token_ms | 7.400857142857142 |
| prompt_per_second | 135.11948422962593 |
| predicted_n | 1554 |
| predicted_ms | 26037.862 |
| predicted_per_token_ms | 16.755380952380953 |
| predicted_per_second | 59.68231953913881 |
| input_tokens | 14 |
| output_tokens | 1554 |
| total_tokens | 1568 |
リソース消費
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 228.782 |
| prompt_per_token_ms | 16.34157142857143 |
| prompt_per_second | 61.19362537262546 |
| predicted_n | 1816 |
| predicted_ms | 119116.155 |
| predicted_per_token_ms | 65.59259636563877 |
| predicted_per_second | 15.24562306431063 |
| input_tokens | 14 |
| output_tokens | 1816 |
| total_tokens | 1830 |
リソース消費
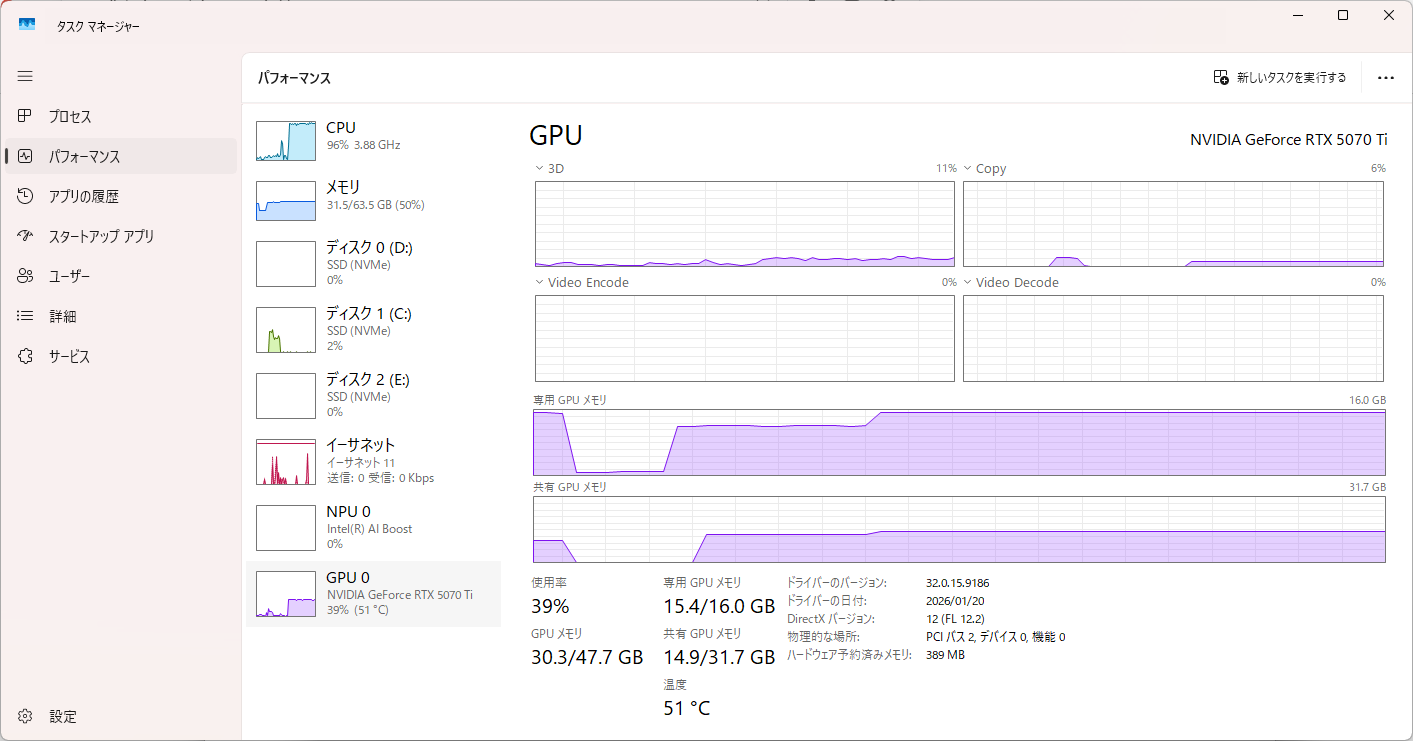
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 156.28 |
| prompt_per_token_ms | 11.162857142857144 |
| prompt_per_second | 89.58280010238033 |
| predicted_n | 1575 |
| predicted_ms | 30901.59 |
| predicted_per_token_ms | 19.620057142857142 |
| predicted_per_second | 50.96825114824189 |
| input_tokens | 14 |
| output_tokens | 1575 |
| total_tokens | 1589 |
リソース消費
Qwen3.6-35B-A3B-UD-Q8_K_XLを使用。
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし
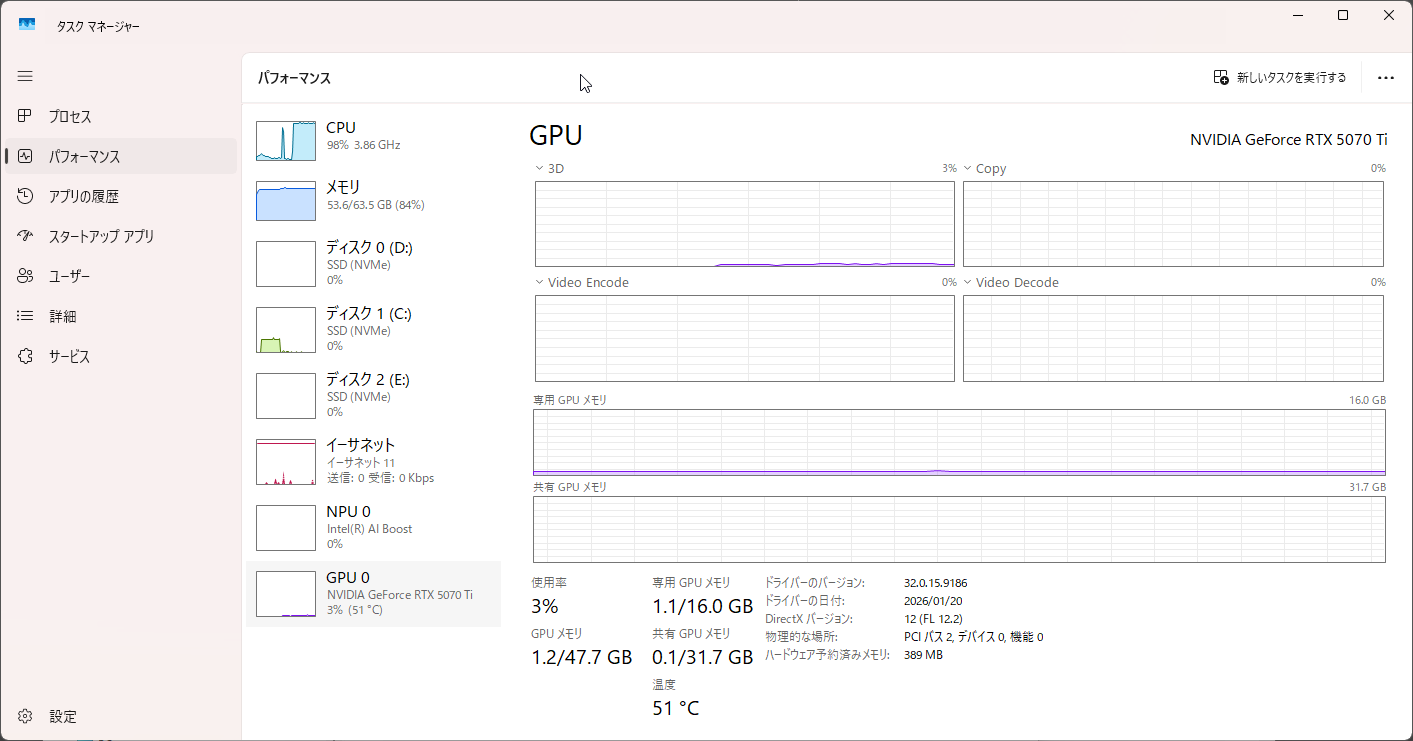
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 262.85 |
| prompt_per_token_ms | 18.775000000000002 |
| prompt_per_second | 53.262316910785614 |
| predicted_n | 1704 |
| predicted_ms | 119261.701 |
| predicted_per_token_ms | 69.98926115023474 |
| predicted_per_second | 14.287906223977135 |
| input_tokens | 14 |
| output_tokens | 1704 |
| total_tokens | 1718 |
リソース消費
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 190.329 |
| prompt_per_token_ms | 13.594928571428571 |
| prompt_per_second | 73.55684104892055 |
| predicted_n | 1829 |
| predicted_ms | 51098.747 |
| predicted_per_token_ms | 27.93807927829415 |
| predicted_per_second | 35.7934412755757 |
| input_tokens | 14 |
| output_tokens | 1829 |
| total_tokens | 1843 |
リソース消費
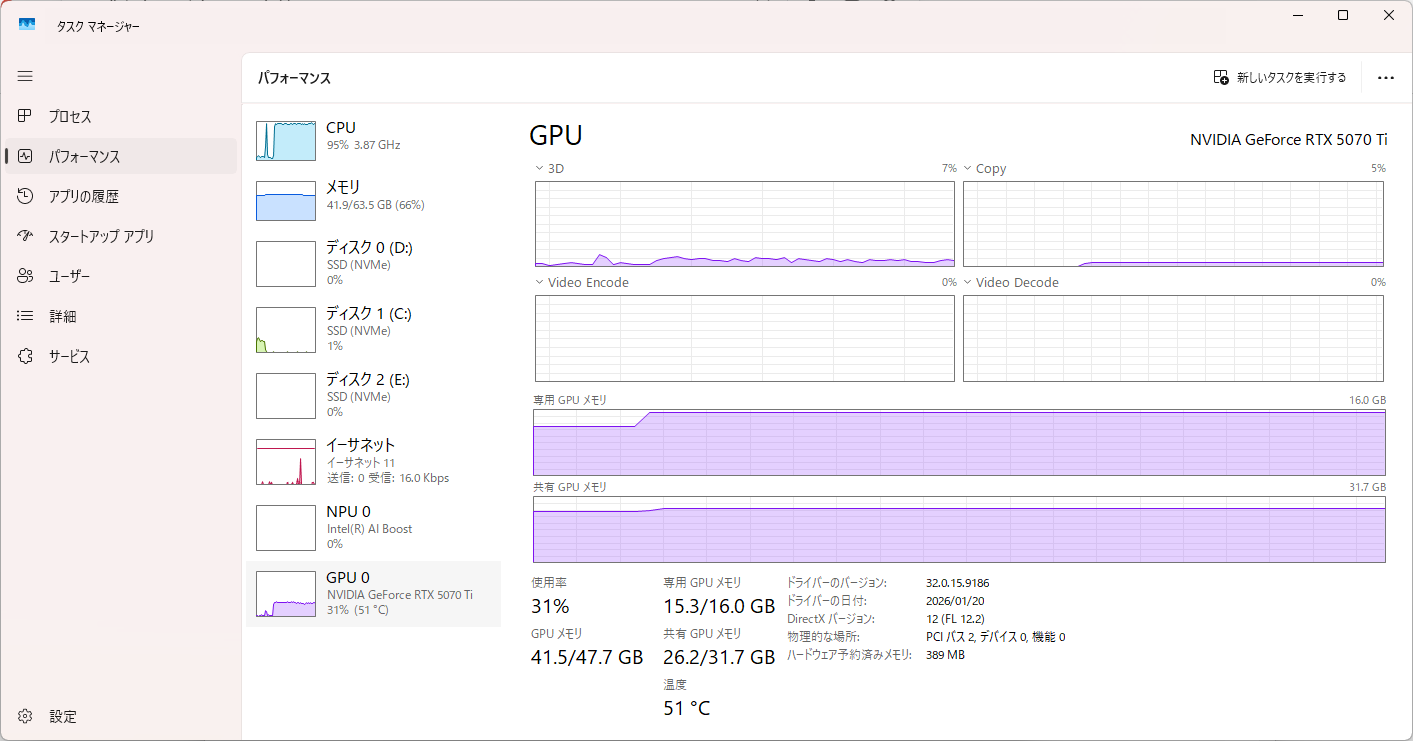
qwen3.6:35bを使用
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| input_tokens | 14 |
| output_tokens | 1364 |
| total_tokens | 1378 |
| prompt_tokens | 14 |
| completion_tokens | 1364 |
| response_token/s | 20.84 |
| prompt_token/s | 5.84 |
| total_duration | 126876747900 |
| load_duration | 58586625500 |
| prompt_eval_count | 14 |
| prompt_eval_duration | 2398703000 |
| eval_count | 1364 |
| eval_duration | 65458229300 |
| approximate_total | "0h2m6s" |
リソース消費
このコマンドはRTX 5070 Ti + 9800X3D running Qwen3.6-35B-A3B at 79 t/s with 128K context, the --n-cpu-moe flag is the most important part. |r/LocalLLaMAにあったものを利用している。
llama-server.exe ^
-m "ここにモデルファイルのパス" ^
--fit on ^
--fit-ctx 128000 ^
--fit-target 256 ^
-np 1 ^
-fa on ^
--no-mmap ^
--mlock ^
-b 2048 ^
-ub 2048 ^
-ctk q8_0 ^
-ctv q8_0 ^
--temp 0.6 ^
--top-p 0.95 ^
--top-k 20 ^
--min-p 0.0 ^
--presence-penalty 0.0 ^
--repeat-penalty 1.0 ^
--reasoning-budget -1 ^
--chat-template-kwargs "{\"preserve_thinking\": true}" ^
--host 0.0.0.0 ^
--port 8033
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 68.82 | 61.19 | 53.26 |
| 出力tok/s | 16.49 | 15.24 | 14.28 |
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 135.11 | 89.58 | 73.55 |
| 出力tok/s | 59.68 | 50.96 | 35.79 |
| 指標 | Ollama |
|---|---|
| 入力tok/s | 5.84 |
| 出力tok/s | 20.84 |
上の表の指標については明確な根拠を見つけることができなかったため、指標の名前から推測して、おそらくこの指標はこれだろうというので割り当てて書いている。
何故というとAPIレスポンスの仕様書が何処にあるかわからず、Claude Opus 4.7に聞いてもデッドリンクになった仕様書を提示され、後はソースコードを読めと言われたため、わからないのだ。ソースコードなんか一々読んでられない。しかも嘘を教えられたため、自力で解釈した。
さて、処理時間についてだが、これはOllamaよりllama.cppのほうが圧倒的に早いことが判明した。また、ついでに言うとOllamaはどのモデルを実行してるのかが不明なため、単純比較ができない。
またリソース消費を見る感じ、OllamaはCPU・GPU共に遊ばせていたので、これが処理が遅い原因になっていた可能性がある。llama.cppはマニュアルでそのあたりをうまくやっているので早かったのだろう。
生成品質としては前回とそこまで変わらない気がしたが、質問を一回投げているだけなので、正直なところちゃんとした品質を確かめるには叩きまくる必要はあると思う。面倒なのでそこまではしてない。
Qwen3.6-Plusはクラウド専用モデルのため、ローカルでは動かないが、動かしてみた感じ大分品質は良さそうに思った。少なくともローカルモデルのように目立ったハルシネーションは見られない。

一般的なマシンで動くローカルLLMは、まだそれなりという感じの次元だが、Qwen3と比べると3.6は気持ち品質が上がったように感じた。とはいってもLLMはコンテキストがある状態で質問したり、コーディングさせたりしないと真価がわからないので、今回のように「神戸市について教えて」と聞くだけではあまり意味のある結果にはならないので、あくまで参考値くらいだろう。
取り敢えずまともなモデルはOpenAIもQwenもクラウドにあって、配布されているモデルは劣化版というのが分かったのが今日の収穫だったように思う。
Qwen公式の比較表を見る限り、Qwen3.6-35B-A3BはClaude Sonnet 4.5よりは賢いようだ。ただSonnetは個人的にはもう使っておらず、レートリミットがない環境で使っているのもあり、もっぱらOpus 4.7しか使っていないので、Sonnet 4.5を超えたところで微妙な感じは否めない。4.5は個人的にERPをするときにOpus 4.7, Sonnet 4.6, Opus 4.6でも返事をしなくなったときに4.5を叩き、その次のターンでOpus 4.6→Sonnet 4.6→Opus 4.7という流れで回帰させるのに使うことが多い。これは何をしているかというとSonnet 4.5の検閲が緩いのを逆手にとって、上位バージョンを騙すためのコンテキストを書かせているわけだ。
Sonnet 4.5が出た時は割と重宝していた記憶もあるのだが、Opus 4.7が優秀なので、もうまともな用途ではOpus 4.7以外全く使わなくなった。Opus 4.6も悪くはないと思うので、Opus 4.6くらいまでローカルLLMが進歩してくれたら助かるところである。
ひとまず今回の収穫はQwen3.6-35B-A3Bという昨今注目されているモデルが、特にメモリの増設なしでも動いた上に、VRAMを使わずRAMだけで実用速度で走らせることができたことだ。
クラウドLLMは高いのでローカルLLMで解決できるようになれば、それに越したことはない。
余談だがQwen3.6-35B-A3Bは検閲モデルだがQwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressiveという無検閲モデルがあり、ERPが機能することを軽く確認している。弾かれないこと程度しか確認してないので品質は謎いが、テストで叩いた感じはそこそこの内容を出してくれたと思う。少なくともGPT-4やGrokよりはよいと思うので、お金を節約したい人にはオススメかもしれない。
| Env | ver |
|---|---|
| nginx | 1.26.1 |
| Apache2 | 2.4.58 |
| PostgreSQL | 16.13 |
| Redis | 7.0.15 |
| Mastodon | 4.5.9 |
| Prometheus | 3.5.0 |
# 取得
wget https://github.com/Lusitaniae/apache_exporter/releases/download/v1.0.12/apache_exporter-1.0.12.linux-amd64.tar.gz
tar xvfz apache_exporter-1.0.12.linux-amd64.tar.gz
# binを配置
sudo cp apache_exporter-1.0.12.linux-amd64/apache_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep apache_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/apache_exporter.service
[Unit]
Description=Prometheus Apache Exporter
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
ExecStart=/usr/local/bin/apache_exporter --scrape_uri=http://[::]:ここにポート番号/server-status?auto
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now apache_exporter
# 起動確認
curl "http://[::1]:9117/metrics"
# 掃除
rm -Rf apache_exporter-1.0.12.linux-amd64 apache_exporter-1.0.12.linux-amd64.tar.gz
# 取得
wget https://github.com/prometheus-community/postgres_exporter/releases/download/v0.19.1/postgres_exporter-0.19.1.linux-amd64.tar.gz
tar xvfz postgres_exporter-0.19.1.linux-amd64.tar.gz
# binを配置
sudo cp postgres_exporter-0.19.1.linux-amd64/postgres_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep postgres_exporter
# 監視ユーザーの作成
sudo -u postgres psql
CREATE USER postgres_exporter WITH PASSWORD 'ここにパスワード';
ALTER USER postgres_exporter SET SEARCH_PATH TO postgres_exporter,pg_catalog;
GRANT pg_monitor TO postgres_exporter;
quit
# 監視情報の作成
echo 'DATA_SOURCE_NAME="postgresql://postgres_exporter:ここにパスワード@localhost:5432/postgres?sslmode=disable"' | sudo tee /etc/default/postgres_exporter
sudo chown root:root /etc/default/postgres_exporter
sudo chmod 600 /etc/default/postgres_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/postgres_exporter.service
[Unit]
Description=Prometheus PostgreSQL Exporter
After=network.target postgresql.service
Wants=postgresql.service
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
EnvironmentFile=/etc/default/postgres_exporter
ExecStart=/usr/local/bin/postgres_exporter \
--web.listen-address=[::]:9187
Restart=on-failure
RestartSec=5
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now postgres_exporter
# 起動確認
curl "http://[::1]:9187/metrics"
# 掃除
rm -Rf postgres_exporter-0.19.1.linux-amd64 postgres_exporter-0.19.1.linux-amd64.tar.gz
# 取得
wget https://github.com/oliver006/redis_exporter/releases/download/v1.82.0/redis_exporter-v1.82.0.linux-amd64.tar.gz
tar xvfz redis_exporter-v1.82.0.linux-amd64.tar.gz
# binを配置
sudo cp redis_exporter-v1.82.0.linux-amd64/redis_exporter /usr/local/bin/
ls -la /usr/local/bin/ | grep redis_exporter
# デーモン作成
cat <<'EOF' | sudo tee /etc/systemd/system/redis_exporter.service
[Unit]
Description=Prometheus Redis Exporter
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/var/lib/prometheus
ExecStart=/usr/local/bin/redis_exporter --redis.addr=redis://localhost:6379
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now redis_exporter
# 起動確認
curl "http://[::1]:9121/metrics"
# 掃除
rm -Rf redis_exporter-v1.82.0.linux-amd64 redis_exporter-v1.82.0.linux-amd64.tar.gz
.env.productionに以下を追加
MASTODON_PROMETHEUS_EXPORTER_ENABLED=true
MASTODON_PROMETHEUS_EXPORTER_SIDEKIQ_DETAILED_METRICS=true
デーモンを作る
cat <<'EOF' | sudo tee /etc/systemd/system/mastodon-prometheus-exporter.service
[Unit]
Description=mastodon-prometheus-exporter
After=network.target
[Service]
Type=simple
User=mastodon
WorkingDirectory=/home/mastodon/live
Environment="RAILS_ENV=production"
ExecStart=/home/mastodon/.rbenv/shims/bundle exec prometheus_exporter -b "::" -p 9394
Restart=always
[Install]
WantedBy=multi-user.target
EOF
# デーモンの有効化
sudo systemctl daemon-reload
sudo systemctl enable --now mastodon-prometheus-exporter
curl "http://[::1]:9394/metrics"
# Streamingはv4でしかlistenしてないので[::1]は諦める
curl "http://localhost:5001/metrics"
Ubuntuのネイティブ環境にPrometheusとGrafanaをIPv6スタックで導入したの続き。
ちまちまやってて記憶が飛びまくってるので抜け漏れがあるかもしれないが、吐き出しておかないと記憶が散逸するので、一度書き留めておく。
LokiとFluentBitを入れてnginxのログをGrafanaで見れるようにする。
ここでは例示のためにLokiのlistenポートは9100とする。
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Loki | 3.5.9 |
wget https://github.com/grafana/loki/releases/download/v3.5.9/loki_3.5.9_amd64.deb
sudo dpkg -i loki_3.5.9_amd64.deb
rm loki_3.5.9_amd64.deb
sudo systemctl start loki
systemctl status loki
/etc/loki/config.ymlを開き、IPv6でListenし、ポート番号が9100となるようにする。中身はデフォルトの設定の改編。
auth_enabled: false
server:
http_listen_port: 9100
common:
ring:
instance_addr: "::"
kvstore:
store: inmemory
replication_factor: 1
path_prefix: /tmp/loki
schema_config:
configs:
- from: 2020-05-15
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
storage_config:
filesystem:
directory: /tmp/loki/chunks
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| FluentBit | 4.2.2 |
# FluentBitのGPGキーをキーリングに追加
sudo sh -c 'curl https://packages.fluentbit.io/fluentbit.key | gpg --dearmor > /usr/share/keyrings/fluentbit-keyring.gpg'
# OSコードの取得
codename=$(grep -oP '(?<=VERSION_CODENAME=).*' /etc/os-release 2>/dev/null || lsb_release -cs 2>/dev/null)
# OSコードをもとにAPTリストへ追加
echo "deb [signed-by=/usr/share/keyrings/fluentbit-keyring.gpg] https://packages.fluentbit.io/ubuntu/$codename $codename main" | sudo tee /etc/apt/sources.list.d/fluent-bit.list
# パッケージリストの更新
sudo apt update
# Fluent Bitのインストール
sudo apt install fluent-bit
# DB配置場所の作成
/var/lib/fluent-bit/
# デーモンの開始
sudo systemctl start fluent-bit
# デーモンの起動確認
systemctl status fluent-bit
/etc/fluent-bit/fluent-bit.confを開きファイル末尾に以下を足す。
# nginx access log
[INPUT]
name tail
path /var/log/nginx/access.log
parser json
tag nginx.access
db /var/lib/fluent-bit/nginx-access.db
refresh_interval 5
# nginx error log
[INPUT]
name tail
path /var/log/nginx/error.log
tag nginx.error
db /var/lib/fluent-bit/nginx-error.db
refresh_interval 5
# Loki へ出力
[OUTPUT]
name loki
match nginx.*
host ::1
port 9100
labels job=nginx, log_type=$TAG[1]
今回の設定についての説明であって汎用性は考慮していない。
[INPUT], [OUTPUT]
name
taillokipath
tag
db
match
host
port
labels
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| nginx | 1.26.1 |
nginxの標準ログでは得られるものが少ないので色々見れるようにする。ついでにjson形式にする。
/etc/nginx/nginx.confを開きログ設定を以下のようにする
log_format main_json escape=json
'{'
'"time":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"remote_port":"$remote_port",'
'"request_id":"$request_id",'
'"scheme":"$scheme",'
'"server_name":"$server_name",'
'"server_port":"$server_port",'
'"request_method":"$request_method",'
'"request_uri":"$request_uri",'
'"server_protocol":"$server_protocol",'
'"status":$status,'
'"body_bytes_sent":$body_bytes_sent,'
'"bytes_sent":$bytes_sent,'
'"request_length":$request_length,'
'"request_time":$request_time,'
'"http_referer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"ssl_protocol":"$ssl_protocol",'
'"ssl_cipher":"$ssl_cipher",'
'"connection":"$connection",'
'"connection_requests":"$connection_requests"'
'}';
access_log /var/log/nginx/access.log main_json;
sudo systemctl restart nginx
| Env | Ver |
|---|---|
| Ubuntu | 24.04.3 LTS |
| Grafana | v12.1.1 |
http://[::]:9100で指定する