2026/03/05(木)最近作ったWebツールの話とか
投稿日:
最近二つほどツールを作り、Webツール置き場に配置したので、そこで得た学びや、作る時に意識したことについても書いてゆく。
ENV Checker
まずENV Checkerを作った話。

端的に言うとCyberSyndrome : ENV Checker - 環境変数チェッカーのパクリである。但しJSがないと動かない。
違いとしてはCyberSyndrome側で見れる情報のうち、ユーザー環境に起因しない情報を大幅に削り、ユーザー環境をメインに出せるようにしているほか、IPv4とIPv6の表示にも対応している。
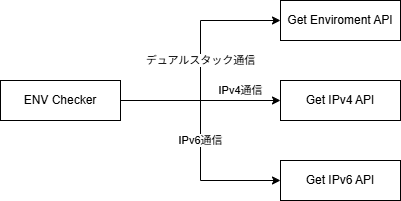
作りとしては必要な情報を返すAPIを3つ用意し、ページを表示したときにJSがそれぞれを叩きに行き、その結果を表示している。
Get Enviroment APIはIPアドレス以外の環境変数を返却するもので、Get IPv4 APIはIPv4アドレスとホスト名、Get IPv6 APIはIPv6アドレスを返すように作ってある。
なぜこの様な分け方にしたかというと、Get Enviroment APIはIPのバージョンを問わない情報しか返さないが、IPアドレスまで返すようにするとIPv4に付随する情報やIPv6アドレスを返すことになるため処理が煩雑になる。
これは実装としてはCGIの環境変数をそのまま返しているのでREMOTE_ADDRに:が含まれているかどうかを見てIPv4か、IPv6かを振り分ける処理が必要になるからだ。
一方でGet Enviroment APIが環境変数だけを返すことに専念できるのならば、IPv4に付随する情報はGet IPv4 APIを叩けば取れるし、IPv6はGet IPv6 APIを叩けば取れるため、分岐処理が不要になる。
これによって各APIは単一の責務だけを持つことになり、コードの複雑化を回避できるといった寸法だ。この程度のシンプルな実装に求めることではないし、現状では無価値ではあるのだが、常日頃から意識することで、より複雑なものを作る時にも生かせるだろうし、将来何か改修するときにも作りが単純なほうが理解しやすいと思うので、こうしている。
IPv4とIPv6のAPIをどう分けているかというと、これはDNSレベルで解決している。Get IPv4 APIのエンドポイントにはAレコードのみを、Get IPv6 APIのエンドポイントにはAAAAレコードのみを設定することで、クライアントが接続する際に使用するIPバージョンを強制している。
こうすることで、各APIは単純にREMOTE_ADDRをそのまま返すだけでよくなり、IPバージョンの判定ロジックを一切持たなくて済むのが利点だ。欠点としてはAPIの数が一つ増えるため、管理コストは増えているといえるだろう。しかし分岐ロジックというのは往々にしてバグを生む存在であり、ないに越したことはないと思い、こういう設計にした。
また画面の描画をJavaScriptにさせているのも、こういったいわゆる関心の分離の思想によるところが大きい。やろうと思えばIPアドレス以外はCGIで表示して、IPアドレスのところだけをJSで書き換えることも、当然できる。出来るのだが、責務を分けるにはデータを返すだけのエンドポイントと、それを受けてJSで書き換える手法のほうが、より責務がはっきりしていて、わかりやすいのでこうしている。疎結合ということでもある。
項目値をダブルクリック・タップすることで値をコピーできるようにしているのも、地味だがこだわりポイントだ。
余談だが、先日Value-DomainでcertbotのDNS Challengeをやるスクリプトを書き直したのは、このドメインにTLS証明書を付与したり、DDNSできるようにする目的があったのが大きい。
というのも、このENV Checkerの開発にはipv4.lycolia.infoとipv6.lycolia.infoというドメインが関係しており、私の自宅サーバーの環境はIPv4がコロコロ変わるためDDNSが必須だった。
私が利用しているDNSレジストラであるValue-DomainはDDNS用のエンドポイントがあるのだが、1回1ドメインしか更新できず、60秒に1度しか叩けないという制約があり、これを回避するためには、Value-DomainのDNS APIに対して、一回で複数ドメインのAレコードを書き換える必要があった。
また同時に、以前使っていた、TLS証明書更新ツールである、value-domain-dns-cert-register (vddcr)はNode.jsのアップデートなどに伴う頻繁なメンテナンスが必要だったり、動作検証不足があったり、様々な面倒ごとがあり、これ以上触りたくなかった。
そんなこんなの流れがあり、ENV Checkerを作る中でOpenWrtからValue-Domainに複数サブドメインのDDNSを行うツールを作ったり、新たなTLS証明書更新ツールを作り、その検証をしたりしたのだ。
QRコードジェネレーター
もう一つはQRコードジェネレーターを作った話。
QRコードジェネレーターなどググれば無数に出てくるわけだが、意外と読み取り可能な最小サイズかつ、それをSVGで出力できるものを見つけることができなかった。そこで作ることにした。
とはいえ、作ったのはフロントエンドだけで、QRコードの生成自体はqrcode-svgを使わせてもらっている。これはこのライブラリのデモサイトで、理想の要件のものが作れることが分かったからだ。
なぜデモサイトで使えるのに、わざわざ作ったかだが、まずこのデモサイトでは最小サイズのQRコードを簡単に得ることが困難だったほか、256px以下のサイズにすることが想定されていないように見えたからだ。少なくともUIをクリックしてDIMENSIONを256px未満にしようとしても出来なかった。
また、デモサイトはいつか消える可能性もあるし、ブックマークするのも面倒なので、自分でホスティング出来るなら、それをするに越したことはなかったというのもある。

これを作っている中で得た学びとしては、カラーパレットの入力UIがWeb標準で可能になっていたことだ。そこら中で見かけるし標準であるんちゃうか?と調べたらあったので採用した。こういう複雑なものは昔であれば恐らく何かしらのライブラリを使うか、気合で作る必要があったと思うが、全く世の中は便利になったものだ。
また、こちらの実装方法については、HTMLの標準機能でカラーパレットを使ったカラーコード入力UIを作る方法の記事で紹介している。
他にもQRコードの周りには余白が必要ということも知れた。QRコードの開発元であるデンソーウェーブでは余白の求め方の計算式が解説されている。仕様上は適切な余白がない場合、読み込めない可能性があるようだ。これは恐らく周囲の図形とQRコード本体を光学的に分けて認識させるために必要なのだと思う。
なお、今回作成したQRコードジェネレーターには余白の自動調整機能は実装していない。理由は単純でサイズを自由に変えられる仕様上、帳尻をつけるのが面倒だからだ。要は手抜きである。
ついでにWebツール置き場の保守性や解りやすさを少し上げたりした
Webツール置き場のドメイン配下は元々全てペラのHTMLで実装していたのだが、ページが増えるごとに共通部分のhead要素の管理が煩雑になっていた。そこで、PHPに置き換えることにした。
結果として、以下のように、head要素の中身を共通化することができた。
まぁやっていることとしては高校時代にPHPで静的HTMLの内容を共通化していたのと何ら変わらないので、何故今更そんなことを…という感じだが、元々は静的HTMLで済むものは静的HTMLのほうが表示速度が速くシンプルでよいよなという意図で、静的HTMLにしていたのだが、数が増えてくるとそうも言ってられないということで対応した形だ。こういうのは事前に考慮しすぎると、早すぎる共通化やKISSの法則的なリスクを孕むと思っていて、定期的に振り返り、都度対応するほうが良いと感じている。いや、この程度の内容でそこまで考える必要はないと思うが…w
<!DOCTYPE html>
<html lang="ja">
<head>
- <meta charset='utf-8'>
- <meta http-equiv='X-UA-Compatible' content='IE=edge'>
- <title>Slackのリマインダーコマンドを作るやつ</title>
- <meta name="referrer" content="no-referrer-when-downgrade"/>
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <meta name="author" content="Lycolia Rizzim">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <meta property="og:site_name" content="Lycolia">
- <meta property="og:title" content="Slackのリマインダーコマンドを作るやつ">
- <meta property="og:description" content="必要事項を埋めることでSlackの/remindコマンドを生成するやつ">
- <meta property="og:type" content="website">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <link rel="stylesheet" href="style.css">
- <script src="check.js"></script>
- <!-- Matomo -->
- <script>
- var _paq = window._paq = window._paq || [];
- /* tracker methods like "setCustomDimension" should be called before "trackPageView" */
- _paq.push(['trackPageView']);
- _paq.push(['enableLinkTracking']);
- (function() {
- var u="https://analytics.lycolia.info/";
- _paq.push(['setTrackerUrl', u+'matomo.php']);
- _paq.push(['setSiteId', '3']);
- _paq.push(['enableHeartBeatTimer', 10]);
- var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
- g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
- })();
- </script>
- <!-- End Matomo Code -->
+<?php
+require_once('../template.php');
+
+renderCommonHead(
+ thumbnail: 'https://tool.lycolia.info/slack-remider-creator/OGP.png',
+ title: 'Slackのリマインダーコマンドを作るやつ',
+ description: '必要事項を埋めることでSlackの/remindコマンドを生成するやつ'
+);
+?>
</head>
template.phpの中身
関心ごとに関数を切り分け、呼び出される側は呼び出す側に依存するように設計することで、親が子の変更に引きずられないように保守性を意識した設計にしている。他にもほとんど固定値であるものについては運用を平易にする観点からOptional化して、初期値を設定している。
<?php
function buildMatomo() {
return <<<END
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://analytics.lycolia.info/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '3']);
_paq.push(['enableHeartBeatTimer', 10]);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
END;
}
function buildCommonMeta(string $title, string $thumbnail) {
return <<<END
<meta charset='utf-8'>
<meta http-equiv='X-UA-Compatible' content='IE=edge'>
<title>$title</title>
<meta name="referrer" content="no-referrer-when-downgrade"/>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="author" content="Lycolia Rizzim">
<meta name="thumbnail" content="$thumbnail">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-32x32.png" sizes="32x32">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-192x192.png" sizes="192x192">
<link rel="apple-touch-icon" href="https://lycolia.info/assets/brands/lycolia-180x180.png">
END;
}
function buildOG(
?string $thumbnail,
?string $site_name,
?string $title,
?string $description,
?string $type
) {
$tags = " <meta property=\"og:type\" content=\"$type\">\n";
$tags .= " <meta property=\"og:site_name\" content=\"$site_name\">\n";
if ($thumbnail !== null) {
$tags .= " <meta property=\"og:image\" content=\"$thumbnail\">\n";
}
if ($title !== null) {
$tags .= " <meta property=\"og:title\" content=\"$title\">\n";
}
if ($description !== null) {
$tags .= " <meta property=\"og:description\" content=\"$description\">\n";
}
return $tags;
}
function renderCommonHead(
?string $thumbnail = 'https://lycolia.info/assets/brands/lycolia-OGP.png',
?string $site_name = 'Lycolia.info',
?string $title = null,
?string $description = null,
?string $type = 'website'
) {
$head = buildCommonMeta($title, $thumbnail);
$head .= buildOG(
thumbnail: $thumbnail,
site_name: $site_name,
title: $title,
description: $description,
type: $type
);
$head .= buildMatomo();
echo $head;
}
また他にも、ドメイン直下にあるページの構造を見直した。
具体的にはulとliでリストにしていた部分をdl dt ddに直し、各ツールの内容を少し解りやすくした。ただ余りにも見た目が殺風景すぎるので、liに戻してカードUIをはめ込むようにするかもしれない。
| 変更前 | 変更後 |
|---|---|
 |
 |
2026/01/30(金)CGIのラッパーCGIを作る方法
投稿日:
既存CGIを一切触らずに、前段にアクセス制御やアクセスロガーをつけたいとかの用途でラッパーCGIを使うと上手くいくので、その方法を書く。
なお前段が動くことしか試していないが、備考に後段で処理をさせる方法についても軽く触れている。
動作機序
CGIはコマンドライン引数、環境変数、標準入力を受け取り、何かを処理した結果を標準出力するプログラムである。
つまりラッパーCGIはコマンドライン引数、環境変数、標準入力を受け取り、それをラッピングするCGIにそのまま受け渡し、このCGIの標準出力をリダイレクトできればよい。
やり方
以下のようなコードを書き、exec()前に前段の処理を書けばよい。
#!/usr/bin/perl
use strict;
use warnings;
#
# ここに実行前に挟みたい処理
#
my $original_cgi = './hoge.cgi';
exec($original_cgi) or die "Cannot exec $original_cgi: $!";
今回実際に作ったサンプル
adiaryにはアクセス制限をする機能がなく、本体を弄るのが嫌だったので前段に処理を入れることで実現した。
#!/usr/bin/perl
use strict;
use warnings;
# 以下のコマンドでIP::Geolocation::MMDBをインストールしていることが前提
# cpanm -l extlib IP::Geolocation::MMDB
use lib './extlib/lib/perl5';
use IP::Geolocation::MMDB;
# https://download.db-ip.com/free/dbip-city-lite-YYYY-MM.mmdb.gz
# ex. https://download.db-ip.com/free/dbip-city-lite-2026-01.mmdb.gz
my $db = IP::Geolocation::MMDB->new(file => './DBIP-City.mmdb');
my $country_code = $db->getcc($ENV{REMOTE_ADDR});
# 日台韓は許可する方針(怪しい挙動を見たことがないため)
my @allow_country_codes = ('JP', 'TW', 'KR');
my $user_agent = $ENV{HTTP_USER_AGENT};
# 許可する国コードかチェック
my $is_allowed_country = grep { $_ eq $country_code } @allow_country_codes;
# 許可するBOTのUAパターン
my @allowed_bot_patterns = (
qr/bot/i,
qr/curl/i,
qr/wget/i,
qr/google/i,
qr/bing/i,
qr/mastodon/i,
qr/misskey/i,
qr/pleroma/i,
qr/akkoma/i,
qr/lemmy/i,
qr/activitypub/i,
qr/hatena/i,
qr/github/i,
qr/tumblr/i,
qr/meta/i
);
# 許可するBOTかチェック
my $is_allowed_bot = 0;
for my $pattern (@allowed_bot_patterns) {
if ($user_agent =~ $pattern) {
$is_allowed_bot = 1;
last;
}
}
# 許可国でもなく、許可BOTでもなければエラーにする
if (!$is_allowed_country && !$is_allowed_bot) {
# 未知のSNS BOTを将来的に許可するために、BOTくさいUAのログを集めておく
if ($user_agent !~ /Windows|Mac OS|Linux|Android|iOS|iPhone|iPad/i) {
# OGP取得BOTに間違いなく含まれない文字列が入ってるものはログに入れない
my $deny_ua_log_file = './deny_ua.log';
if (open my $fh, '>>', $deny_ua_log_file) {
my $time = localtime();
my $remote = $ENV{REMOTE_ADDR} // 'unknown';
my $uri = $ENV{REQUEST_URI} // 'unknown';
print $fh "[$time]\t\"$user_agent\"\t$country_code\t$remote\t$uri\n";
close $fh;
}
}
print "Status: 403 Forbidden\n";
print "Content-Type: text/plain; charset=UTF-8\n\n";
print "Access denied.\n";
exit;
}
# adiary呼び出し
my $original_cgi = './adiary.cgi';
exec($original_cgi) or die "Cannot exec $original_cgi: $!";
備考
perldocを読んだ感じ、互換性に問題が出る可能性も少なからずあるようだ。
perldocのexec関数の説明を見る感じ、ENDブロックや、オブジェクトのDESTROYメソッドを起動しないとあるので、実装方法次第では正しく動かない可能性もあるのかもしれない。
また「戻って欲しい場合には、execではなく system関数を使ってください」とあるため、もし後処理をしたい場合はexec関数でなくsystem関数を使うとよいと思う。
あとがき
レンタルサーバーではWAFが自由に使えないため、なんちゃってWAFの様なものを作りたいとか、レンタルサーバーを新規に始めたく、CGIにバナー広告を差し込みたいといったケースがある場合に、今回のような手法は便利だろう。
今時、往年のレンタルサーバーを新規に始め、それもバナー広告を出したいと考える人物がいるかどうかは謎だが、共通的に何かを差し込みたいなど、何かしら活用方法はあるかもしれない。
2026/01/30(金)さくらのレンタルサーバーに任意のCPANモジュールを入れて使う方法
更新日:
投稿日:
投稿日:
ググって出てきた記事が軒並み古くて役に立たなかったので、令和八年最新版として書いておく。
やり方
- CPANMのインストール
curl -L https://cpanmin.us | perl - App::cpanminus - CPANMのパスを
.cshrcに書く
私はzshを使っているため以下に.zshrcでの設定例を記述する。デフォルト環境はcshなので、cshの人は.cshrcに同じようなことを書けば成り立つはずだ。echo PATH=${HOME}/perl5/bin:${PATH} - local::libをインストールする
local::libはroot以外にあるCPANモジュールを使うためのものらしい。これを自分のホームディレクトリ配下に入れるようにコマンドを流す。cpanm --local-lib=~/perl5 local::lib && eval $(perl -I ~/perl5/lib/perl5/ -Mlocal::lib)
使い方
以下のようなコマンドを流すとパスを指定してCPANモジュールを取得・展開できる。
# 書式
cpanm -l <パス> <モジュール名>
例えば以下を流すとpwd配下にextlibディレクトリが生成され、IP::Geolocation::MMDBがダウンロードされて展開される。勿論、依存関係も勝手に解決してくれる。
cpanm -l extlib IP::Geolocation::MMDB
モジュールを利用するときはライブラリの配置されているルートを指定し、次にモジュール名を指定するとうまくいくようだ。
use lib './extlib/lib/perl5';
use IP::Geolocation::MMDB;
あとがき
https://cpanmin.us/を見に行くと以下の記述があり、辿ってみると日本の人が作っていてちょっと驚いた。
# This is a pre-compiled source code for the cpanm (cpanminus) program.
# For more details about how to install cpanm, go to the following URL:
#
# https://github.com/miyagawa/cpanminus
2025/02/27(木)Next.jsの設計に対する最近の考えを殴り書き
投稿日:
最近思っているNext.jsを使った画面設計に関する考えを箇条書きで雑に殴り書きしていく。この記事は考えの垂れ流しなので深い説明はしない。AppRouterではなく、PageRouterの考え。
- TypeScriptで実装し、型が騙せるような実装は極力避け、コードによる戻り値の型指定は不具合の原因になることがあるため、可能な限り型推論に任せる
- SOLIDな設計を意識することで疎結合でテストしやすい設計になる
- Clean Archtectureを意識することでSOLIDのSを意識しやすくなる
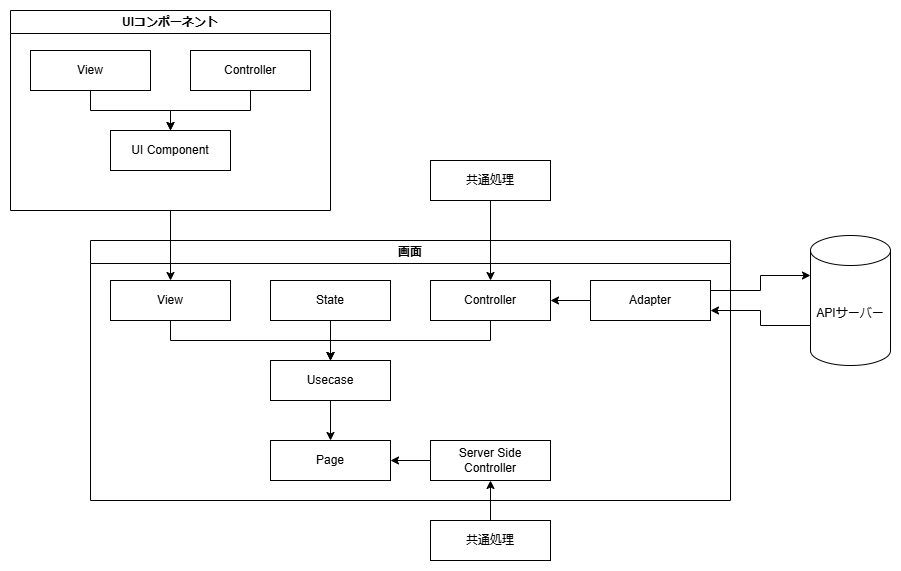
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
- ただこれはModelに相当するものがなく、ビジネスロジックの共通化に課題が出てくるのと、ControllerがFatになりすぎると考えており、そこが課題になると考えている。
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
- テストが容易なコードは必然的に疎結合になる
- 疎結合にする場合、命名を抽象的にしておくと処理の入れ替えが容易になる(命名が具象、つまり実装の詳細に依存しないため)
- 疎結合にするとパーツが増えるので認知負荷が上がる
- 疎結合でかつ、命名が抽象化されている場合、仕様を知らない人にとっては実際の処理内容を推測しづらくなる
- つまりこれは属人性が増えると考える
- 例外についてはErrorクラスを継承し、カスタム例外を作成して、用途に応じたハンドリングができるようにする
- 原則として処理を止める場合にのみ用いるべきで、続行する場合には使わない
- 例外は原則としてスローして、カスタムエラーは特定の階層でフィルタしてハンドリング、全てすり抜けてきたものはルート処理でキャッチしてハンドリングすることで、取りこぼしをゼロにする。例外の握り潰しは原則行わない
- 基本的にすべてロギングする
- 処理を継続するものについては例外とせず、ワーニング用の処理フローを作成し、それに則って行う(例えば入力バリデーションはワーニング)
2025/02/27(木)スマホサイトでのキーボード挙動まとめ
投稿日:
スマホでWebを見てるときにキーボードがUIにかぶって操作しづらくなることがあるので、いくつかのサイトでどうなっているか調べてみた。
去年の9月にAndroid Edgeで調べた内容なので、今とは事情が異なるケースもある。Android Chromeでは起きなかったケースもあったので、Edge特有の挙動と思われる。
ログイン画面
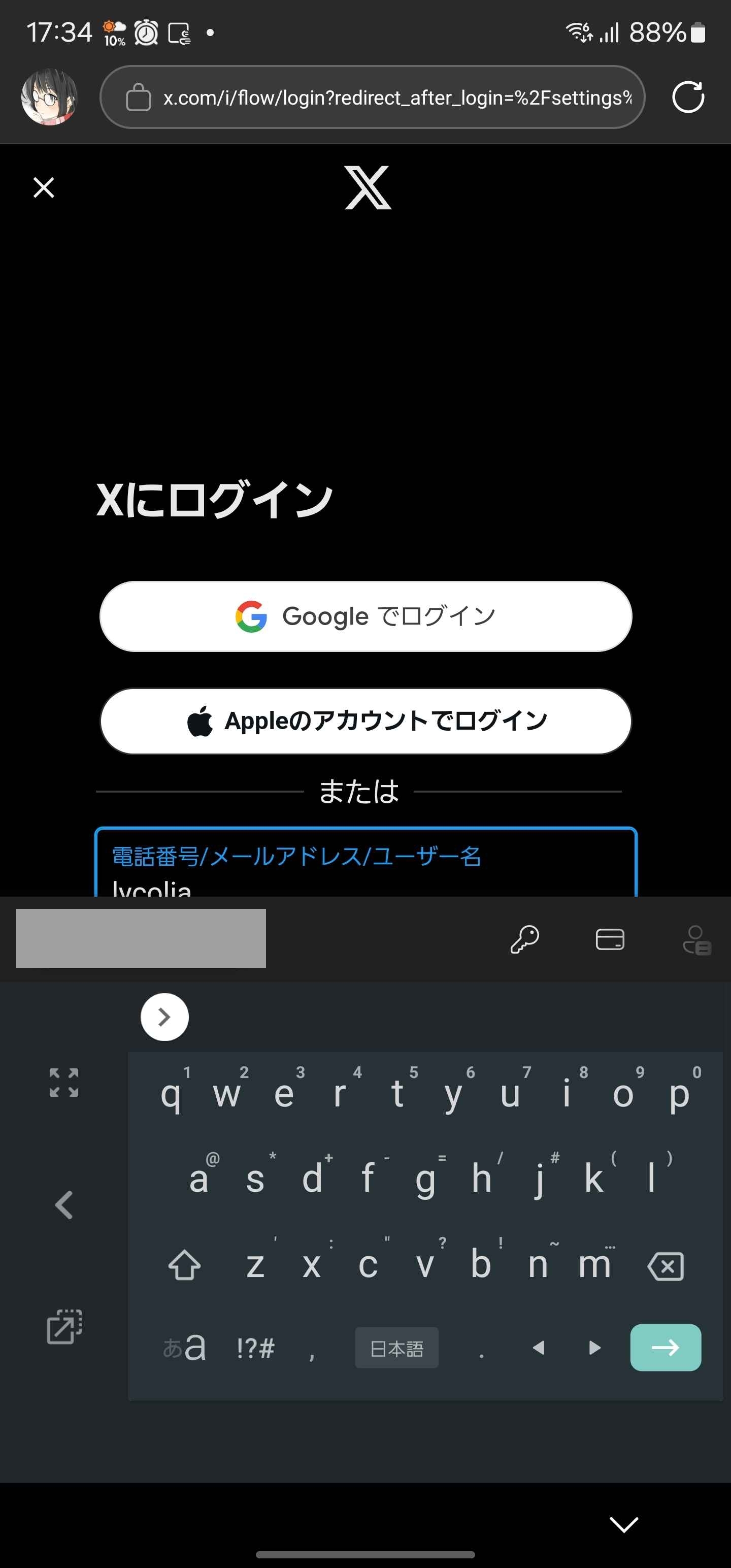
キーボードが入力欄やログインボタンにかぶる。
ミュート設定
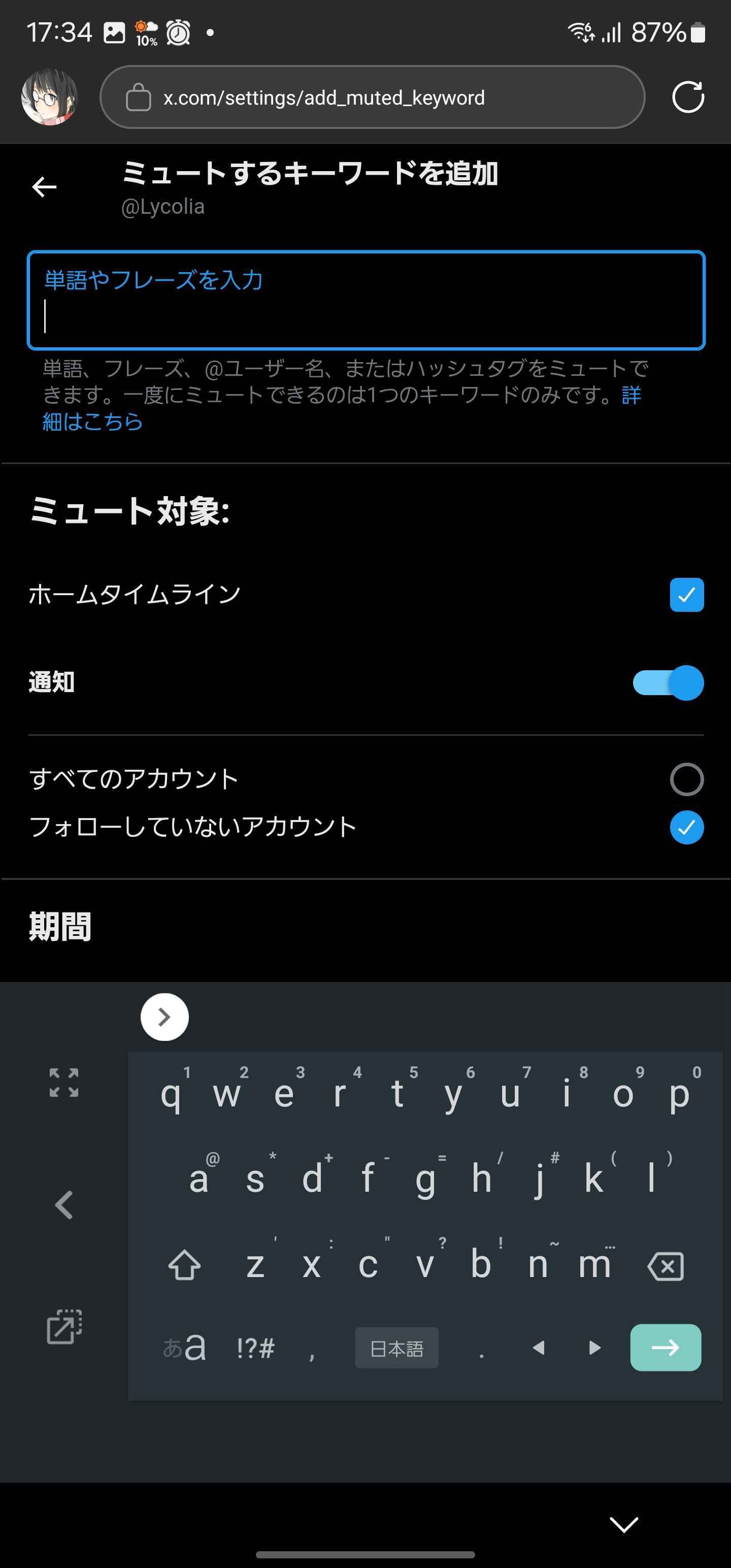
入力欄が上にあるためかぶらない。
投稿画面
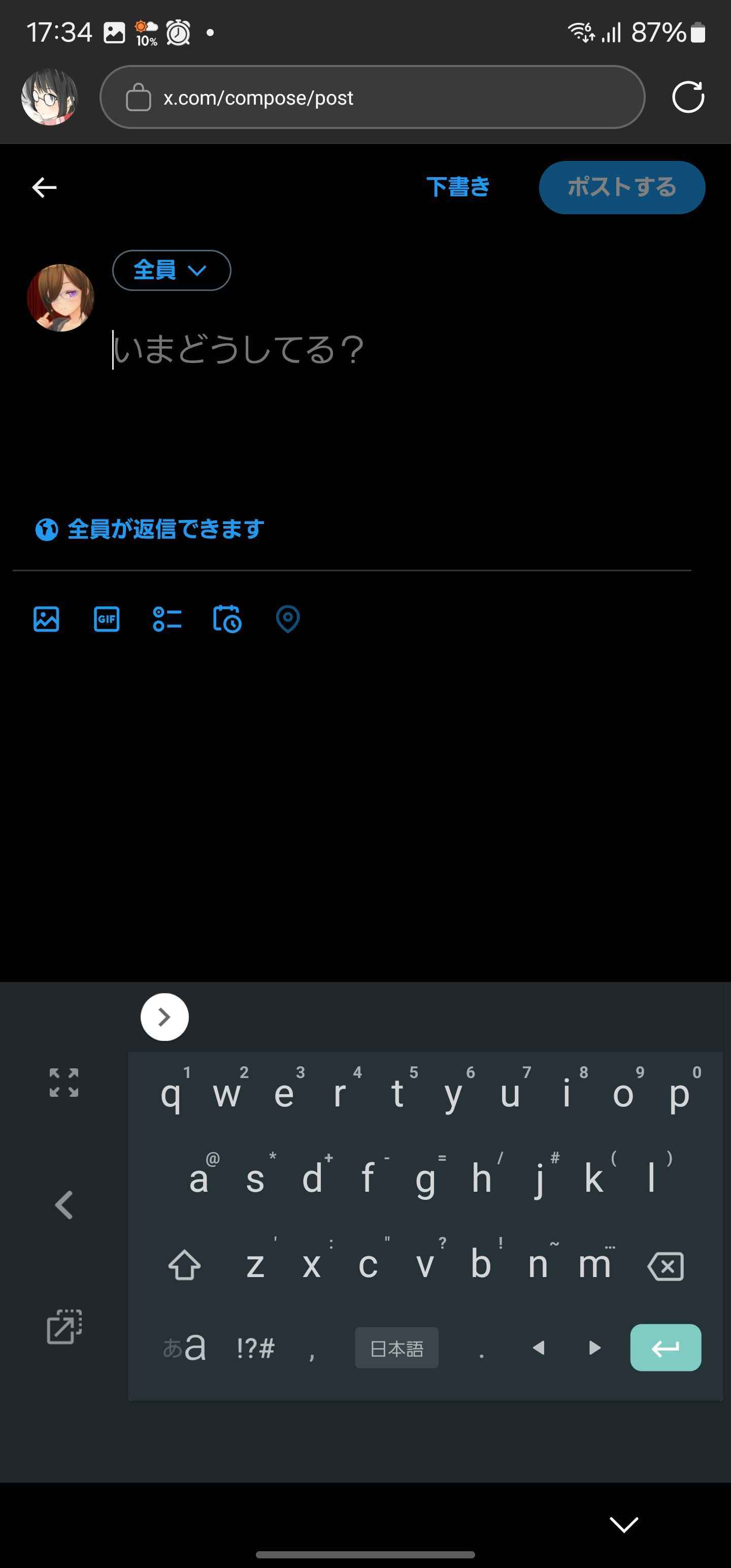
入力欄が上にあるためかぶらない。
YouTube
コメント画面
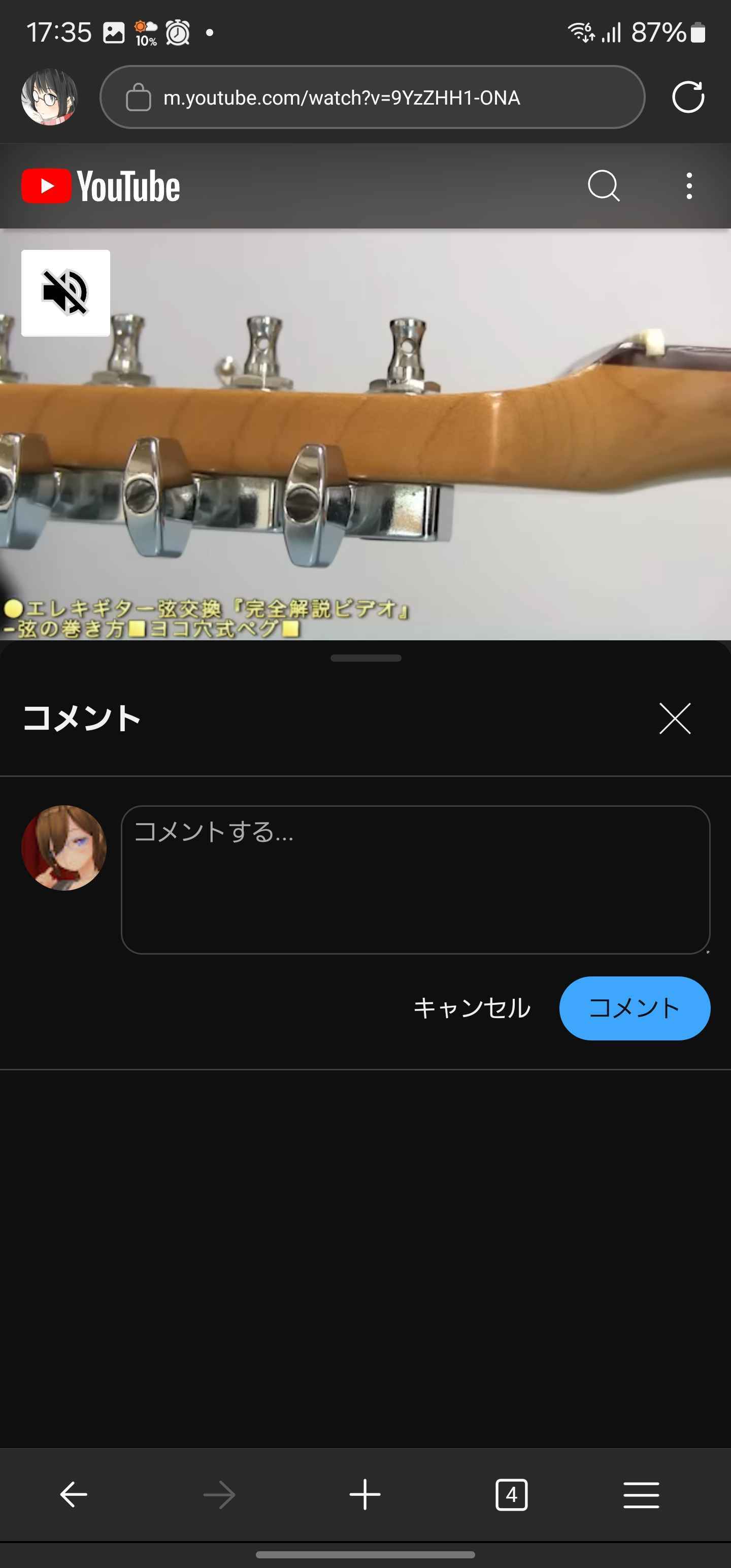
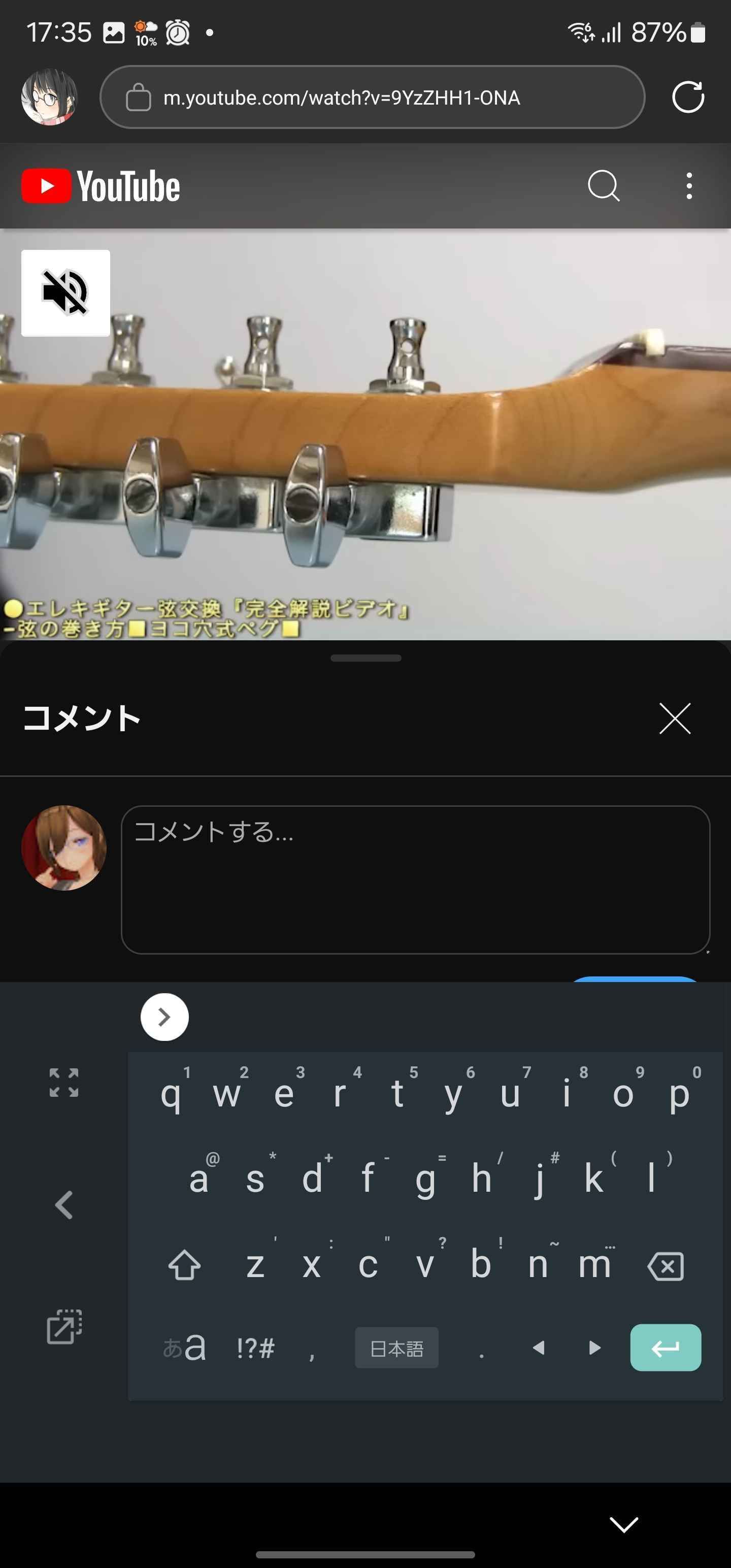
キーボードがボタンにかぶる。
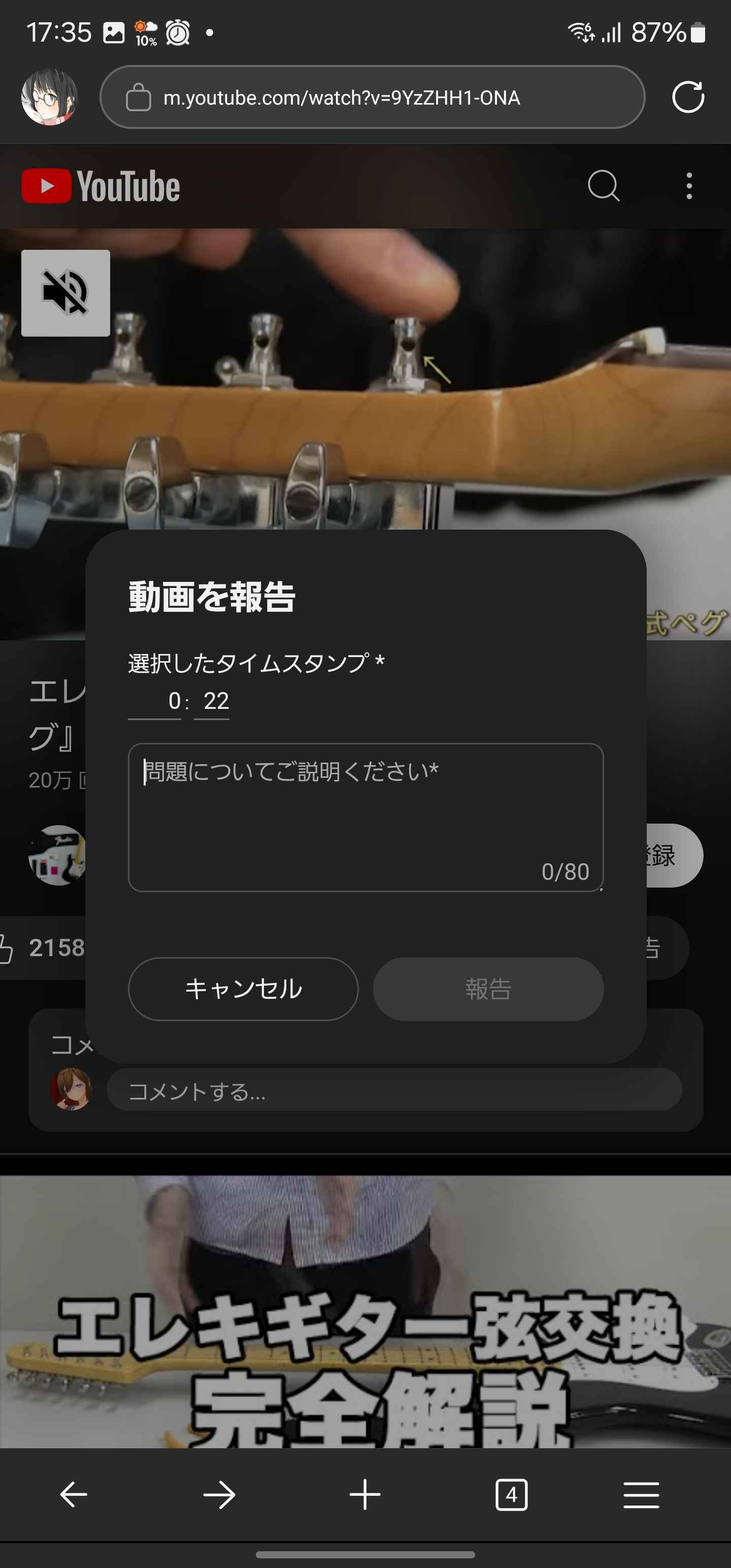
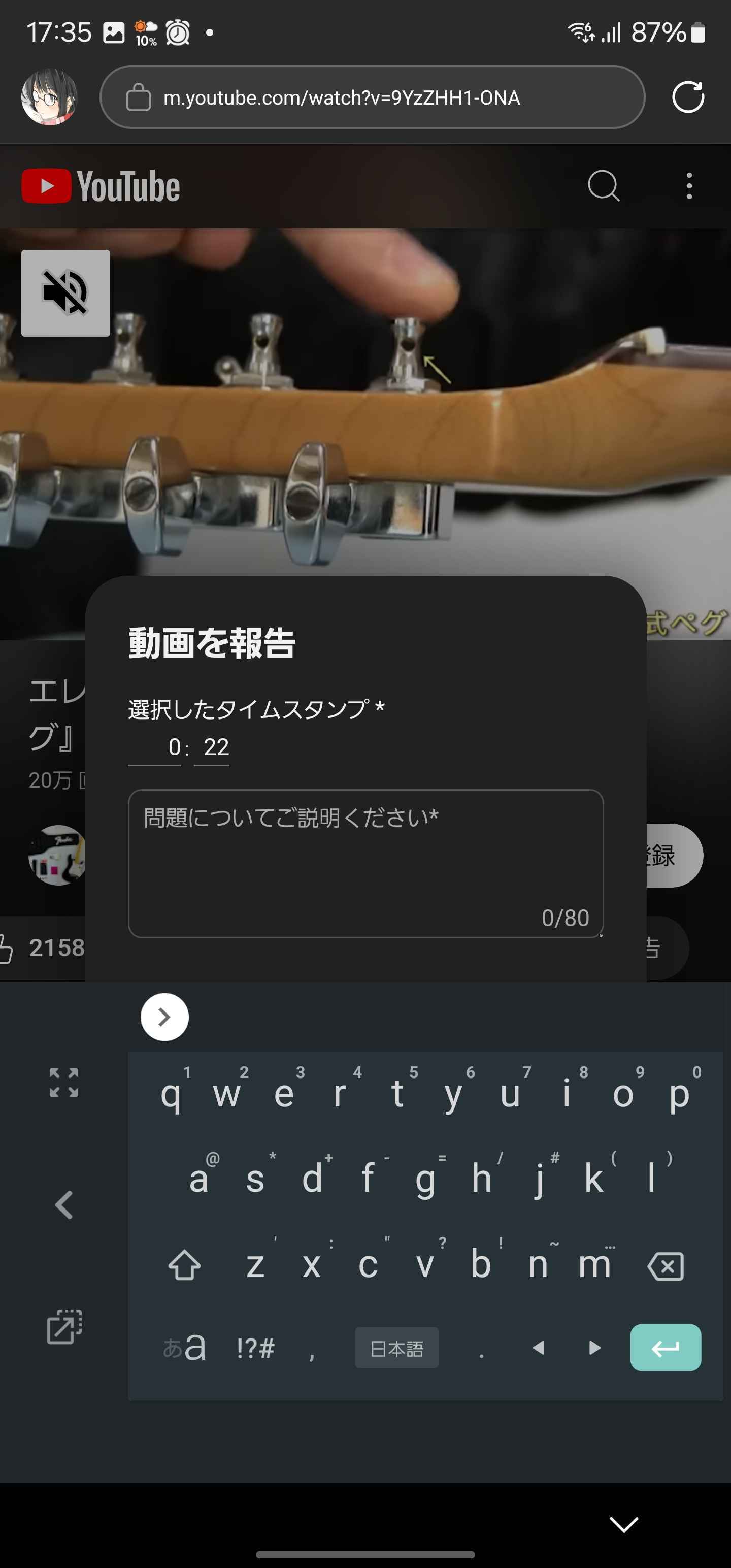
通報モーダル
キーボードがボタンにかぶる。
GitHub
Issueのコメント画面
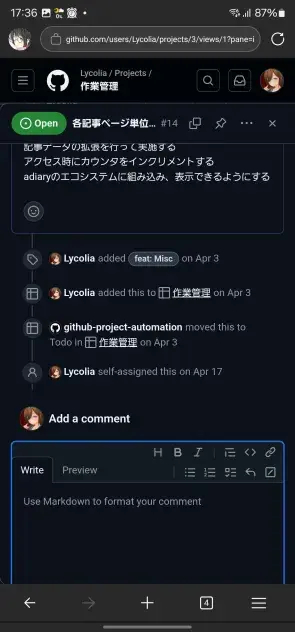
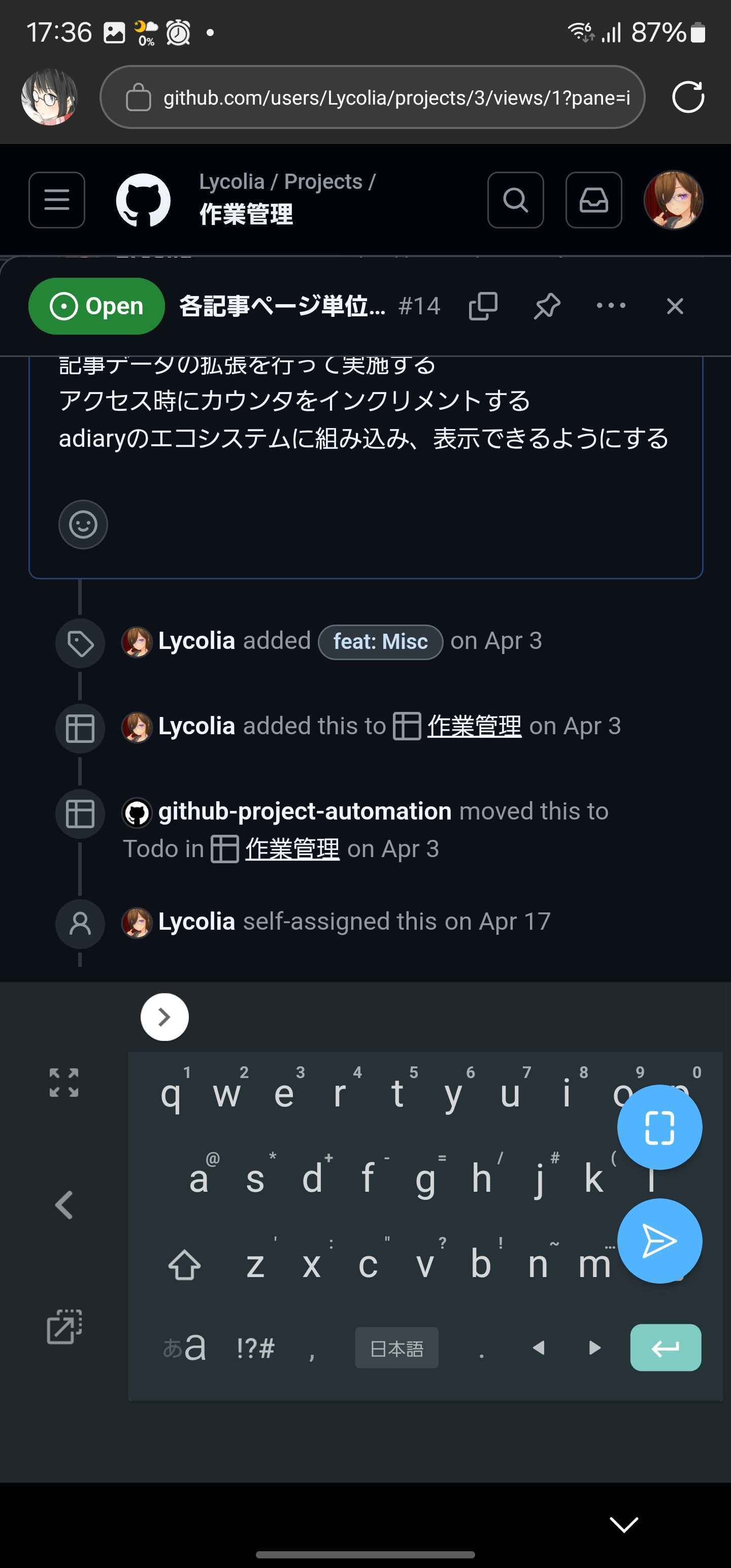
入力欄が丸ごとキーボードにかぶる。
一休
検索モーダル
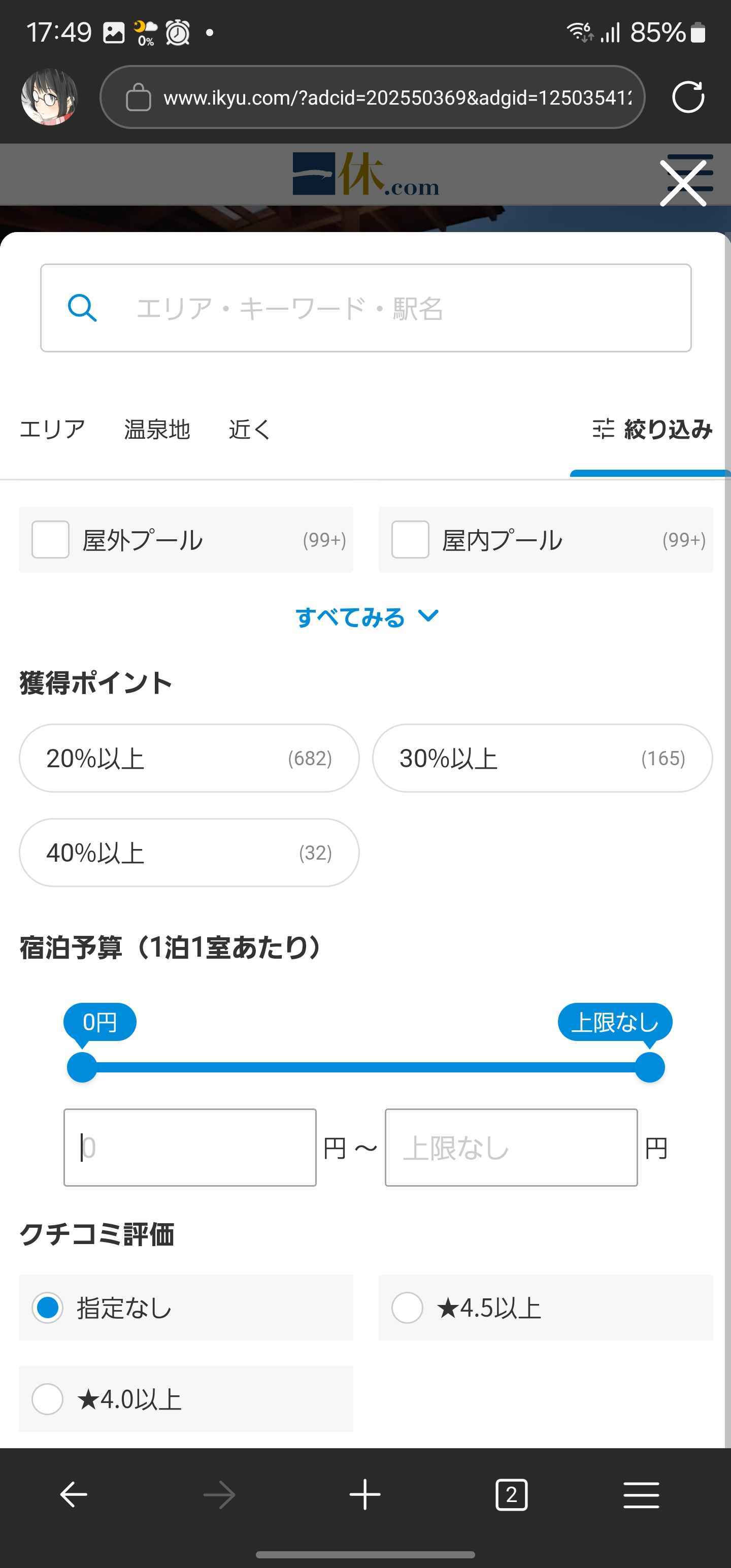
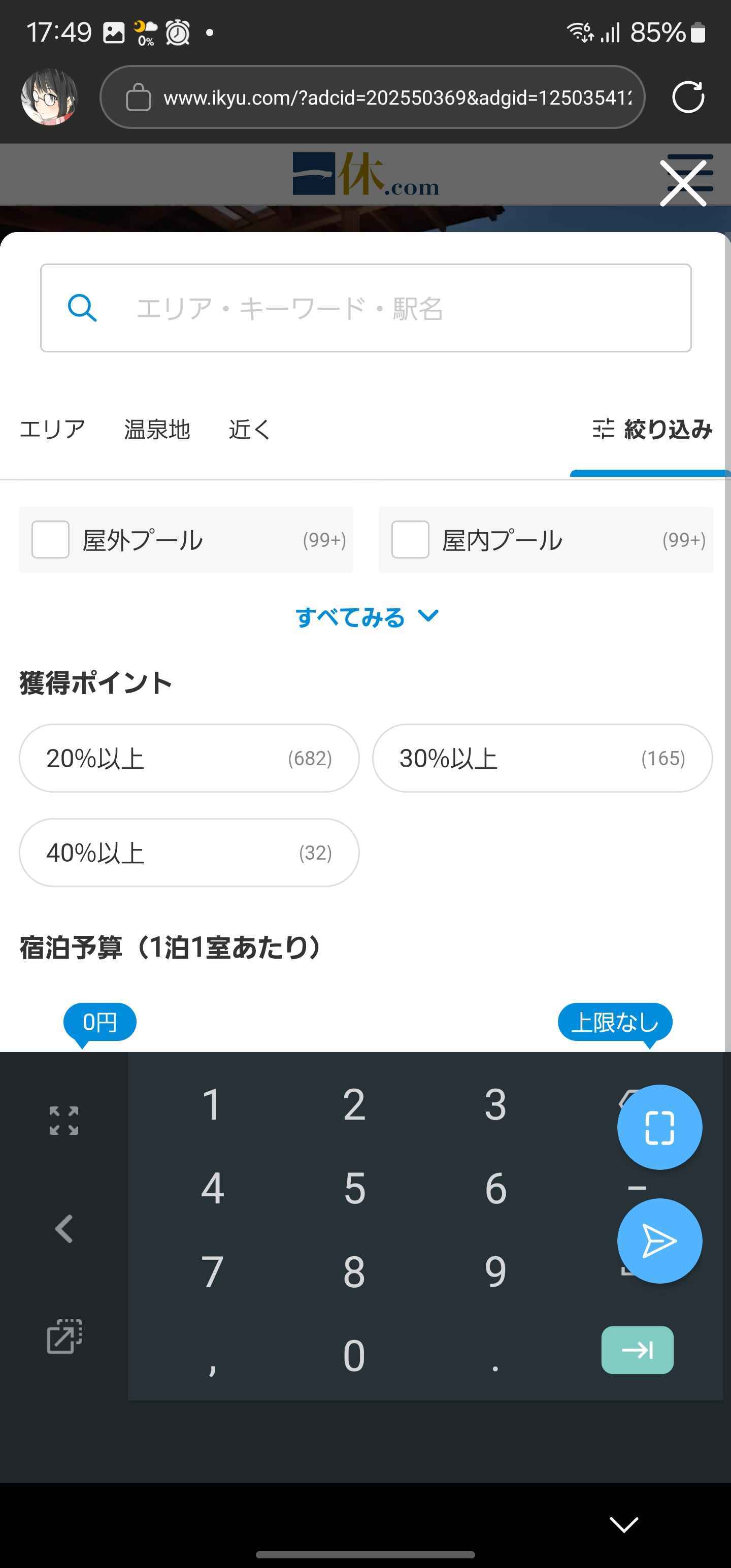
宿泊予算の入力が丸っとかぶる。
じゃらん
検索画面
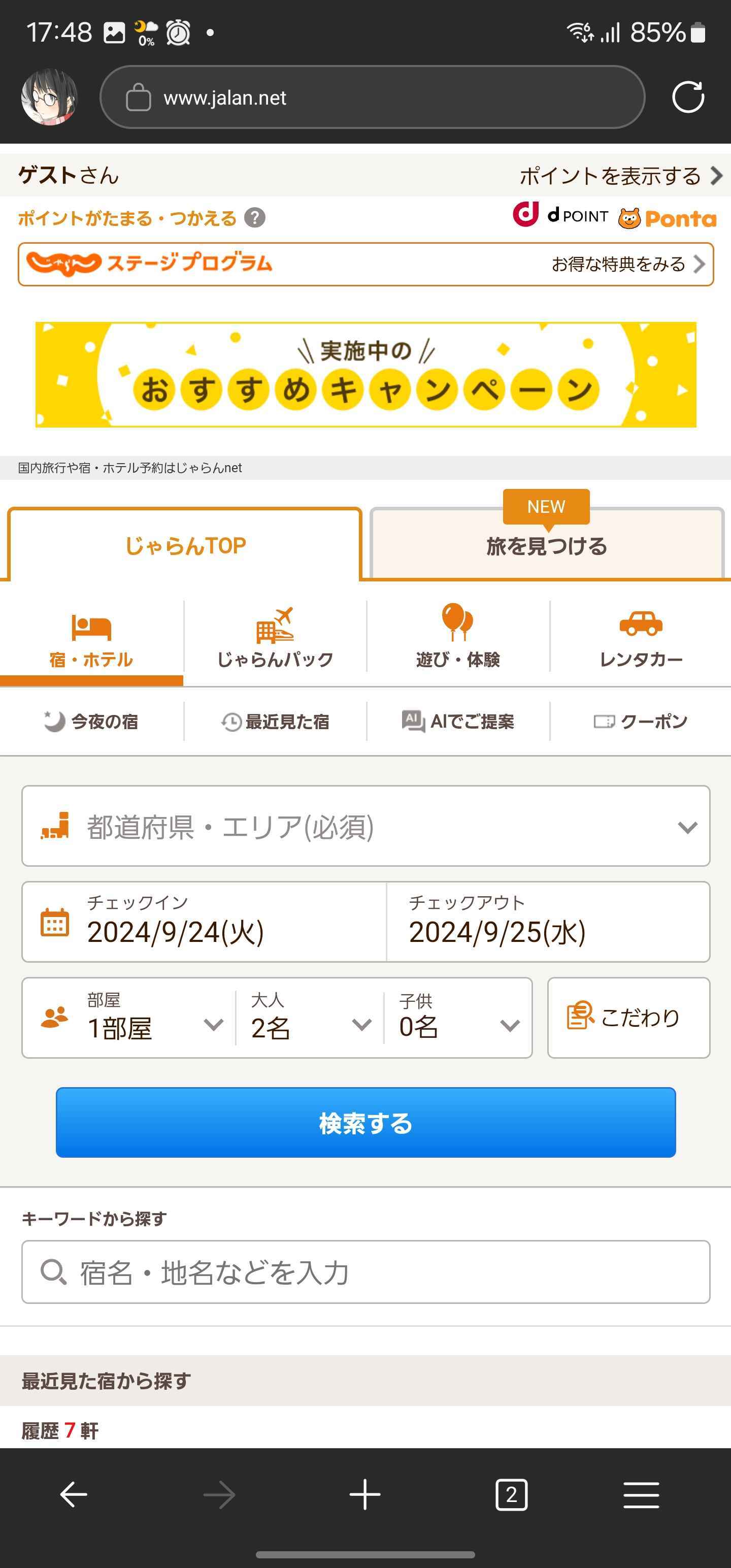
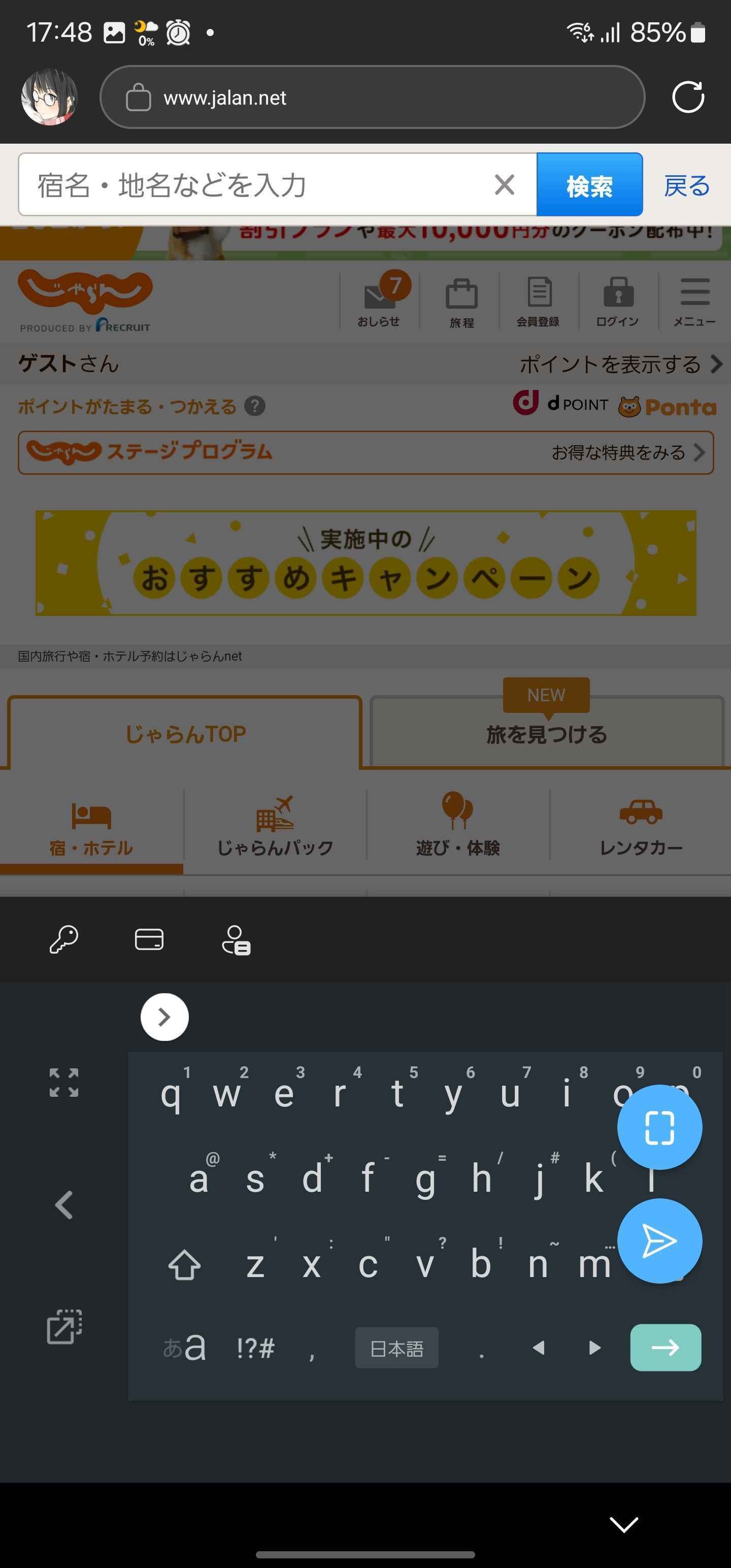
キーボードと被らないようにするためか入力UIをモーダルにして画面トップに出すように工夫されている。これなら大抵の端末やブラウザで対応できそうなので、よくできていると思う。
Amazon.co.jp
レビュー画面
入力状態になると若干のラグの後に画面下に余白ができ、入力状態が外れると同様のラグの後、画面下の余白が消えるという挙動をする。
割と凝ったJSで何かしらの計算を行い、かなり頑張って調整しているようだった。タイムラグがあるのはイベント発火もあるだろうが、キーボードの検出や画面サイズに応じた余白計算に時間がかかっているのもあるのだろう。
ここまで凝った実装をしているのは他のサイトでは見られず、Amazon.co.jp特有に見えた。なお、Amazon.comのほうは見ていない。
あとがき
この調査時点では、じゃらんとAmazon.co.jpを除き入力欄を画面の上部に配置するなどレイアウトで調整しているサイトが比較的多く、どうしてもボタンなどが隠れる傾向があるように思った。
じゃらんは強制的に画面上部に入力欄を出すようにし、Amazon.co.jpは気合でキーボードが隠れないように調整していて、腐心の跡が見られた。
なお、今回動画を作成するにあたり一部をぼかす必要があったため、やり方を調べ実践したのでAviUtlで動画の一部にモザイクをかけ、動かす方法という記事を作成し、その過程を残している。
本動画の作成過程では上手くモザイクをかけられなかったが、上記の記事を作っているときに上手く行くようになったので、本記事の動画はモザイクではなく、ぼかしとなっている。