検索条件
全3件
(1/1ページ)
前回のマシンを更新したのでローカルLLMを軽くベンチマークしてみたでは生成速度だけを見れば十分実用ラインということを確認したが、品質が悪い問題があった。
そこで4月に出て、そこそこ評判を聞くQwen3.6がいかほどのものかというのを軽く試し、ついでにベンチマークもした。
CPU推論とGPU推論が分かれているが、これは初回ベンチマーク時にCUDAのDLLを入れ忘れていたため、GPU推論はDLLを入れてリトライした時の数値、CPU推論はDLLがない状態の数値で書いている。
| 種別 | デバイス |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5(DDR5-5600 16GB) * 4 |
| M/B | ASRock Z890 Pro RS |
実行環境はWindows 11。今回はllama.cppをメインで使っている。
| Env | Ver |
|---|---|
| llama.cpp | 9196 |
| Ollama | 0.24.0 |
| Open WebUI | 0.9.5 |
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 203.404 |
| prompt_per_token_ms | 14.528857142857143 |
| prompt_per_second | 68.82853827849993 |
| predicted_n | 1553 |
| predicted_ms | 94147.172 |
| predicted_per_token_ms | 60.622776561493886 |
| predicted_per_second | 16.495450335990974 |
| input_tokens | 14 |
| output_tokens | 1553 |
| total_tokens | 1567 |
リソース消費
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 103.612 |
| prompt_per_token_ms | 7.400857142857142 |
| prompt_per_second | 135.11948422962593 |
| predicted_n | 1554 |
| predicted_ms | 26037.862 |
| predicted_per_token_ms | 16.755380952380953 |
| predicted_per_second | 59.68231953913881 |
| input_tokens | 14 |
| output_tokens | 1554 |
| total_tokens | 1568 |
リソース消費
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 228.782 |
| prompt_per_token_ms | 16.34157142857143 |
| prompt_per_second | 61.19362537262546 |
| predicted_n | 1816 |
| predicted_ms | 119116.155 |
| predicted_per_token_ms | 65.59259636563877 |
| predicted_per_second | 15.24562306431063 |
| input_tokens | 14 |
| output_tokens | 1816 |
| total_tokens | 1830 |
リソース消費
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 156.28 |
| prompt_per_token_ms | 11.162857142857144 |
| prompt_per_second | 89.58280010238033 |
| predicted_n | 1575 |
| predicted_ms | 30901.59 |
| predicted_per_token_ms | 19.620057142857142 |
| predicted_per_second | 50.96825114824189 |
| input_tokens | 14 |
| output_tokens | 1575 |
| total_tokens | 1589 |
リソース消費
Qwen3.6-35B-A3B-UD-Q8_K_XLを使用。
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし
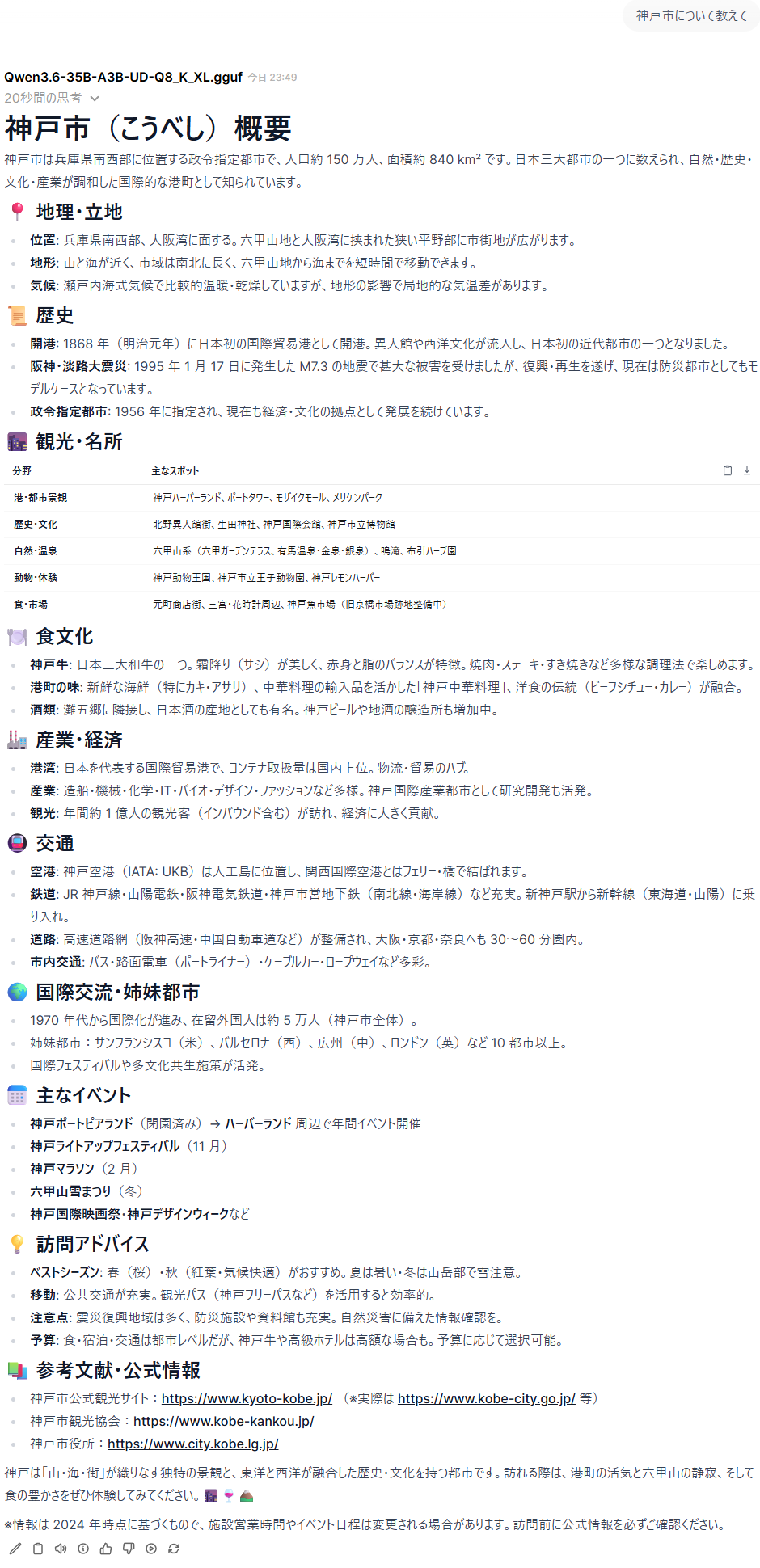
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 262.85 |
| prompt_per_token_ms | 18.775000000000002 |
| prompt_per_second | 53.262316910785614 |
| predicted_n | 1704 |
| predicted_ms | 119261.701 |
| predicted_per_token_ms | 69.98926115023474 |
| predicted_per_second | 14.287906223977135 |
| input_tokens | 14 |
| output_tokens | 1704 |
| total_tokens | 1718 |
リソース消費
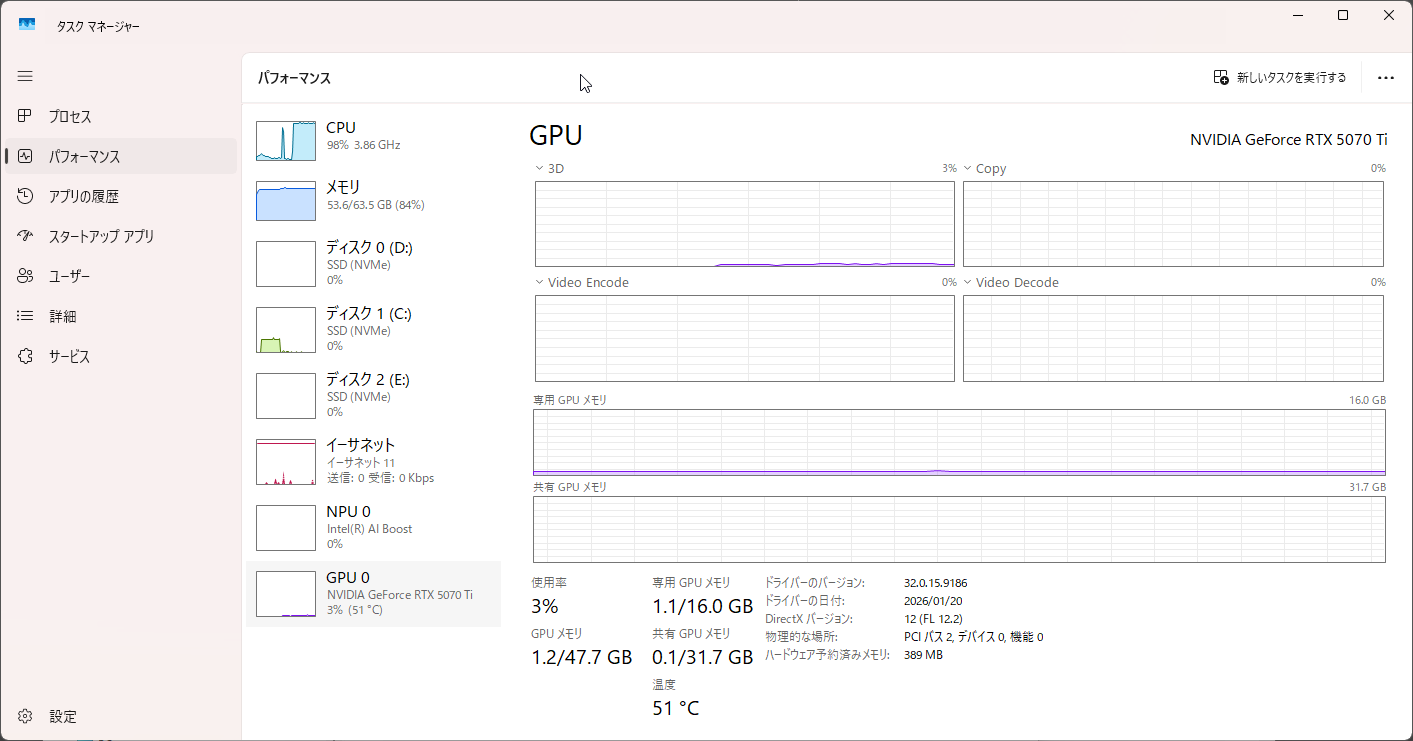
生成速度
| 指標 | 値 |
|---|---|
| cache_n | 0 |
| prompt_n | 14 |
| prompt_ms | 190.329 |
| prompt_per_token_ms | 13.594928571428571 |
| prompt_per_second | 73.55684104892055 |
| predicted_n | 1829 |
| predicted_ms | 51098.747 |
| predicted_per_token_ms | 27.93807927829415 |
| predicted_per_second | 35.7934412755757 |
| input_tokens | 14 |
| output_tokens | 1829 |
| total_tokens | 1843 |
リソース消費
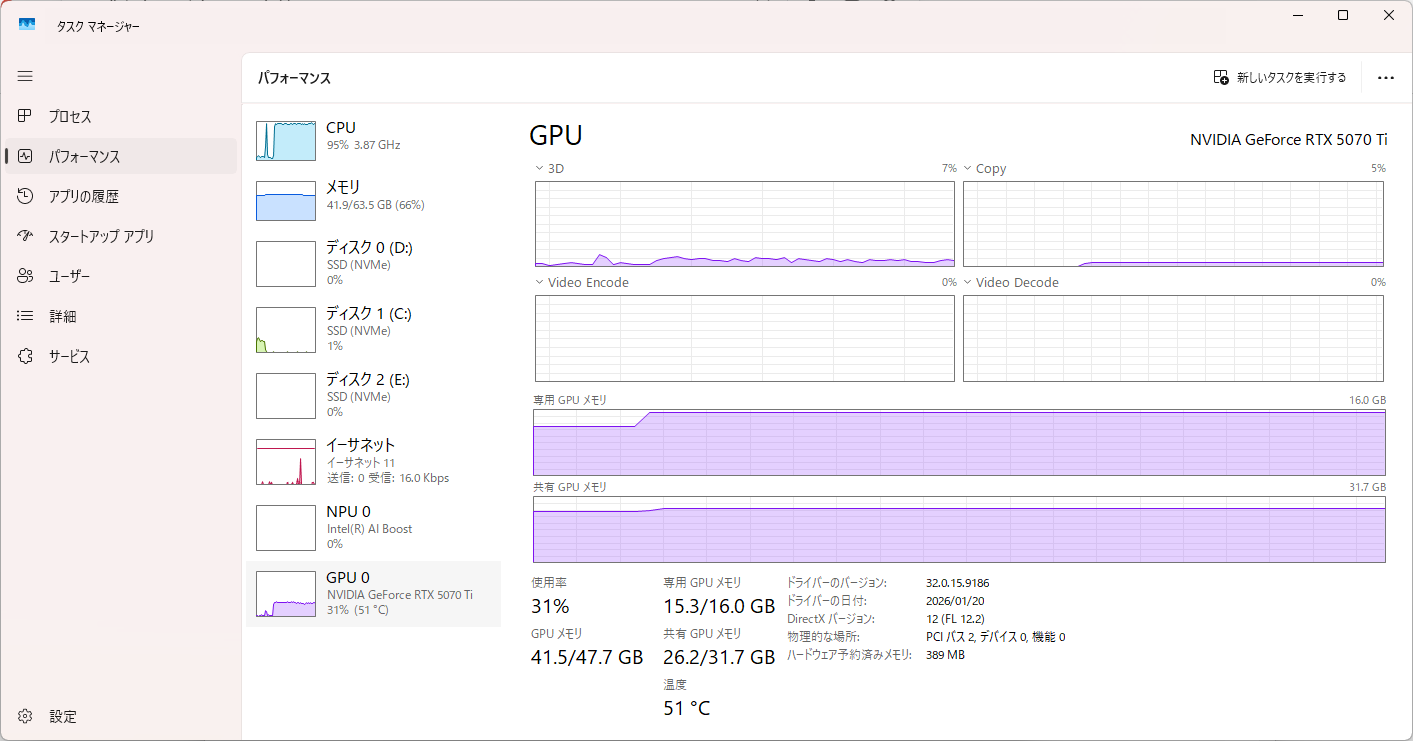
qwen3.6:35bを使用
CPU推論時に出した内容。スクショが面倒なのでGPU推論時のはなし

生成速度
| 指標 | 値 |
|---|---|
| input_tokens | 14 |
| output_tokens | 1364 |
| total_tokens | 1378 |
| prompt_tokens | 14 |
| completion_tokens | 1364 |
| response_token/s | 20.84 |
| prompt_token/s | 5.84 |
| total_duration | 126876747900 |
| load_duration | 58586625500 |
| prompt_eval_count | 14 |
| prompt_eval_duration | 2398703000 |
| eval_count | 1364 |
| eval_duration | 65458229300 |
| approximate_total | "0h2m6s" |
リソース消費
このコマンドはRTX 5070 Ti + 9800X3D running Qwen3.6-35B-A3B at 79 t/s with 128K context, the --n-cpu-moe flag is the most important part. |r/LocalLLaMAにあったものを利用している。
llama-server.exe ^
-m "ここにモデルファイルのパス" ^
--fit on ^
--fit-ctx 128000 ^
--fit-target 256 ^
-np 1 ^
-fa on ^
--no-mmap ^
--mlock ^
-b 2048 ^
-ub 2048 ^
-ctk q8_0 ^
-ctv q8_0 ^
--temp 0.6 ^
--top-p 0.95 ^
--top-k 20 ^
--min-p 0.0 ^
--presence-penalty 0.0 ^
--repeat-penalty 1.0 ^
--reasoning-budget -1 ^
--chat-template-kwargs "{\"preserve_thinking\": true}" ^
--host 0.0.0.0 ^
--port 8033
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 68.82 | 61.19 | 53.26 |
| 出力tok/s | 16.49 | 15.24 | 14.28 |
| 指標 | Q4_K_M | Q5_K_M | Q8_K_XL |
|---|---|---|---|
| 入力tok/s | 135.11 | 89.58 | 73.55 |
| 出力tok/s | 59.68 | 50.96 | 35.79 |
| 指標 | Ollama |
|---|---|
| 入力tok/s | 5.84 |
| 出力tok/s | 20.84 |
上の表の指標については明確な根拠を見つけることができなかったため、指標の名前から推測して、おそらくこの指標はこれだろうというので割り当てて書いている。
何故というとAPIレスポンスの仕様書が何処にあるかわからず、Claude Opus 4.7に聞いてもデッドリンクになった仕様書を提示され、後はソースコードを読めと言われたため、わからないのだ。ソースコードなんか一々読んでられない。しかも嘘を教えられたため、自力で解釈した。
さて、処理時間についてだが、これはOllamaよりllama.cppのほうが圧倒的に早いことが判明した。また、ついでに言うとOllamaはどのモデルを実行してるのかが不明なため、単純比較ができない。
またリソース消費を見る感じ、OllamaはCPU・GPU共に遊ばせていたので、これが処理が遅い原因になっていた可能性がある。llama.cppはマニュアルでそのあたりをうまくやっているので早かったのだろう。
生成品質としては前回とそこまで変わらない気がしたが、質問を一回投げているだけなので、正直なところちゃんとした品質を確かめるには叩きまくる必要はあると思う。面倒なのでそこまではしてない。
Qwen3.6-Plusはクラウド専用モデルのため、ローカルでは動かないが、動かしてみた感じ大分品質は良さそうに思った。少なくともローカルモデルのように目立ったハルシネーションは見られない。

一般的なマシンで動くローカルLLMは、まだそれなりという感じの次元だが、Qwen3と比べると3.6は気持ち品質が上がったように感じた。とはいってもLLMはコンテキストがある状態で質問したり、コーディングさせたりしないと真価がわからないので、今回のように「神戸市について教えて」と聞くだけではあまり意味のある結果にはならないので、あくまで参考値くらいだろう。
取り敢えずまともなモデルはOpenAIもQwenもクラウドにあって、配布されているモデルは劣化版というのが分かったのが今日の収穫だったように思う。
Qwen公式の比較表を見る限り、Qwen3.6-35B-A3BはClaude Sonnet 4.5よりは賢いようだ。ただSonnetは個人的にはもう使っておらず、レートリミットがない環境で使っているのもあり、もっぱらOpus 4.7しか使っていないので、Sonnet 4.5を超えたところで微妙な感じは否めない。4.5は個人的にERPをするときにOpus 4.7, Sonnet 4.6, Opus 4.6でも返事をしなくなったときに4.5を叩き、その次のターンでOpus 4.6→Sonnet 4.6→Opus 4.7という流れで回帰させるのに使うことが多い。これは何をしているかというとSonnet 4.5の検閲が緩いのを逆手にとって、上位バージョンを騙すためのコンテキストを書かせているわけだ。
Sonnet 4.5が出た時は割と重宝していた記憶もあるのだが、Opus 4.7が優秀なので、もうまともな用途ではOpus 4.7以外全く使わなくなった。Opus 4.6も悪くはないと思うので、Opus 4.6くらいまでローカルLLMが進歩してくれたら助かるところである。
ひとまず今回の収穫はQwen3.6-35B-A3Bという昨今注目されているモデルが、特にメモリの増設なしでも動いた上に、VRAMを使わずRAMだけで実用速度で走らせることができたことだ。
クラウドLLMは高いのでローカルLLMで解決できるようになれば、それに越したことはない。
余談だがQwen3.6-35B-A3Bは検閲モデルだがQwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressiveという無検閲モデルがあり、ERPが機能することを軽く確認している。弾かれないこと程度しか確認してないので品質は謎いが、テストで叩いた感じはそこそこの内容を出してくれたと思う。少なくともGPT-4やGrokよりはよいと思うので、お金を節約したい人にはオススメかもしれない。
前回のAnimaの正式版が出たのでベンチマークやNovelAIと品質比較してみたでは以下の通り、生成時間が長くやや厳しめだったが、もう少し何とかならないかというので試してみた。結論としては速度の向上ができた。
| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 448x576px | 6.768s |
| XL | 896x1152px | 9.090s |
| Anima | 896x1152px | 18.054s |
まず前提として私はほとんどのケースで縦長か横長でしか作らないので、前回より基準サイズを落としている。その分Upscalerで拡大する方向だ。
またベースモデルを使うこともないため、カスタマイズされたモデルを使っている。具体的には前回の検証時にはまだベースモデルが出たばかりだったので、ベースモデルしか選択肢がなかったが、Anima Cat TowerがAnima base-v1.0に対応したため、これを利用している。
ソフトウェア
ComfyUI v0.21.1
ハードウェア
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
まずは比較用のXLから。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 512x768px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 42.40s |
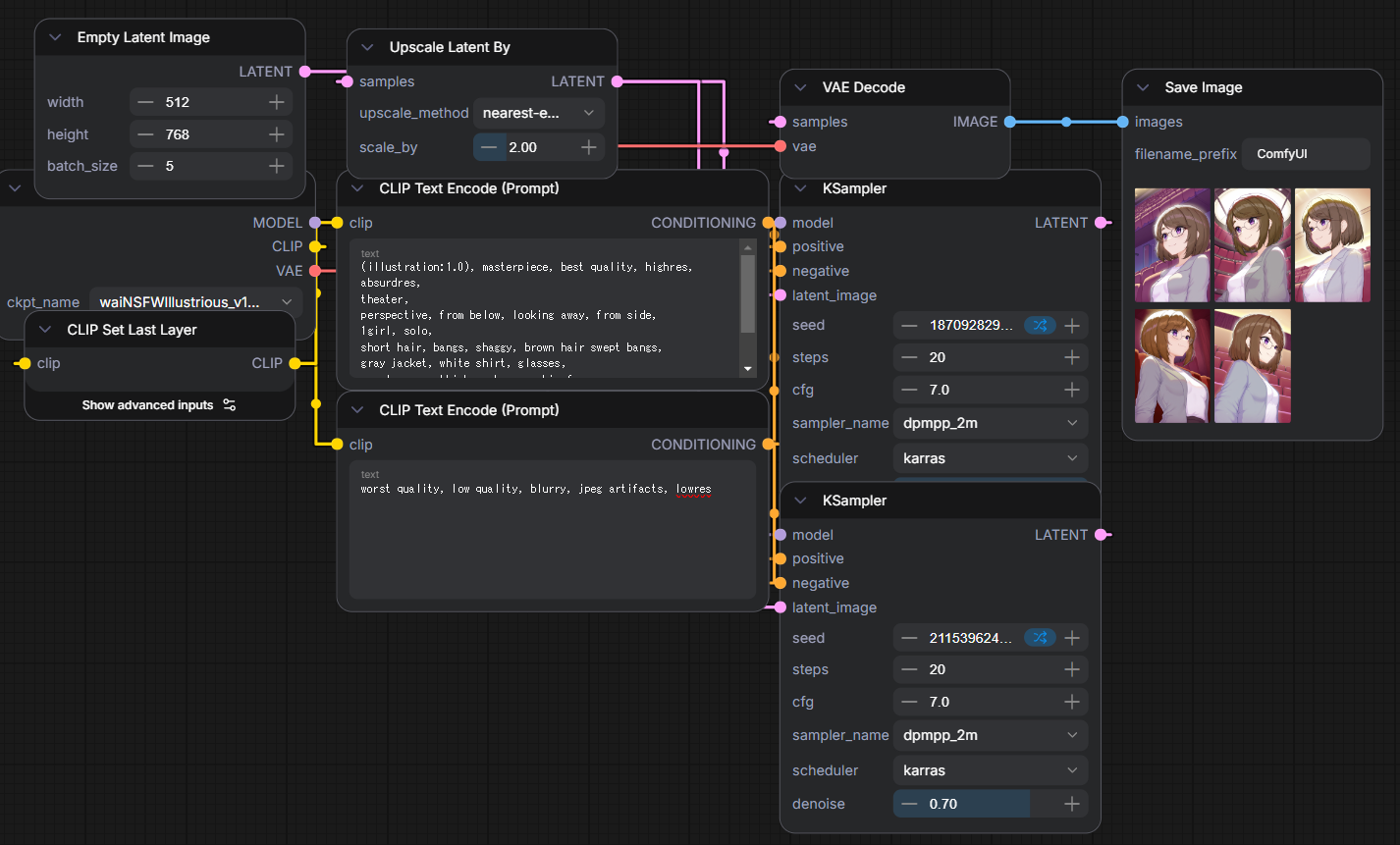




次にAnimaを試す。
| 設定 | 値 |
|---|---|
| Model | animaCatTower_v10.safetensors |
| VAE | qwen_image_vae.safetensors |
| Text Encoder | qwen_3_06b_base.safetensors |
| Empty Latent Image (WxH) | 512x768px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 63.60s |
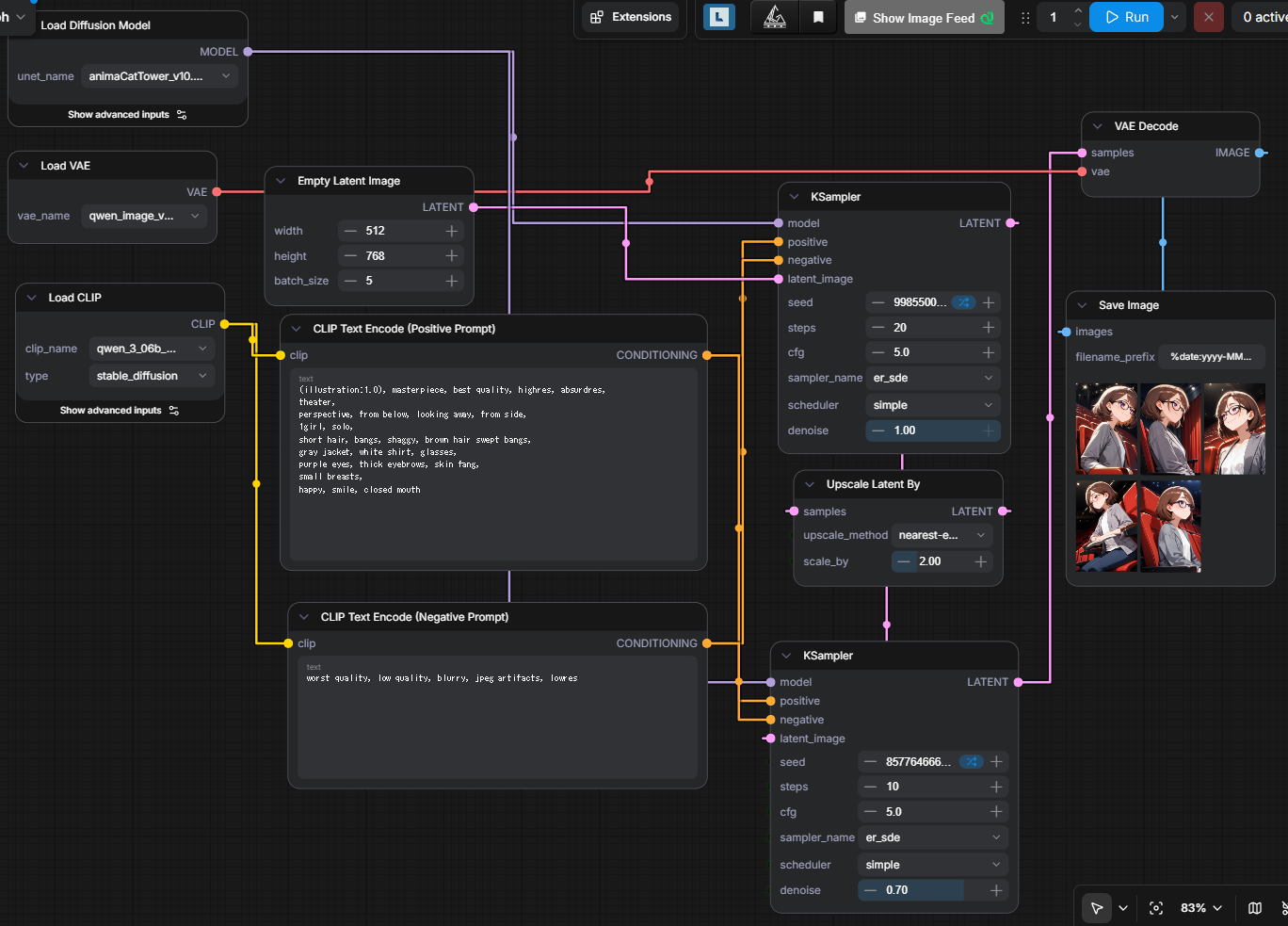
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。




| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 512x768px | 8.48s |
| Anima | 512x768px | 12.72s |
最終成果物の画像サイズが異なるため単純比較はできないが前回18.054sだったAnimaが12.72sになり、出力画像サイズも896x1152pxから1024x1536pxに増えていることから、前回より大きな画像を短時間で生成させることに成功している。
これは基準サイズを推奨値より大幅に落としたことと、Animaに従来のXLのワークフローで使っていた二段KSampler、つまりHire.fixを導入したことと、更にその部分で後段のKSamplerの処理量を落としたり、前段のKSamplerのStepも推奨から落とすことで、全体の負荷を落としたところが大きいと思う。要は推奨値からかなりあれこれ落としている。
しかもそれでいて品質は高く出ているため、現状はいい感じだと思う。まだそんなに生成してないのでどこかに落としな穴がある可能性はあるものの、現時点では満足だ。
ブログ用に出している生成画像は毎回似たような画像ばかり出しているが、普段からこんなのを作っているわけではなく、常日頃は全く違う画像を作っている。
ただ流石にここに出すのも微妙な気がするので、このサイトがブログである必要性について考えてみた その2の延長でどうするかは考えている。
恐らくこのサイトの課題として、このブログにすべてが集約されていてノイズが多すぎるところがある。それはよくもあるのだが、ゾーニングも必要だと思う。キッティング記事と料理のレシピと旅行がごちゃ混ぜな時点で探しづらいし、そこに大分アレゲなAI生成画像を突っ込むのはさらにおかしなことになってしまう。
恐らく一定のジャンルごとにサイトを分割するのがよいと思っているが、まだどうするかは考え切れていない。ただ同時に全ての記事のフィードを垂れ流すカオスなハブもあったほうがいいとは思っている。
少なくとも画像を並べるならギャラリーのようなサイトがあることが望ましいだろう。それも内容は間違いなくアレゲなので。
ComfyUIを使ってみる2で先月からComfyUIに移行したわけだが、最近Animaという有力なモデルのプレビュー版が出たということで乗り換えていた。
このAnimaは基本的にComfyUI用で、これまで使ってきたAUTOMATIC1111やreForgeでは使えないという噂で、非常にいいタイミングだった。
そして本日正式版としてbase-v1.0が出たのでベンチマークしてみることにした。また、出力品質が以前と比べて非常に向上しており、絵柄再現やキャラ再現ができたため、NovelAIとの簡単な比較もしている。
ソフトウェア
ComfyUI v0.21.1
ハードウェア
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
これまでのりこベンチは基準となる画像サイズ(Empty Latent Image)を768x768pxで実施していたが、Animaでは896x1152pxが基準となる。
このため、まずはUpscaleで倍にすることを考え、画像の基準サイズを448x576pxに変更した、りこベンチで計測した。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 448x576px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 33.84s |
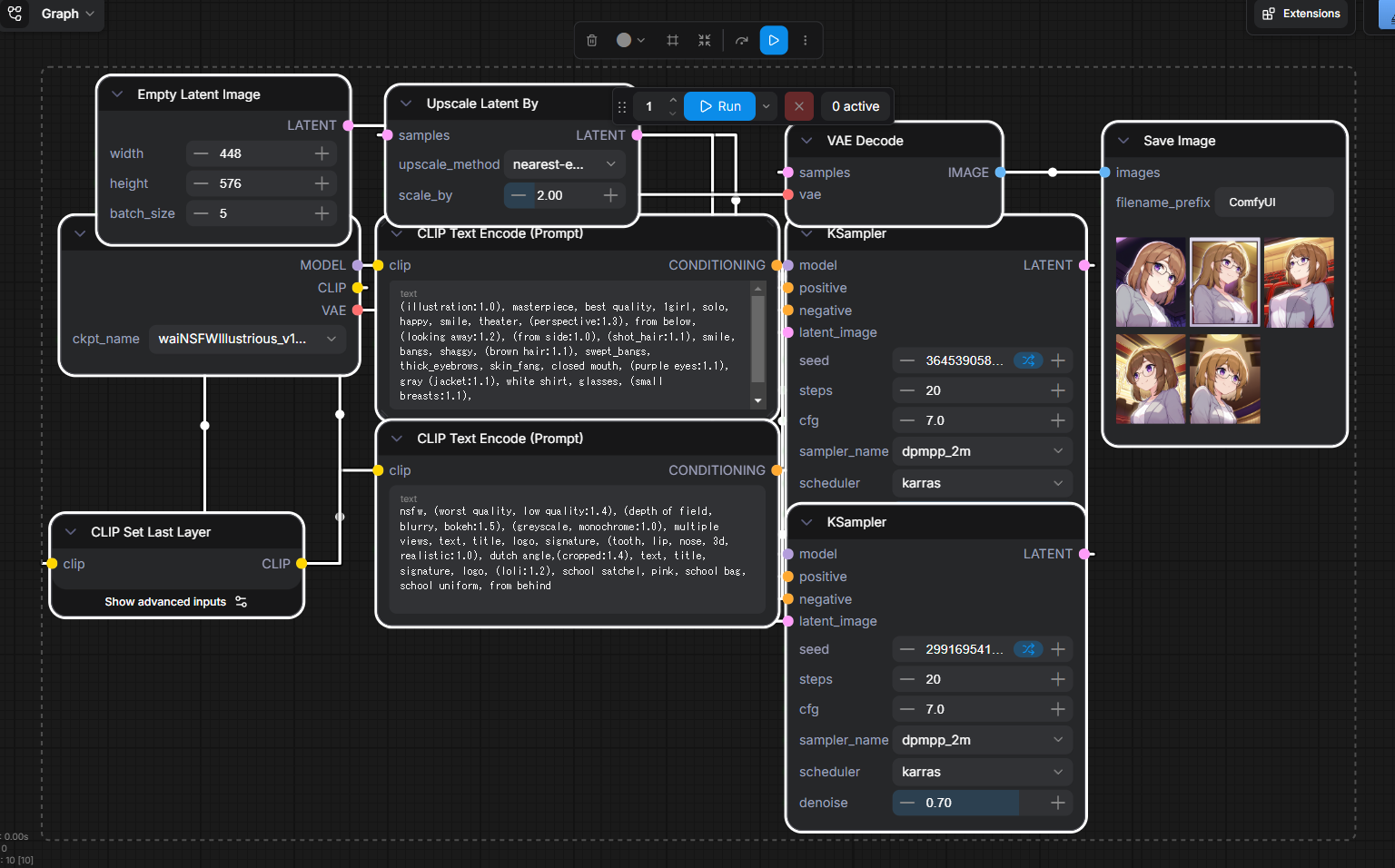
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。




次はUpscaleなしで等倍の896x1152pxが出る条件で計測した。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 896x1152px |
| Upscale | なし |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 45.45s |
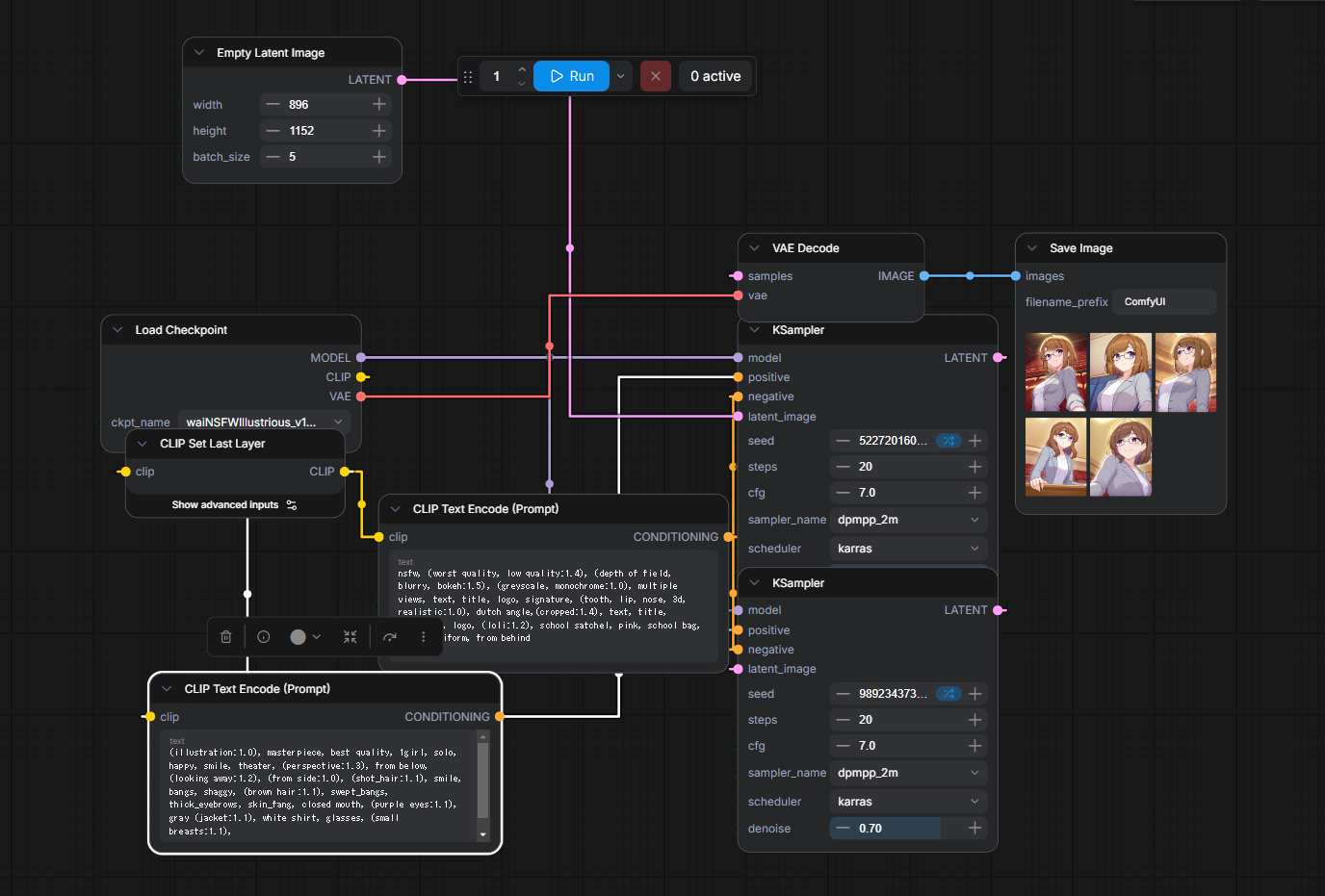
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。




| 設定 | 値 |
|---|---|
| Model | anima_baseV10.safetensors |
| VAE | qwen_image_vae.safetensors |
| Text Encoder | qwen_3_06b_base.safetensors |
| Empty Latent Image (WxH) | 896x1152px |
| Upscale | なし |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 90.27s |
左下に何処にも繋がっていないノードがあるが、これは消し忘れたゴミである
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。




| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 448x576px | 6.768s |
| XL | 896x1152px | 9.090s |
| Anima | 896x1152px | 18.054s |
以上が今回のベンチの結果だが、Upscale前提だと生成速度が3倍にもなっている。これは見方次第ではやや厳しいタイムだ。
しかしComfyUIはWorkflowsを工夫すれば一回叩くだけで複数のシーンを出すことができるため、A1111やNovelAIのように張り付かなくて良い点を考慮すれば、さほど気にならないかもしれない。
またAnimaではHirefix(二段KSampler)なしにXLより高い品質の画像を出力できているように見えるため、ここも良いポイントだ。
生成速度については「Anima-Turbo Coming soon.」と書かれているため、近日中により早いものが出るかもしれない。高品質版かもしれないが何も書いてないので実際のところは謎だ。




これはAnimaのプレビュー版であるpreview3-baseから作られたanimaCatTower_v05.safetensorsで作った画像だが、非常に品質がいい。
恐らくbase-v1.0で作り直されれば、より品質が高まるだろう。
NovelAIには劣るものの、これまでLoraがないと厳しかった絵柄の再現がある程度できる。いくつか実際に比較してみた。
やや破綻が見られるものの、絵柄としてはだいぶ出ていると思う。NovelAIほど正確さがないのはある意味で便利かもしれない。
| Anima | NovelAI |
|---|---|
 |
 |
ディティールはそこまでないが、大まかにはそれっぽいのが出せていると思う。NovelAIと比べるとどうしても劣る。
| Anima | NovelAI |
|---|---|
 |
 |
これがいとうのいぢの絵柄見えたら大分目が悪いと思う。学習量が少ないのか精度が悪い。NovelAIは流石に圧巻である。ただNovelAIも絵柄が古く、ハルヒ時代といった感じだ。最新ののいぢという感じはしない。
| Anima | NovelAI |
|---|---|
 |
 |
遠目に見えれば見えなくはないが、だいぶ厳しい。線の丸みと色の淡さはそれっぽいかもしれない。NovelAIの再現性は流石である。
| Anima | NovelAI |
|---|---|
 |
 |
これも従来であればLora或いは、専用のモデルが必要だったが、一応出せるようになっている。
但し単純なプロンプトでは品質が悪くなりがちで、NovelAIと比べると勝負にすらならないレベルだ。とはいえ、それができるようになったというだけでも十分すごい。
ここまでの品質のものは中々出ないので奇跡の一枚に近いが、天音かなたを出すことができる。10回くらい回したが、大半は天音かなたのような何かだったので、安定性はない。
NovelAIでは非常に安定して天音かなたを出力できる。
| Anima | NovelAI |
|---|---|
 |
 |
これも奇跡の一枚に近いが、泣きボクロがないけど樋口楓に見える何かは出ている。
勿論、NovelAIのほうが再現性が高く安定している。
| Anima | NovelAI |
|---|---|
 |
 |
キノに見えなくもないくたびれた男性のようなものが出てきた。これでも奇跡の一枚で、酷いと人の姿さえ出てこないことがあった。
NovelAIは安定しており、何枚か出してみたところ特に指定していないにもかかわらず、パースエイダーを構えているものを出すことさえできた。但し指が破綻していたのでここには載せていない。
| Anima | NovelAI |
|---|---|
 |
 |
いわれてみればアスナに見えなくもないが、他人の空似レベルである。
NovelAIは(ry
| Anima | NovelAI |
|---|---|
 |
 |
XL系と比べると出力時間が三倍かかるが、品質は大きく向上し、絵柄やキャラの再現もある程度可能になっているためローカルで色々やるにはよくなったと思う。
ただ版権絵を絵柄丸コピーでどうこうするとか、そういった用途に使うにはまだ厳しいと感じた。
絵柄やキャラ再現はLora + Ponyが非常に優秀なので、何もなしで高品質だけど時間がかかるAnimaがどこまでいけるのかは現段階では未知数である。
しかしながらポテンシャルは感じるので、今後GPUの性能向上や、ComfyUIやモデルの進化などによって、より良い方向へ向かう可能性は十分にあるだろう。恐らくRTX7070TiになるころにはXL並みの速度にはなっていると思う。