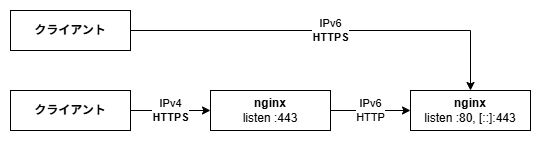
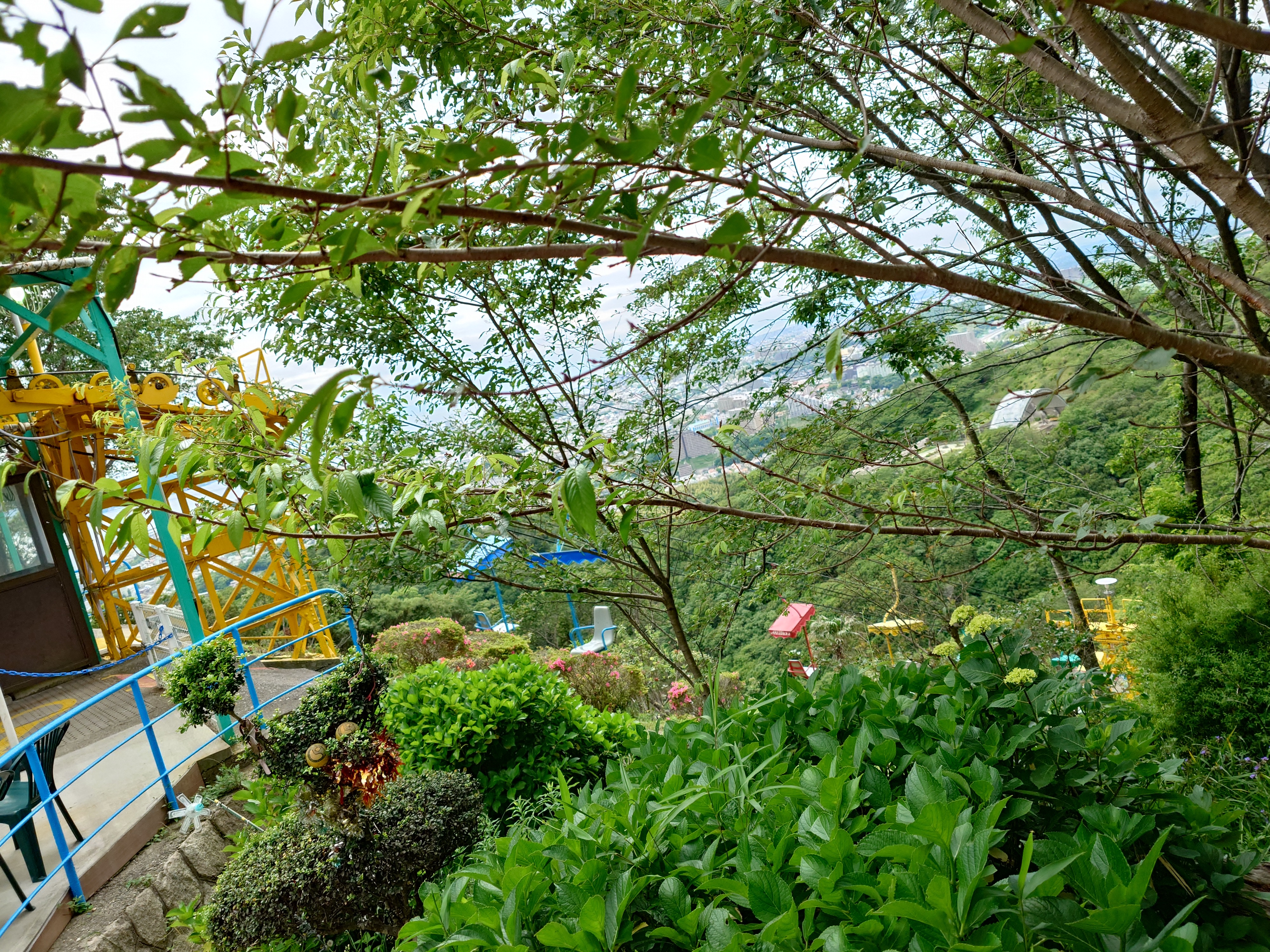これは去る5月23日、須磨浦山上遊園 へ行ってきたときの記録である。
旅行記放置しすぎなので書いていこうキャンペーンの一環で淡路市に初上陸してきた話 に続き、連続して書いている。
一体何ヶ月分放置するつもりなんだ…。MECEにならずノイズが増えるばかりの技術記事より、もっとMECEの余地が根本にない日記のようなものを書くべきだろう。
記憶にある限り今回で三度目の来訪だ。
この回の訪問では前回、3月9日の訪問時に撮影した箇所の写真を撮らなかったため説明用の写真が足りず、一部に3月9日に撮影した写真を混ぜており、その旨の言及をしている。
須磨浦山上遊園とは、書いて字のごとく須磨浦の山の上にある遊園地である。
場所として山陽電車須磨浦公園駅 直結というアクセス至便の立地にある遊園地だ。駅直結なのでひらパー みたいに駅から歩く必要はない。駅直結だけあり、運営者は山陽電車である。
遊園地としては昭和に作られた懐かしの遊具や施設を満喫でき、瀬戸内を望む山の上なので大変眺望が良いことが挙げられる。子供が来ても面白が少ないかもしれないので、どちらかといえば大人向けだろう。
例えば日本一乗り心地が悪いことで知られるカーレーターや、日本に5つしか残っていないといわれる回転展望台、現役のジュークボックス、インベーダーゲームといったものや、落下防止装置のない観光リフト、サイクルモノレールなどがある。
ネット上ではガラガラでスカスカで今にも潰れそうな遊園地と紹介されることも少なくないが、私が前回行ったときはそこそこ混んでおり、待ち時間0秒というほどではなかった。遊具によるが5分は覚悟した方がいいだろう。
三宮で写真を撮っていなかったので阪神三宮駅から阪神の特急に乗車し山陽須磨へ移動したところ。
ここ数年の山陽電車はJR西日本に倣ってベンチの向きを線路に平行にしているため、山陽須磨のベンチの向きも平行になっている。今年の3月9日には既にこうなっていた。
山陽須磨から海側へ目を移すとJR須磨駅が見える。JRの須磨駅は須磨浜に面しており、駅を出たらすぐ砂浜という夢のような駅である。
山陽須磨で周囲を見渡すと神戸が坂の町と呼ばれている理由がよく分かるくらいには坂が良く見える。
この駅にはカロリーメイトの自販機があるので、小腹が減ったときにも安心だ。改札を出ればコンビニもあるが、動きたくないときには重宝するだろう。
なお、この写真は3月9日に撮影したものである。
しばらく待っていると普通電車がやってきた。これに乗って隣駅の須磨浦公園駅へ向かう。タイミングがいいと二枚目の様な新しい車両が来ることもある(二枚目は3月9日撮影)
須磨浦公園駅で列車を降りると須磨浦山上遊園のレトロな看板などが出迎えてくれる。
ホームを出ると眼前は瀬戸内海で、非常に眺めがいい。
海側から駅舎を望むとこんな感じ(3月9日撮影)
この日はよく並んでいたが、三宮・姫路1dayチケットを持っていた私はこの行列をスキップしてロープウェイ乗り場へ向かった。
ロープウェイ乗り場へ向かう階段も中々のレトロさだが、この日は外国人も目立ち、少し驚いた。ただインバウンド客というより、神戸に住んでる外国人が大半で、ごく僅かに訪日客がいるくらいに見えた。
理由として、そもそも神戸ではムスリムのような人は普通にいるし、東南アジア系の人も多く見えたからだ。近場にあって手ごろに遊べるので遊びに来たとか、そんな感じだと思う。一応英語対応もしてるし。
さていよいよロープウェイが見えてきたので乗り込む。
座席には山陽電車のモケットが使われており、これは新型車両のものなので、割と最近モケットだけリニューアルされたものとみられる。
この写真は3月9日に撮影している。
搬器は古くはないものの、新しくもない。そんな感じである(3月9日撮影)
さて動き始めると最初に目に入るのは写真中央左手に見える神戸市営須磨海づり公園 だ。昔は奇妙な円盤状の建物があったのだが、老朽化で撤去され、随分シンプルになった(3月9日撮影)
神戸市は釣り禁止エリアが多いが、ここでは合法的に好きなだけ魚を釣れる。但し有料である。
ロープウェイが高度を上げてくると西には須磨浜から神戸市街、ポートアイランド、神戸空港などを一望でき、更に奥には大阪まで一望できる。
正面を見ると海づり公園、奥の陸地は紀伊半島、つまり和歌山県だ。
海を往来する船舶も良く見え大変眺望がいい。
余談だがロープウェイに乗らなくても登山道を歩くことで山上遊園にアクセスできるため、ロープウェイ代をケチりたいとか、健康になりたい人は登山道を歩いてもいい。ここの登山道は六甲全山縦走路に指定されているので、非常に名のある道になっている。但し登山道を行くなら最低でも運動靴は履いてきた方がいいだろう。
ロープウェイを降りると次はカーレーターだ。これに乗ってメインの場所まで行く。山上遊園なので山の上に行くための乗り物が多い(3月9日撮影)
「揺れ続けて60周年」「唯一無二のカーレーター 60周年」などとめでたい感じの搬器が走っている。ちゃんちゃんこみたいなやつ乗りたかった。
(Browser not support video tag) pub/lycolia/image/adiary/2026/06/20260309_163931507.mp4 (Browser not support video tag) pub/lycolia/image/adiary/2026/06/20260523_125044704.mp4
この動画を見ると、かなり揺れているのが分かると思う。この通りガタガタしているため、日本一乗り心地が悪いといわれている。なお一枚目の動画は3月9日に撮影したものである。
原理的にはローラーの上に乗ったコンベヤの上を走行していると思うのが、乗降口に来るとタイヤの上に直乗りするので、揺れが強まり、乗り心地が悪化する感じだ(3月9日撮影)
カーレーターは世界でもここにしかない珍しい乗り物なので、この乗車体験は貴重だ。
カーレーターは乗り心地が悪いことばかり注目されがちだが、実は眺望もいい。このように淡路島と明石海峡大橋を望むこともできる。
カーレーターに揺られて坂を上っていくと回転展望閣に到着する。実は兵庫県は回転展望閣のメッカで、最盛期は全国最多の三基存在したそうだ。現在でも二基は生きていて、もう片方はポートタワーの中にある。
回転展望閣に入るには料金が必要だが、三宮・姫路1dayチケットを持っている場合は無料で入れる。
(Browser not support video tag) pub/lycolia/image/adiary/2026/06/20260523_130056299.mp4
展望閣内はこんな感じでゆったりと回っている。
このフロアは喫茶室コスモスという軽食店になっているが、この日は満席だった。
回転展望閣は回転する性格上、東洋経済のやたら詳しいレビュー によると荷重に制約があり50席しか設けられないそうだ。そのため面積に対しての定員は少なめである。
仕組み的には床下に3本のレールがあり、その上に車輪の乗った床があり、一番内側には24個、中央と外側は48個の車輪がついているらしい。つまり合計で120個の車輪がある。これをモーターを使って駆動させることで回しているようだ。
点検は3カ月に1回のペースで行っています。モーターのある部分の床が開くので、ここから車輪に油を差すなどを行っています。つい最近だと、10年以上ぶりにモーターを新調しました。この時はぜんぶで約1000万円の費用がかかりました。3年ほど前には車輪も全部替えました。車輪が一番消耗するんですよ。なお、年間のランニングコストなどは特に計算していません
このようなコメントもあり、維持費は安くはなさそうだ。また先の記事には回転レストランよりもカーレーターのほうが、より高額なメンテナンス費用が発生しているともあった。
須磨浦山上遊園には専属の保守業者がいて面倒を見ていてくれているようだが、全国に設置された当時はどこもがそうだったわけではなく、設備更新方法が不明なまま閉じられた場所もあるのではないかと書かれていた。ただ、ここの場合は鉄道会社が運営していることからレールや車輪、モーター、電気系などの調達そのものは他所より容易な可能性はあるかもしれない。
先の東洋経済のレビューによると喫茶室コスモスは平日に50組~100組。土日祝日は150~250組ほどが来店するとのことで、中々盛況のようだ。1組あたりの平均単価は1500円前後。看板メニューは税込700円のクリームソーダと、税込600円のピザトーストとのこと。そして、ここの食材はロープウェイとカーレーターを利用して運ばれてきているらしい。
そしてここもまた眺望がよく、淡路島や明石海峡大橋や、垂水区の住宅街や、西区の辺りまで一望することができた。眼下に移る観光リフトも楽しみだ。(三月にも行ったが…w)
山の中にポツンと移る場所も須磨浦山上遊園の一部らしいのだが、ここには行けていないのでまた頃合いを見ていきたいと思う。
回転しているので船が行き交う様子が見れる時もある。
壁には県外からの来訪者の漫画も掲示されていた。掲示されている漫画はこれ以外にもあるので興味のある人は是非現地で見てほしい。
来援記念ノートにはタイ王国からの来訪が記録されていて驚いた。まさかさっきロープウェイ乗り場ですれ違った在日タイ人らしき集団はわざわざ海外旅行で来ていたのか…!?
最近は著名人の来訪も多いのか、最近書かれたサインも多くあった。ポプテピピックで有名な大川ぶくぶのサインまであった。大川ぶくぶはいとうのいぢと並び、兵庫県を代表するイラストレーターなのだが、以前、加東市の広告を描いてたり、ここにサインを残していたり、何とも古郷思いの方だなと思った。
この日は残念ながら屋上には登れなかった。
二回にはかつてロープウェイを制御していたという機器が置かれていた。
なんとマスコンは中を開けることができる。
(Browser not support video tag) pub/lycolia/image/adiary/2026/06/20260523_125901349.mp4
中を開けてぐりぐり動かすと中の動きがよく分かる。詳しい仕組みはわからないが異なる長さの金属の接点が回転により端子と触れ合っているように見えるので、恐らく一つ一つのラインがスイッチのような働きをしているのではないかと思う。
触れるラインが増えるほど電流が多く流れ、モーターがよく回るとか、多分そんな感じだと思う。知らんけど。
二階にはこの他にもインベーダーゲームや懐かしのアーケードゲームが多数並んでおり、いい雰囲気だった。
一階に降りるには一度外に出ないといけないので、外に出たところ写真撮影用の顔ハメ板が置いてあり、外国の方に大人気だった。
さて、そんなこんなで一階にある軽食店にやってきた。喫茶室コスモスは混雑している上に高いので、空いているであろう一階の方に来たのだが、予想通りガラガラだった。
メニューはコスモスと比べるとだいぶ庶民的で、価格も安価だ。しかも三階で売られている神戸六甲アイスクリームがこちらにもある。神戸六甲アイスクリームは一部のスーパーでも売られていて非常においしいやつである。
そして三階のやつには喫茶室コスモスという名前があるが、こっちには特に名前がなかった。
キャッシュレスの時代なので、しっかりキャッシュレスにも対応している。
という訳で食事とした。なんとも映えない食事だが、フランクフルトには粒マスタードがあり、ケチャップもいい感じのラインで塗られているし、たこ焼きもちゃんと船に入っているあたり、チープではあるものの雰囲気はしっかり出ている。
レシートは回転展望閣BBQということになっていた。BBQの受付が偶然軽食も出しているということなのかもしれない。
そしてなんとこのフロアには現役のジュークボックスもある。
このジュークボックスは中に円を描くように大量のレコードが入った場所があり、お金を入れて曲を選ぶと、このレコードを収めている台座が回転し、アームがレコードを掴み、レコード盤にセットし、再生が始まるといったものだ。
レコードが入ったスロットを特定している仕組みは不明だが、古い機械なので複雑なことはしていないと思われる。恐らく選曲ボタンに応じたスロットにレコードをセットしていて、それを取り出しているだけだと思う。
Wurlitzerのアーカイブサイトによると、ボタンを押すと対応するピンが跳ね上がり、レコードを格納する盤面が回転し、検知機に衝突したら停止 という機構のようだ。
確か逆回転もしてたような気がするので仕組み的には上記ページそのものだと思う。
たぶん今の人が実装しようとしたらQRコードや、RFID、OpenVisionとかを使うかもしれないが、古い機械なので至ってシンプルだ。つまり、ボタンとスロットが合致しない状態でレコードがセットされていれば違う曲が再生されたりはあるだろう。
また、この機体はDeutsche WurlitzerのX2 で、1976年に制作されたモデルのようだ。つまり50年間動いていることになり、恐らくこの建物とほぼ同年齢なので、当時は新品で納入された個体なのだろう。それが今までこうして動き続けているというのは何とも素晴らしいことだ。
天井にはNationalのレトロな電灯もあった。電球はLEDに変えられてそうだが、この電灯カバーは何とも趣がある。
観光リフト乗り場に向かっているといい感じに成長した木を切り倒す告知があり、ちょっと寂しい思いになった。
そもそも安全装置の付いた観光リフトの方が少ないと思うが、それはさておき乗り場へやってきた。
写真にある通り、安全バーやシートベルトなどの安全装置はないタイプだ。松山城にあるのと同じようなタイプだが、あちら より屋根が立派である。落ちても死ぬことはないと思う。
まずはリフト乗り場前でチケットを買う(3月9日撮影)。基本的に往復を買うが、帰りを歩く人は片道でもよい。ハイキング道があるので徒歩でも戻ってこれる。
新札対応は片方しかないのと、ここは現金しか受け付けていないので注意。どうしてもクレジットで払いたい人は麓の受付まで戻ってAチケットを買ってくるしかないと思う。
乗り始めはこんな感じ。結構傾斜があり、最初は怖いがなれれば何ともない。そのうち手すりに摑まらずとも平気になる。
左奥に見える謎の建築物は花の広場というらしいが、一度も行ったことがないので、また機会があれば行こうと思う。噂では廃墟らしい。
乗り場の案内でも花の広場だけ「営業中」ではなかった上、なんか明らかに安っぽいラベルが貼ってあったので、つまりそういうことなのだろう。
ここもまた眺望がよく、淡路島と明石海峡大橋、そして垂水、明石方面を一望できる。加古川にある製鉄所もぼんやり見えている気がする。
谷底付近は谷合の上を通りかなりの高さがあるため、高所恐怖症の人にはお勧めできない。(3月9日撮影)
そして観光リフトが谷底に入ると、最大の名所が訪れる。
なんとここには摂津国と播磨国の国境があり、その上を通れるのである!!!(3月9日撮影)
こんなところは早々ないので、ここを超えるためだけに乗っていいともいえるのが、この観光リフトだ。少なくとも私は最初このリフトに乗りに来たときは、これを見るために乗った。
そして同時に海側を見れば壮大な谷が見える。いい景色だ。
ここを過ぎればあとは登っていくだけである。
ワイヤーを通している鉄塔をよく見ると昭和三十四年七月 山陽電気鉄道株式会社とあり、非常に長い間、大切に扱われてきたことが分かる。
イラストの注意書きには日本語、英語、中国語、韓国語が併記されており、昨今のインバウンドを意識していることも伺える。
リフトで対岸に着くと自然いっぱい山上遊園の門が迎えてくれる。
前回3月9日に来たとき営業時間が終わっていて乗れなかったサイクルモノレールに乗るのが今日の目的だ。きっと空中を走るので怖いはずだ…!という期待を胸に向かう。
途中でトイレに寄ったが、山の中にある古い遊園地にしてはちゃんとウォッシュレットで感動した。ただ、恐らく和式便所を改造しているようで、部屋が凄く狭かったのと、カバンなどをかける場所がなかったのでやや困った(清掃中で床が水浸しだった)
意外と人がいてちょっとした列ができていた。列は外国人がメインだった。
ここも支払いは現金のみと思われる。
さて番が回ってきたので乗っていく。らくしーchannelというYoutubeによると、手前側が去年入った新車で、奥側が45年前の車両 らしい。また線路長は180mあるとのことで、結構漕ぎごたえがある。
作られた年代が分かる仕様の表示板と、遊園地らしい身長制限の奴もあった。
漕ぎだしはこんな感じ。
(Browser not support video tag) pub/lycolia/image/adiary/2026/06/20260523_144240763.mp4
高さはそんなになく、揺れもないので特に怖さは感じなかった。鷲羽山ハイランドのスカイサイクルの予習として使うにはイマイチかもしれないと思った。
相変わらず眺望は抜群によく、淡路島と明石海峡大橋と垂水と明石の街並みが良く見えた。供用中だが工事中の高速道路?とやたら広い空き地が見えたが、こっちは住宅の分譲地だろうか?
垂水JCTかな?と思ったが、小さすぎるのと、方角的に名谷ICだと思った。垂水JCTはもっと北にあるのでたぶん見えない。
写真や動画を撮りながら止まったりゆっくり進んだりしていたが、それでも前が詰まっているので、存分に形式を楽しみながら進めるのがここの良いところだと思った。
ちなみに私の後ろの人は電話でキレ散らかしながら漕いでいたが、タイ語か何かを喋っていたので何を言っているのかは全く分からなかった。
1/4ほど進んだところは何故か木がなぎ倒されていた。景観のためにしてはやりすぎな気がするので謎だ。台風で倒れたにしては局所的すぎる気もした。
山の中にデカいマンションがぼこぼこあって見ごたえのある景色だ。
1/2ほどで開けたところを抜けて内側に入ってくると壁が見えるようになる。何かの制御盤がいた。
ゴール手前に来ると海が見え、再び眺望が良くなった。
サイクルモノレールを降りると「この水は飲めません」と書かれた蛇口を見かけた。昔は飲めたが、今は水道管の腐食や、蛇口の衛生面などで飲めなくなったとかなのだろうか?
蛇口が下を向いていることから、そもそも飲用目的の設置ではないのかもしれない。飲用目的なら上に開店する蛇口か、先が丸くなった噴水タイプみたいなやつだと思うし。
ハイキング道みたいな場所があったので入ってみたが、勢い余って下山してしまいそうなので戻ることにした。
もしかしたらこの先に「花の広場」があったのかもしれない。
帰りの観光リフトで帰っていく。やはりなかなかの角度だ。
来るときは摂津国から播磨国に入ったが、今度は播磨国から摂津国へ帰ってゆく。
撮影物の中に混ざっていた謎の写真。恐らくカーレーターの乗降口にあるタイヤだと思う。
ロープウェイで下山。この日は三宮・姫路1dayチケットで来ており、姫路市立水族館でナマコを撫でる予定だったのだが、予定の時間をかなりオーバーしていた。
最終受付時間に間に合う電車に乗れるかどうかというぎりぎりのラインだったが、ロープウェイが降り切る寸前に電車が見えたので、この日は姫路に行かず帰ることにした。
一応ロープウェイを降りて走ったものの、改札口に着いた頃には電車の最後尾が過ぎ去るところで、まぁ無理だった。というか間に合ってもナマコ撫でる時間があったか疑わしい時間だったので仕方がない。
そして三宮方面ホームに着くと留置線から須磨浦公園発の特急が出てきたタイミングだったので、これで帰りましたとさ。
ジャンルを旅行記にしているが、果たしてこの記事は旅行記なのか…?小旅行を増やすべきでは…?とか思ったが、深いことは考えないことにした。これ以上ジャンル増えても管理に困るし…。
「おでかけ」にジャンルをリネームするのも考えたが、おでかけにしては巨大すぎる記事もあるしなぁ…。よし、この話は忘れよう。
三宮・姫路1dayチケット は阪神三宮から山陽姫路が一日乗り放題になる企画乗車券だ。
本来阪神三宮から山陽姫路の往復運賃は1,920円だが、このチケットは1,590円で購入できるため、このチケットを使うことで安く往復できるうえ、更に途中下車し放題になる。
更に須磨浦山上遊園の入園料や一部の遊具利用が無料になるという特典まである。これは正規料金では1,500円するため、1,590円で須磨浦山上遊園の一部を無料で遊べて、更に三宮と姫路を往復できることになる。ついでにコンチェルトまたはルミナス神戸2で行われるクルージングの1,000円引きまでついてくる。
要するに1,590円で(1,920 + 1,500 + 1,000) - 1,590で2,830円ほどお得になる計算だ。電車賃分は途中下車すればするほど初乗り料金が相殺されるのでお得になる。
それで山陽電車は経営的に大丈夫なんか?という話もあるのだが、このチケットが売れても売れなくても電車と遊園地は回っており費用が掛かっているため、チケットが売れた時点で売れないよりはマシなのである。そして売るためには来てくれるよう安くする必要があるわけだ。
しかも客が遊園地に来れば飲食や、追加で観光リフトに乗ったり、カーレーターに乗りまくるなど、追加でお金を落としてくれる可能性もあることを考えれば、空気を運んで一円も入らないよりは割引してでも売って来てもらった方が収益に繋がるという話だ。この手のチケットは買ったけど使わないまま期限を迎える人もいるため、そういった埋没分も考えれば、売れれば売れるほど良く、成立するのだと思う。
ちなみに私が須磨浦山上遊園に初めて来たときも、このチケットがあったからこそ来たし、例外なくこのチケットで来ているので、有効活用している人物の一人である。しかもまんまと罠にハマって追加料金まで払ってる。でもそれでいいのだ。これでも正規料金より安いし、ここにも続いてほしいしね。
そして基本的に三宮から姫路に行くときはこのチケットを買っているので、時間に余裕があるときは遊びに来ている。とはいえ、姫路に用事があって暇な時というのもそんなにないので、寄れていないことの方が多くはあるが、3割くらいは来てると思う。
直近でやりたいことリスト に書いているネタだが、これは後日触りに行ったので、また別で記事にしたいと思う。いや、でもこっちは大したネタではないので書かないかも…w
ひとまず今回は「書きたいけど書けてない日記のネタを書く」にある「須磨浦山上遊園に行った話」が書けたので良しとする。