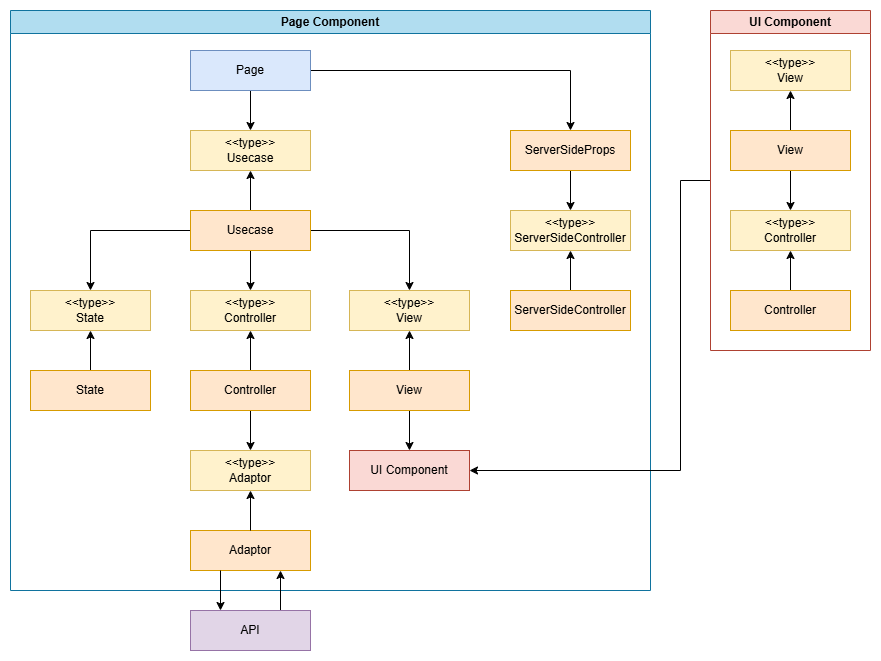
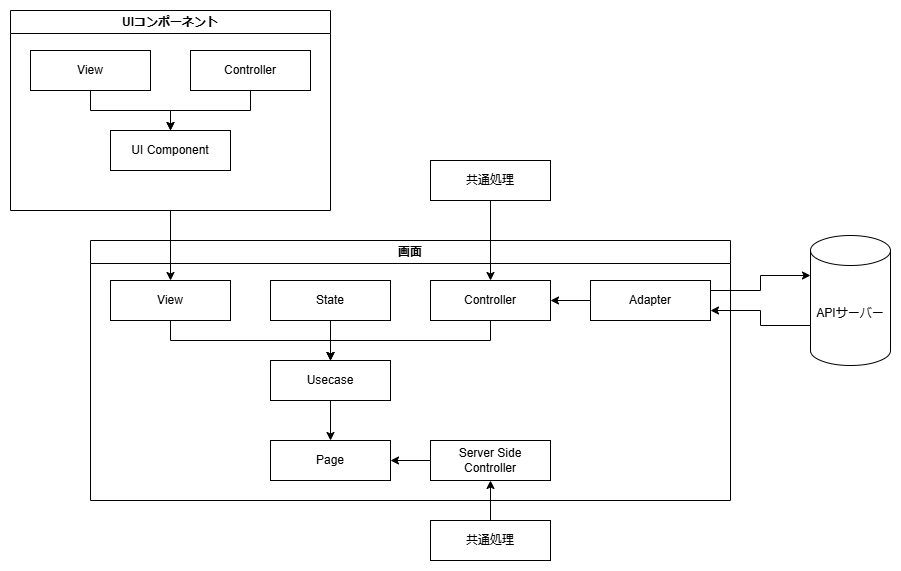
この項目ではエラーメッセージを返すサーバー側の処理について記述する。
resolvers/customer-info/helpers/invalid-reason.ts
type ReferencePageLinkMapKey = 'userFormIssue' | 'duplicateUserName' | 'someErrorMessage';
// exportされているがgetInvalidInfo(key, boolean)でreferencePageLinkMap.get(key)が返ってくることを確認するテストに使われているだけ
export const referencePageLinkMap: Map<ReferencePageLinkMapKey, string> = new Map([
['userFormIssue', 'https://help.example.com/23843ddvwa'],
['duplicateUserName', 'https://help.example.com/xdxdk2t5'],
['someErrorMessage', 'https://help.example.com/pp33s'],
...
]);
const invalidReason = {
inputIssue: {
message: '入力項目にエラーがあります。...',
links: [
{
label: '【登録時のヘルプページをご確認ください】',
url: referencePageLinkMap.get('userFormIssue') ?? '',
},
],
},
...
};
export const getInvalidInfo = ({
errorReasonType,
isModeA,
}: {
errorReasonType: ErrorReasonType;
isModeA: boolean;
}): Omit<SomeFormInvalidInfo, 'invalidReason'> => {
switch (errorReasonType) {
case 'INVALID_INPUT':
case 'SOME_INPUT_ERROR':
return invalidReason.inputIssue;
...
};
}
このコードの問題点
- 定義する必要性が希薄な型情報があり、改修コストが高い
- 変数や関数名、キー名などから相関する機能の関連性を読み取りづらい
- 定義されたスコープを超えて利用されているもので命名から機能の読み取りが難しいものがある
- リテラルがべた書きされており将来のリファクタリングに支障がある
- 不必要にMapが使用されており、実装が冗長になっている
- 静的な値の取得にNull合体演算子が使用されており、潜在不具合となりやすい
- 型情報がべた書きされすぎており、見通しが悪い
- 複数のフラグ値の正規化を利用側で行っており、複雑になっている
リソースファイルと実装が一緒くたであると読みづらいためファイルを分割する。パスも書いているがパスについては深く考慮できていない。
resources/messages/CustomerError.ts
export const ERROR_MESSAGES = {
formValidationError: {
message: '入力項目にエラーがあります。...',
helpLinks: [
{
label: '【登録時のヘルプページをご確認ください】',
url: 'https://help.example.com/23843ddvwa',
}
],
},
...
} as const;
まずtype ReferencePageLinkMapKeyは無駄に型の管理コストが増えるだけなので削除する。意味がないとは言わないが、型の追加削除によって発生するデグレードは普通は型検査でわかるためなくてよいだろう。
次にreferencePageLinkMapでは意味がわからないのでERROR_MESSAGESにリネームする。中身のキーもinputIssueでは分かりづらいのでformValidationErrorとし、フォームのバリデーションエラーであることが分かるようにする。linksについても何のリンクなのかわからないためヘルプのリンクであることを明示できるようにリネームする。
helpLinks.urlについては、共通のURLを参照する概念は普通ないか、あったとしても別に切り出して管理するのはコストなので直に書いてよいと考える。元のコードでもテストコード以外には使われていない。テストコードには実値を書かないと回帰テストとして機能しないため、この方式のほうがより良いと考える。
例えば以下のようなテストコードは回帰テストの観点では意味が薄い。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe(invalidReason.get('inputIssue'));
});
これは以下のように書くことでページのURLが変更されたときにテストが失敗するため、より価値のあるものになる。但しこれはexpect(invalidInfo).toStrictEquals({ ... })の形で一括判定したほうが、テストコードの可読性の観点からより良いだろう。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe('https://help.example.com/23843ddvwa');
});
ERROR_MESSAGESをリソース変数としてみなせば、これはべた書きというより定数定義とみなせるため、基本的には問題ないと考える。勿論これは同じURLを持つものが大量にあるなど、ケースによっては考慮の余地はあるだろう。
またMapをやめ、敢えて直値を書くことで万一存在しなかった場合に、元にあった以下の空文字が返ってきて機能しなくなる問題も解決している。そもそも通る余地がないロジックなので存在しなくてよい。
url: referencePageLinkMap.get('userFormIssue') ?? ''
またERROR_MESSAGESにas constを付与することで、意図しない破壊が起きる可能性を減らすことができる。
handlers/error/GetCustomerInfoError.ts
export const getCustomerInfoError = (errorType: CustomerErrorType) => {
switch (errorType) {
case CustomerErrorType.INVALID_INPUT:
case CustomerErrorType.SOME_INPUT_ERROR:
return ERROR_MESSAGES.formValidationError;
...
};
}
まずgetInvalidInfo()をgetCustomerInfoError()にリネームすることで意味を分かりやすくしている。次に複雑な型情報を除去してシンプル(= (errorType: CustomerErrorType) =>)にする。errorTypeはerrorReasonTypeとisModeAを合成した結果を渡すことを想定している。これによって、この関数内の複雑性を減らすことができる。またCustomerErrorTypeはENUMなので、case 'CODE1':のようにリテラルべた書きを回避できるうえ、仕様変更などで値が変わった時にも対応がしやすくなる。
また戻り値の型も削除する。これは静的解析により自明であるほか、Omit<SomeFormInvalidInfo, 'invalidReason'>とあるが、実際に返しているのはinvalidReasonであり、関連性がないためだ(おそらく、偶々よく似た型を転用しているのだろう)。またこの事例では更にinvalidReasonという変数名があり、Omitの内容と視覚的に競合し、コードの読解が難しいため、この修正により可読性が増す。
また改修前はエラーメッセージオブジェクトのキーと、ヘルプページのキー名、そしてswitchのキーの全てが食い違っており、見ていて混乱する内容だったが、ヘルプページのURLをべた書きするように変えたため、混乱する要素を減らせている。
コードの記述量を減らし、長大なコードを別々のファイルに分けることや、過度に分割しすぎないことによって可読性が向上し、コード量が減ったため保守コストも削減できたと考えている。
半面、静的解析のコストは上がっているが、静的解析のコスト増よりも可読性がよく、保守コストが低いコードのほうが効率的な開発に寄与するだろう。
また静的な値を取得するためにMapを使い、TypeScriptを利用しているため、理論上undefinedが返ってこないのに、それを期待するロジックを削除することで、コードを読んだ人が混乱する可能性も削減している。
この項目ではエラーメッセージを返すサーバー側のエラーハンドリングについて記述する。
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
if (error.graphQLErrors[0]?.extensions?.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
...
}
if (error instanceof SomeError) {
...
}
...
}
このコードの問題点
- エラーハンドリングが長々とべた書きされていて見通しが悪い
- 配列の添え字が直に指定されているが意図が読み取れない
- 例外処理なのにOptional chainingが多く確実な例外処理に支障がある(例外処理で例外が発生するリスクは最小限にする必要がある)
extensions配下の型情報が暗黙的でわからない
graphQLErrors: ReadonlyArray<{
extensions: {
[attributeName: string]: unknown;
}
}>
const handleApolloError = (err: ApolloError) => {
if (err instanceof ApolloError) {
// graphQLErrorsが空であれば例外をスローし、そうでなければgraphQLErrorsを返す
const gqlErrors = parseGQLErrors(err.graphQLErrors);
// graphQLErrorsの中身をパースし、意味のある型を付けて返す
const extensions = parseThisFunctionErrors(gqlErrors);
if (extensions.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
}
}
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
handleApolloError(error);
} else if (error instanceof SomeError) {
...
}
...
}
べた書きされているとコードの見通しが悪いため、catch句の中では例外種別ごとにハンドリングする処理に飛ばし、そっちで処理できるようにする。
error.graphQLErrorsは要素が0の場合があるため、parseGQLErrors()のような共通関数を作り、要素があれば中身を返す、なければ例外をスローして、より上位の処理に飛ばすなどの処理を共通的に行うようにする。この仕組みを共通化することで、この要素に対する処理の一貫性を持たせることができる。
またgraphQLErrorsの詳細については処理によって内容が異なるであろうことから、ドメインごとにparseThisFunctionErrors()のような関数を作り、その中で適宜データを整形するのが望ましいだろう。
そうして結果的に意味のある型情報を持ったextensions、あるいは適当な結果情報をハンドリングすることで、型安全かつ、責務が別れ、疎結合な実装に寄与する。
この形式であればhandleApolloError()は必要に応じて別ファイルに切り出し単体テストを書くこともできるし、このままでもあっても規模が小さければ十分テスト可能だろう。
なお、parseGQLErrors()やparseThisFunctionErrors()の具体的な内容については今回は省略する。