2026/05/17(日)Animaの生成速度を改善してみた
更新日:
投稿日:
投稿日:
前回のAnimaの正式版が出たのでベンチマークやNovelAIと品質比較してみたでは以下の通り、生成時間が長くやや厳しめだったが、もう少し何とかならないかというので試してみた。結論としては速度の向上ができた。
| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 448x576px | 6.768s |
| XL | 896x1152px | 9.090s |
| Anima | 896x1152px | 18.054s |
まず前提として私はほとんどのケースで縦長か横長でしか作らないので、前回より基準サイズを落としている。その分Upscalerで拡大する方向だ。
またベースモデルを使うこともないため、カスタマイズされたモデルを使っている。具体的には前回の検証時にはまだベースモデルが出たばかりだったので、ベースモデルしか選択肢がなかったが、Anima Cat TowerがAnima base-v1.0に対応したため、これを利用している。
確認環境
ソフトウェア
ComfyUI v0.21.1
ハードウェア
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
XL:基準サイズ512x768px
まずは比較用のXLから。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 512x768px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 42.40s |
ノード参考
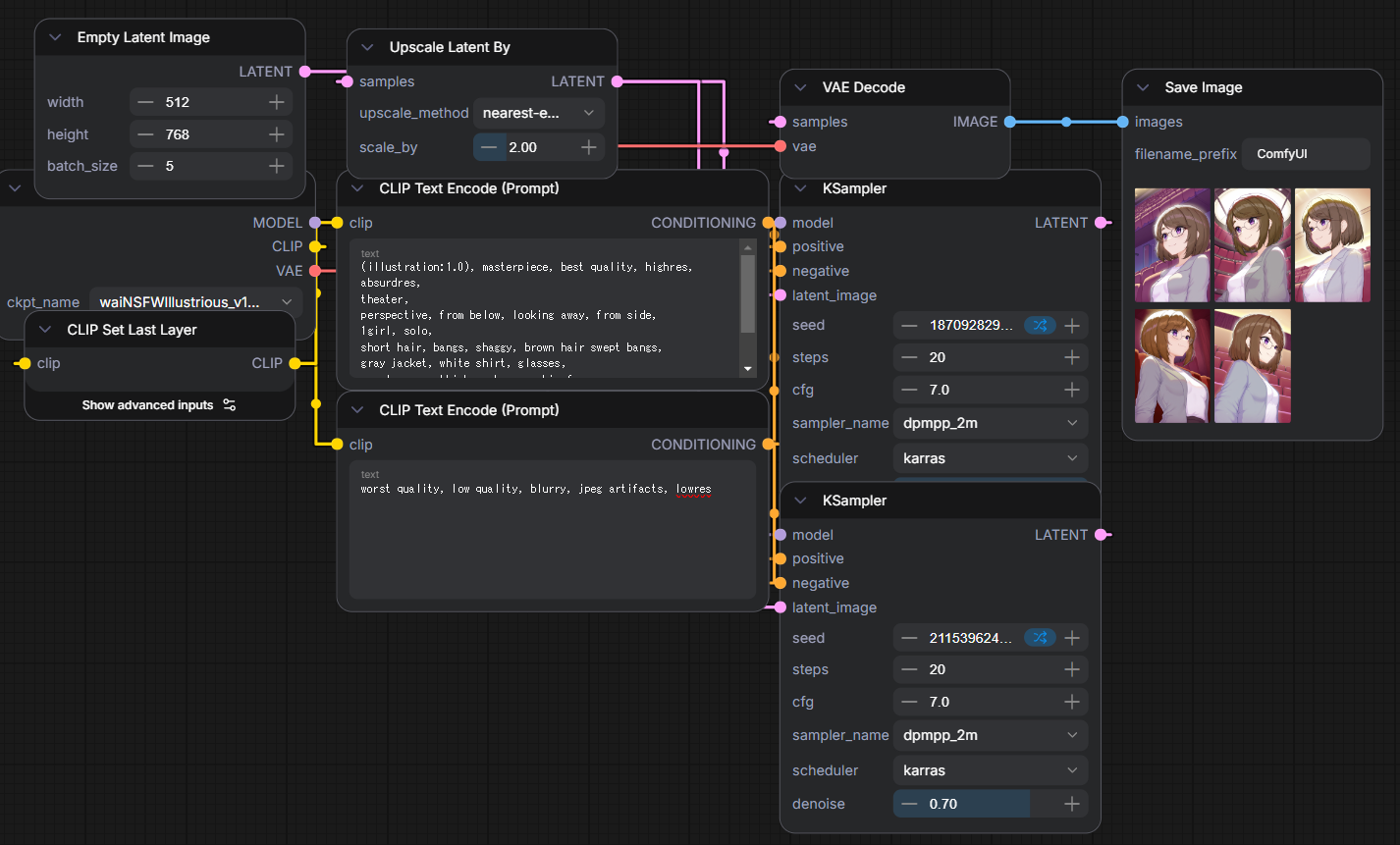
成果物




Anima:基準サイズ512x768px
次にAnimaを試す。
| 設定 | 値 |
|---|---|
| Model | animaCatTower_v10.safetensors |
| VAE | qwen_image_vae.safetensors |
| Text Encoder | qwen_3_06b_base.safetensors |
| Empty Latent Image (WxH) | 512x768px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 63.60s |
ノード参考
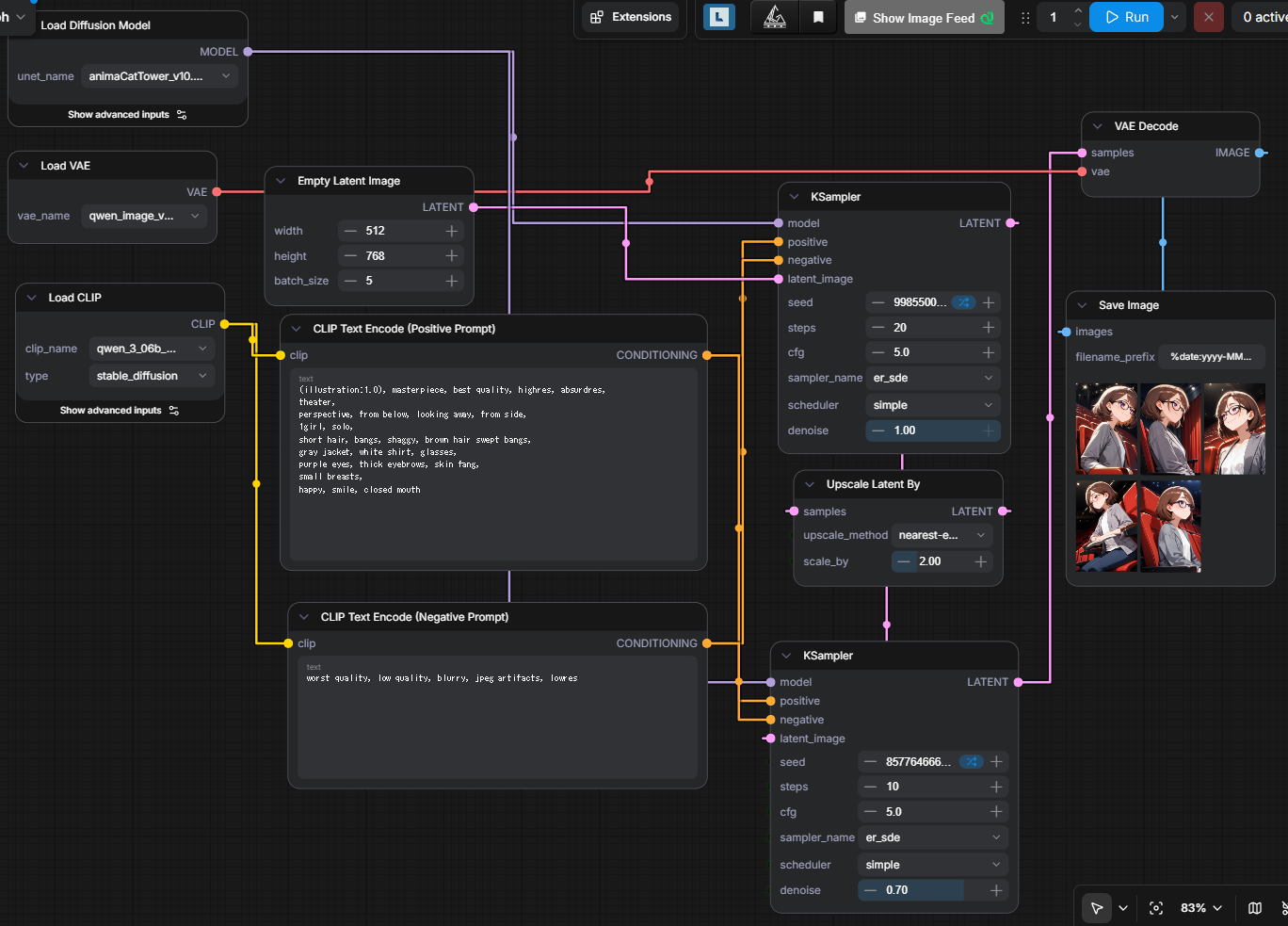
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。
成果物




まとめ
| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 512x768px | 8.48s |
| Anima | 512x768px | 12.72s |
最終成果物の画像サイズが異なるため単純比較はできないが前回18.054sだったAnimaが12.72sになり、出力画像サイズも896x1152pxから1024x1536pxに増えていることから、前回より大きな画像を短時間で生成させることに成功している。
これは基準サイズを推奨値より大幅に落としたことと、Animaに従来のXLのワークフローで使っていた二段KSampler、つまりHire.fixを導入したことと、更にその部分で後段のKSamplerの処理量を落としたり、前段のKSamplerのStepも推奨から落とすことで、全体の負荷を落としたところが大きいと思う。要は推奨値からかなりあれこれ落としている。
しかもそれでいて品質は高く出ているため、現状はいい感じだと思う。まだそんなに生成してないのでどこかに落としな穴がある可能性はあるものの、現時点では満足だ。
あとがき
ブログ用に出している生成画像は毎回似たような画像ばかり出しているが、普段からこんなのを作っているわけではなく、常日頃は全く違う画像を作っている。
ただ流石にここに出すのも微妙な気がするので、このサイトがブログである必要性について考えてみた その2の延長でどうするかは考えている。
恐らくこのサイトの課題として、このブログにすべてが集約されていてノイズが多すぎるところがある。それはよくもあるのだが、ゾーニングも必要だと思う。キッティング記事と料理のレシピと旅行がごちゃ混ぜな時点で探しづらいし、そこに大分アレゲなAI生成画像を突っ込むのはさらにおかしなことになってしまう。
恐らく一定のジャンルごとにサイトを分割するのがよいと思っているが、まだどうするかは考え切れていない。ただ同時に全ての記事のフィードを垂れ流すカオスなハブもあったほうがいいとは思っている。
少なくとも画像を並べるならギャラリーのようなサイトがあることが望ましいだろう。それも内容は間違いなくアレゲなので。
2026/05/16(土)Animaの正式版が出たのでベンチマークやNovelAIと品質比較してみた
更新日:
投稿日:
投稿日:
ComfyUIを使ってみる2で先月からComfyUIに移行したわけだが、最近Animaという有力なモデルのプレビュー版が出たということで乗り換えていた。
このAnimaは基本的にComfyUI用で、これまで使ってきたAUTOMATIC1111やreForgeでは使えないという噂で、非常にいいタイミングだった。
そして本日正式版としてbase-v1.0が出たのでベンチマークしてみることにした。また、出力品質が以前と比べて非常に向上しており、絵柄再現やキャラ再現ができたため、NovelAIとの簡単な比較もしている。
確認環境
ソフトウェア
ComfyUI v0.21.1
ハードウェア
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
りこベンチ:XL:基準サイズ448x576px
これまでのりこベンチは基準となる画像サイズ(Empty Latent Image)を768x768pxで実施していたが、Animaでは896x1152pxが基準となる。
このため、まずはUpscaleで倍にすることを考え、画像の基準サイズを448x576pxに変更した、りこベンチで計測した。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 448x576px |
| Upscale | x2.00 |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 33.84s |
ノード参考
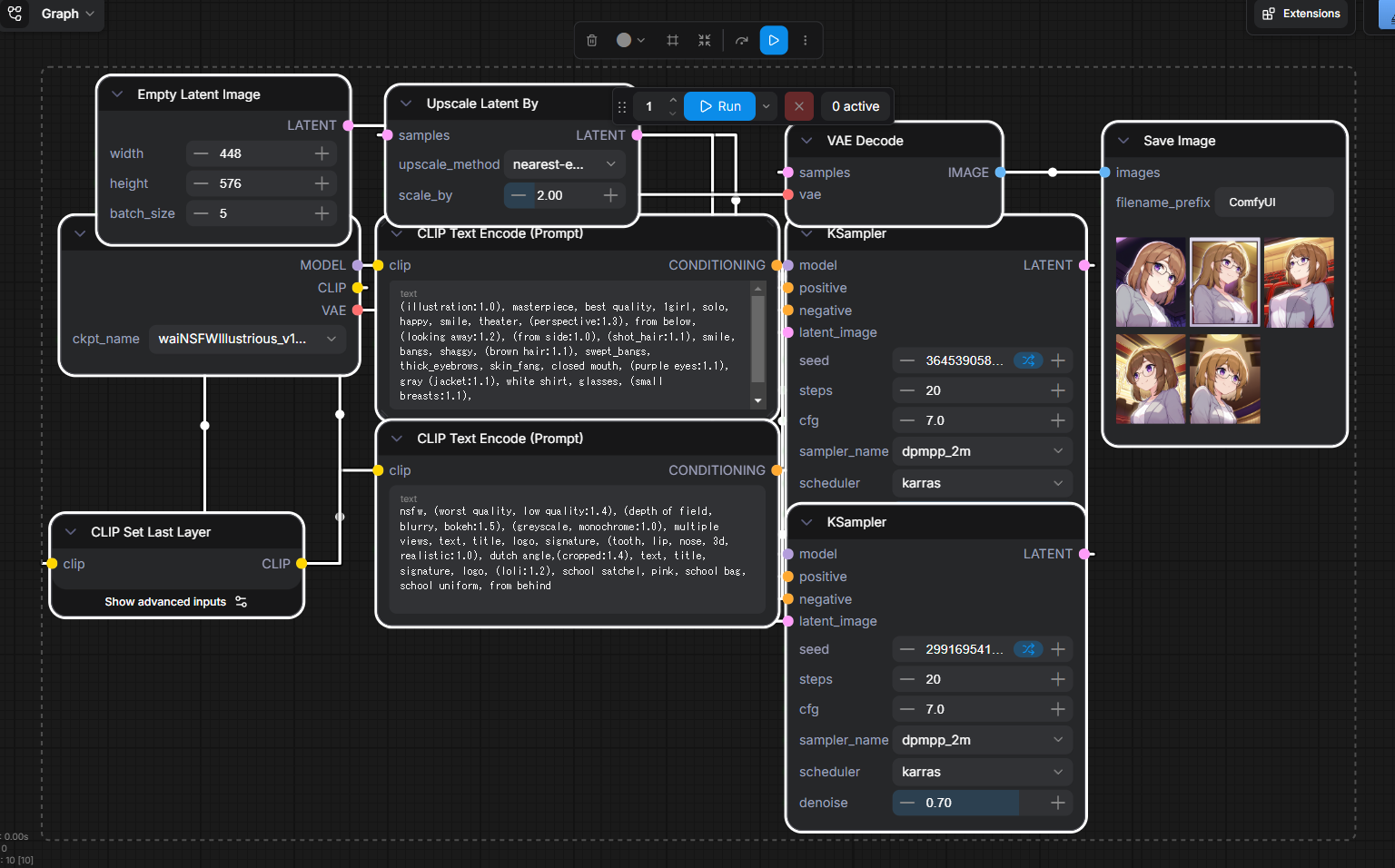
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。
成果物




りこベンチ:XL:基準サイズ896x1152px
次はUpscaleなしで等倍の896x1152pxが出る条件で計測した。
| 設定 | 値 |
|---|---|
| Model | waiNSFWIllustrious_v150.safetensors |
| VAE | なし |
| Text Encoder | なし |
| Empty Latent Image (WxH) | 896x1152px |
| Upscale | なし |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 45.45s |
ノード参考
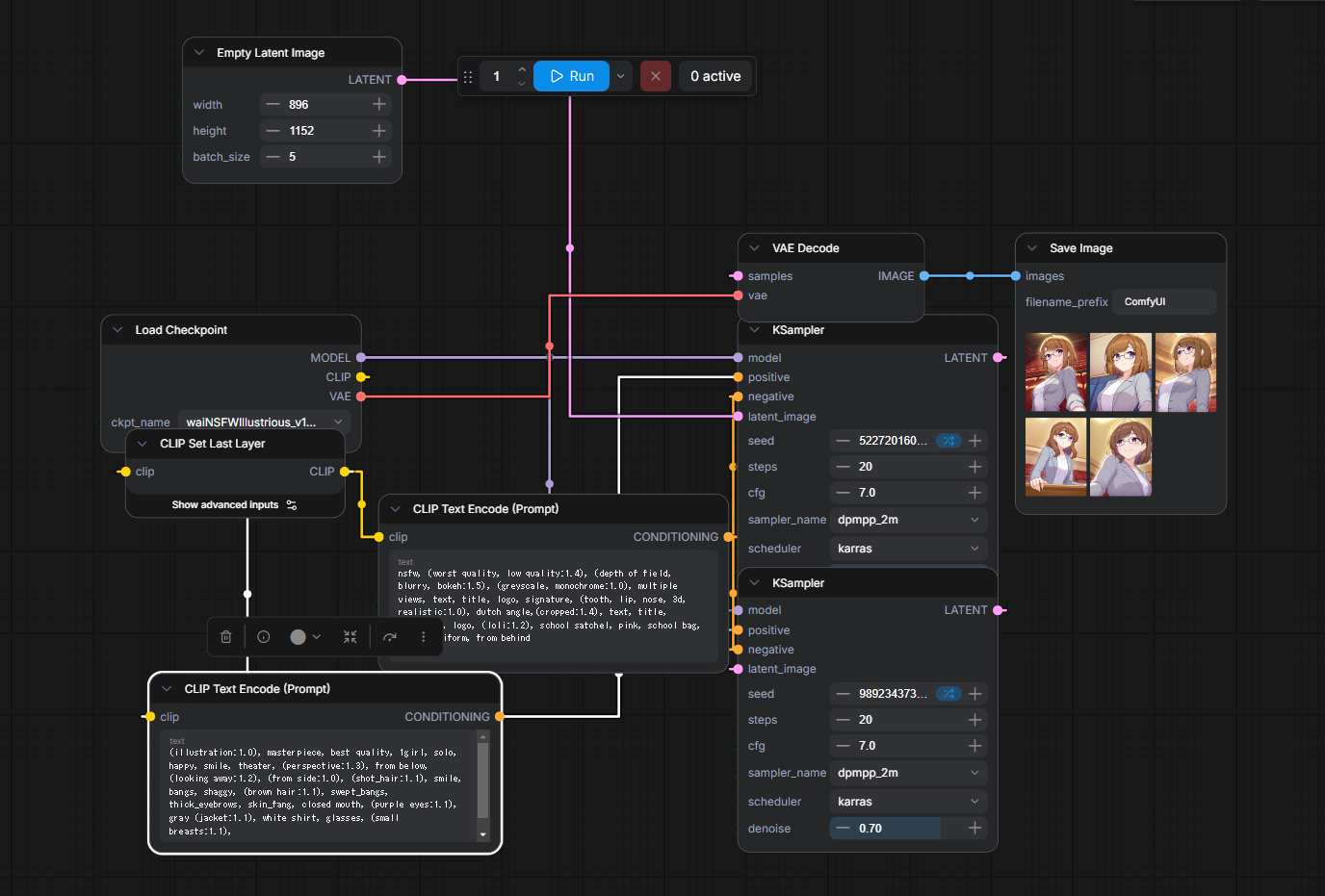
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。
成果物




りこベンチ:Anima:基準サイズ896x1152px
| 設定 | 値 |
|---|---|
| Model | anima_baseV10.safetensors |
| VAE | qwen_image_vae.safetensors |
| Text Encoder | qwen_3_06b_base.safetensors |
| Empty Latent Image (WxH) | 896x1152px |
| Upscale | なし |
| 二段KSampler(Hire.fix) | 有 |
| 5枚生成時の所要時間 | 90.27s |
ノード参考
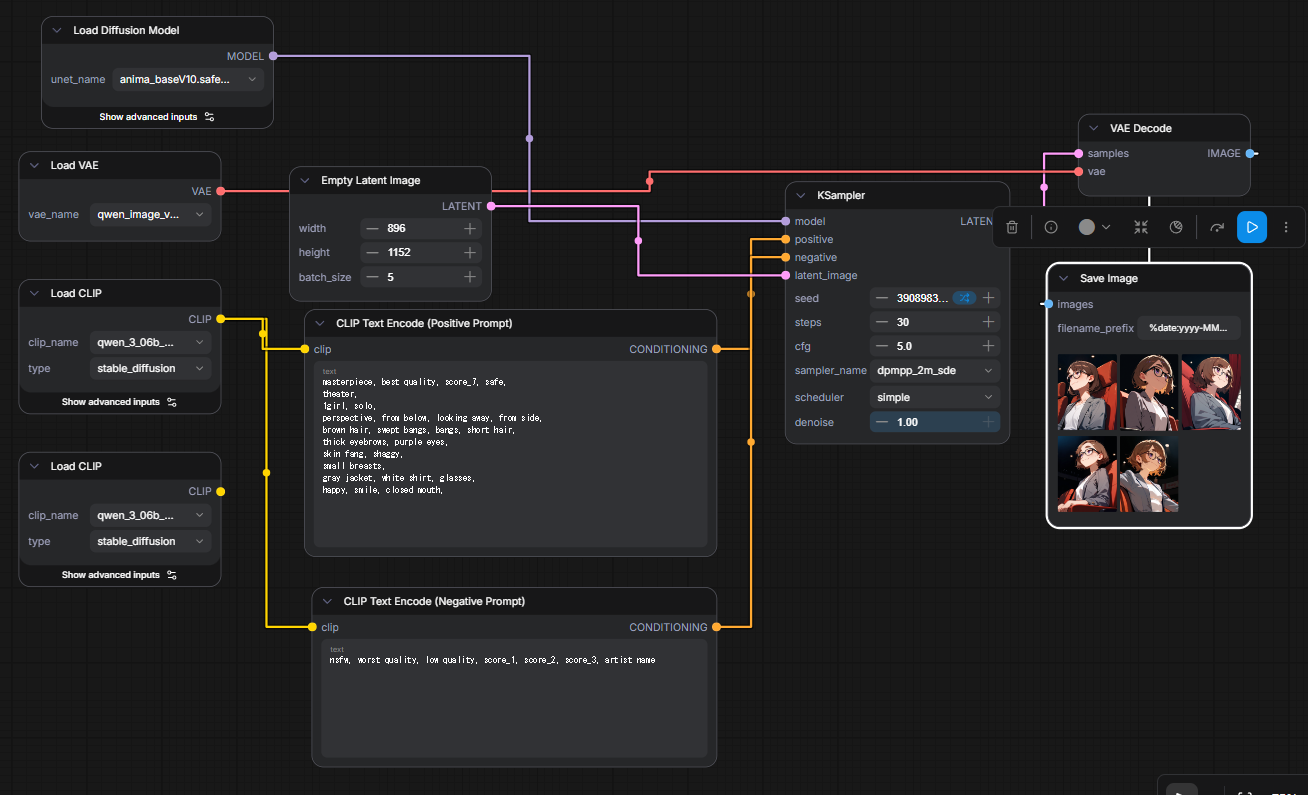
左下に何処にも繋がっていないノードがあるが、これは消し忘れたゴミである
詳細は以下の成果物をComfyUIに突っ込めば出るので割愛。
成果物




まとめ
| モデル | 画像の基準サイズ | 1枚辺りの生成速度 |
|---|---|---|
| XL | 448x576px | 6.768s |
| XL | 896x1152px | 9.090s |
| Anima | 896x1152px | 18.054s |
以上が今回のベンチの結果だが、Upscale前提だと生成速度が3倍にもなっている。これは見方次第ではやや厳しいタイムだ。
しかしComfyUIはWorkflowsを工夫すれば一回叩くだけで複数のシーンを出すことができるため、A1111やNovelAIのように張り付かなくて良い点を考慮すれば、さほど気にならないかもしれない。
またAnimaではHirefix(二段KSampler)なしにXLより高い品質の画像を出力できているように見えるため、ここも良いポイントだ。
生成速度については「Anima-Turbo Coming soon.」と書かれているため、近日中により早いものが出るかもしれない。高品質版かもしれないが何も書いてないので実際のところは謎だ。
おまけ




これはAnimaのプレビュー版であるpreview3-baseから作られたanimaCatTower_v05.safetensorsで作った画像だが、非常に品質がいい。
恐らくbase-v1.0で作り直されれば、より品質が高まるだろう。
Animaは絵師指定による絵柄の再現ができる
NovelAIには劣るものの、これまでLoraがないと厳しかった絵柄の再現がある程度できる。いくつか実際に比較してみた。
黒星紅白
やや破綻が見られるものの、絵柄としてはだいぶ出ていると思う。NovelAIほど正確さがないのはある意味で便利かもしれない。
| Anima | NovelAI |
|---|---|
 |
 |
カントク
ディティールはそこまでないが、大まかにはそれっぽいのが出せていると思う。NovelAIと比べるとどうしても劣る。
| Anima | NovelAI |
|---|---|
 |
 |
いとうのいぢ
これがいとうのいぢの絵柄見えたら大分目が悪いと思う。学習量が少ないのか精度が悪い。NovelAIは流石に圧巻である。ただNovelAIも絵柄が古く、ハルヒ時代といった感じだ。最新ののいぢという感じはしない。
| Anima | NovelAI |
|---|---|
 |
 |
☆画野郎
遠目に見えれば見えなくはないが、だいぶ厳しい。線の丸みと色の淡さはそれっぽいかもしれない。NovelAIの再現性は流石である。
| Anima | NovelAI |
|---|---|
 |
 |
キャラ指定で絵が出せる
これも従来であればLora或いは、専用のモデルが必要だったが、一応出せるようになっている。
但し単純なプロンプトでは品質が悪くなりがちで、NovelAIと比べると勝負にすらならないレベルだ。とはいえ、それができるようになったというだけでも十分すごい。
天音かなた
ここまでの品質のものは中々出ないので奇跡の一枚に近いが、天音かなたを出すことができる。10回くらい回したが、大半は天音かなたのような何かだったので、安定性はない。
NovelAIでは非常に安定して天音かなたを出力できる。
| Anima | NovelAI |
|---|---|
 |
 |
樋口楓
これも奇跡の一枚に近いが、泣きボクロがないけど樋口楓に見える何かは出ている。
勿論、NovelAIのほうが再現性が高く安定している。
| Anima | NovelAI |
|---|---|
 |
 |
キノ
キノに見えなくもないくたびれた男性のようなものが出てきた。これでも奇跡の一枚で、酷いと人の姿さえ出てこないことがあった。
NovelAIは安定しており、何枚か出してみたところ特に指定していないにもかかわらず、パースエイダーを構えているものを出すことさえできた。但し指が破綻していたのでここには載せていない。
| Anima | NovelAI |
|---|---|
 |
 |
アスナ
いわれてみればアスナに見えなくもないが、他人の空似レベルである。
NovelAIは(ry
| Anima | NovelAI |
|---|---|
 |
 |
あとがき
XL系と比べると出力時間が三倍かかるが、品質は大きく向上し、絵柄やキャラの再現もある程度可能になっているためローカルで色々やるにはよくなったと思う。
ただ版権絵を絵柄丸コピーでどうこうするとか、そういった用途に使うにはまだ厳しいと感じた。
絵柄やキャラ再現はLora + Ponyが非常に優秀なので、何もなしで高品質だけど時間がかかるAnimaがどこまでいけるのかは現段階では未知数である。
しかしながらポテンシャルは感じるので、今後GPUの性能向上や、ComfyUIやモデルの進化などによって、より良い方向へ向かう可能性は十分にあるだろう。恐らくRTX7070TiになるころにはXL並みの速度にはなっていると思う。
2026/04/11(土)ComfyUIを使ってみる2
更新日:
投稿日:
投稿日:
去年の六月にComfyUIを使ってみるという記事を書いたが、当時はAUTOMATIC1111との差を覆せず、イマイチという結論に終わった。その後AUTOMATIC1111からreForgeに乗り換えたものの、ComfyUIへの未練は残っていた。そこで今回あらためて挑戦してみたところ上手くいったので、その記録を残しておく。
確認環境
ソフトウェア
ComfyUI v0.18.5
ハードウェア
前回とマザボが変わっているが、これによる差はないだろう。
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
導入方法
インストール
公式サイトからインストーラーをダウンロードして実行するだけ。
インストール先は変えてはならない。もし変えると起動してもフリーズするようになったりする。
各種設定
ComfyUI-Managerはデフォルトで入ってるので入れなくてよい。
- 設定>Comfyから言語を英語にする[1]
- Settings>Server-Configを開き、一番下までスクロールし、DirectoriesにあるOutput directoryを適当に変える
- ここが生成した画像の出力先になる
- Settings>Graph>Link Render ModeでStraight
- ノードを繋ぐ線が直線になり、見やすくなる
- Settings>Graph>Always snap to gridをON
- ノードがグリッドにスナップするようになる
- Extentionsを開きComfyUI-Custom-Scriptsを入れておくと幸せになるらしいので入れる
資材パスの変更方法
モデルなどは容量を食って重いので別のドライブに移動させる方法。
- 別ドライブのどこか適当な場所に
%HOMEPATH%\Documents\ComfyUI配下のフォルダを丸ごと移動する %HOMEPATH%\AppData\Roaming\ComfyUI\extra_models_config.yamlを開く- 取り敢えずこんくらいの設定にしておけばよいと思う。パスの尻に``が入ってると起動しなくなるので注意
comfyui_desktop: is_default: "true" custom_nodes: custom_nodes download_model_base: models base_path: E:\path\to\ComfyUI # models\Stable-diffusion checkpoints: models\checkpoints # models\ControlNet controlnet: models\controlnet # embeddings\ embeddings: models\embeddings # models\Lora loras: models\loras # models\VAE vae: models\vae desktop_extensions: # 元から記述がある部分、変える必要はない custom_nodes: C:\Users\hoge\AppData\Local\Programs\ComfyUI\resources\ComfyUI\custom_nodes
AUTOMATIC1111やreForgeの設定をワークロードに反映させる方法
一例として、りこベンチの設定の再現方法。ComfyUIはアップスケーラー周りの設定が分かってないとゴミ画像が出てくるので、アップスケーラーの設定が重要になる。
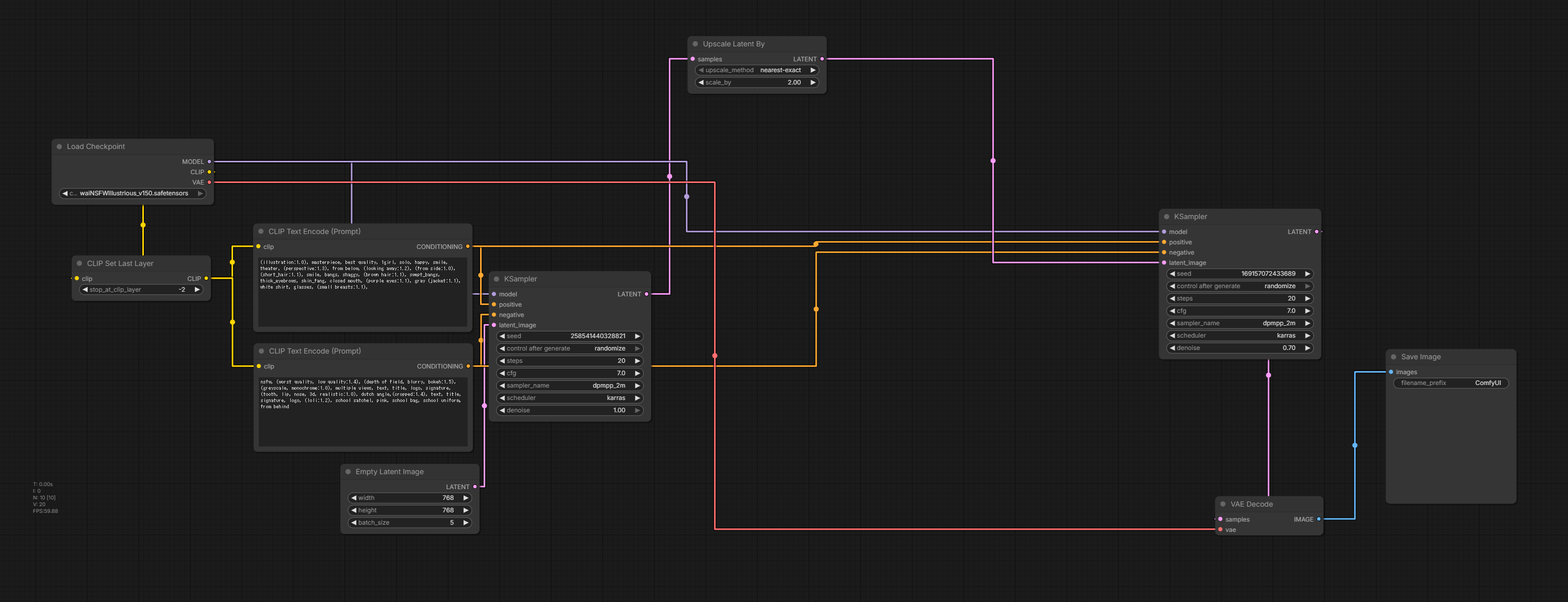
全体像としてはこんな感じで、以前書いたComfyUIを使ってみると構成するノードには大きな変わりはない。
ポイントは一段目のKSamplerでdenoiseを1.00にし、二段目で0.70にする部分だ。両方を0.70にすると画質が大幅に劣化する。
ベンチスコア
りこベンチ設定では64.76秒を記録し、AUTOMATIC1111からreForgeに乗り換えた時のスコアである81秒と比べると16.24秒も早くなっている。
使用したワークフロー
{
"id": "6de0fdb5-59c2-4625-b494-4097461da37e",
"revision": 0,
"last_node_id": 17,
"last_link_id": 25,
"nodes": [
{
"id": 4,
"type": "CheckpointLoaderSimple",
"pos": [-290, 240],
"size": [320, 100],
"flags": {},
"order": 0,
"mode": 0,
"inputs": [
{
"localized_name": "ckpt_name",
"name": "ckpt_name",
"type": "COMBO",
"widget": { "name": "ckpt_name" },
"link": null
}
],
"outputs": [
{
"localized_name": "MODEL",
"name": "MODEL",
"type": "MODEL",
"slot_index": 0,
"links": [1, 18]
},
{
"localized_name": "CLIP",
"name": "CLIP",
"type": "CLIP",
"slot_index": 1,
"links": [11]
},
{
"localized_name": "VAE",
"name": "VAE",
"type": "VAE",
"slot_index": 2,
"links": [8]
}
],
"properties": { "Node name for S&R": "CheckpointLoaderSimple" },
"widgets_values": ["waiNSFWIllustrious_v150.safetensors"]
},
{
"id": 11,
"type": "CLIPSetLastLayer",
"pos": [-260, 380],
"size": [270, 60],
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 11
},
{
"localized_name": "stop_at_clip_layer",
"name": "stop_at_clip_layer",
"type": "INT",
"widget": { "name": "stop_at_clip_layer" },
"link": null
}
],
"outputs": [
{
"localized_name": "CLIP",
"name": "CLIP",
"type": "CLIP",
"links": [12, 13]
}
],
"properties": { "Node name for S&R": "CLIPSetLastLayer" },
"widgets_values": [-2]
},
{
"id": 3,
"type": "KSampler",
"pos": [490, 240],
"size": [320, 270],
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"localized_name": "model",
"name": "model",
"type": "MODEL",
"link": 1
},
{
"localized_name": "positive",
"name": "positive",
"type": "CONDITIONING",
"link": 15
},
{
"localized_name": "negative",
"name": "negative",
"type": "CONDITIONING",
"link": 14
},
{
"localized_name": "latent_image",
"name": "latent_image",
"type": "LATENT",
"link": 22
},
{
"localized_name": "seed",
"name": "seed",
"type": "INT",
"widget": { "name": "seed" },
"link": null
},
{
"localized_name": "steps",
"name": "steps",
"type": "INT",
"widget": { "name": "steps" },
"link": null
},
{
"localized_name": "cfg",
"name": "cfg",
"type": "FLOAT",
"widget": { "name": "cfg" },
"link": null
},
{
"localized_name": "sampler_name",
"name": "sampler_name",
"type": "COMBO",
"widget": { "name": "sampler_name" },
"link": null
},
{
"localized_name": "scheduler",
"name": "scheduler",
"type": "COMBO",
"widget": { "name": "scheduler" },
"link": null
},
{
"localized_name": "denoise",
"name": "denoise",
"type": "FLOAT",
"widget": { "name": "denoise" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"slot_index": 0,
"links": [24]
}
],
"properties": { "Node name for S&R": "KSampler" },
"widgets_values": [
735067360423163,
"randomize",
20,
7,
"dpmpp_2m",
"karras",
1
]
},
{
"id": 17,
"type": "LatentUpscaleBy",
"pos": [60, 100],
"size": [270, 90],
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"localized_name": "samples",
"name": "samples",
"type": "LATENT",
"link": 24
},
{
"localized_name": "upscale_method",
"name": "upscale_method",
"type": "COMBO",
"widget": { "name": "upscale_method" },
"link": null
},
{
"localized_name": "scale_by",
"name": "scale_by",
"type": "FLOAT",
"widget": { "name": "scale_by" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"links": [25]
}
],
"properties": { "Node name for S&R": "LatentUpscaleBy" },
"widgets_values": ["nearest-exact", 2]
},
{
"id": 15,
"type": "KSampler",
"pos": [490, 550],
"size": [320, 270],
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{
"localized_name": "model",
"name": "model",
"type": "MODEL",
"link": 18
},
{
"localized_name": "positive",
"name": "positive",
"type": "CONDITIONING",
"link": 20
},
{
"localized_name": "negative",
"name": "negative",
"type": "CONDITIONING",
"link": 21
},
{
"localized_name": "latent_image",
"name": "latent_image",
"type": "LATENT",
"link": 25
},
{
"localized_name": "seed",
"name": "seed",
"type": "INT",
"widget": { "name": "seed" },
"link": null
},
{
"localized_name": "steps",
"name": "steps",
"type": "INT",
"widget": { "name": "steps" },
"link": null
},
{
"localized_name": "cfg",
"name": "cfg",
"type": "FLOAT",
"widget": { "name": "cfg" },
"link": null
},
{
"localized_name": "sampler_name",
"name": "sampler_name",
"type": "COMBO",
"widget": { "name": "sampler_name" },
"link": null
},
{
"localized_name": "scheduler",
"name": "scheduler",
"type": "COMBO",
"widget": { "name": "scheduler" },
"link": null
},
{
"localized_name": "denoise",
"name": "denoise",
"type": "FLOAT",
"widget": { "name": "denoise" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"slot_index": 0,
"links": [19]
}
],
"properties": { "Node name for S&R": "KSampler" },
"widgets_values": [
968711531111656,
"randomize",
20,
7,
"dpmpp_2m",
"karras",
0.7
]
},
{
"id": 8,
"type": "VAEDecode",
"pos": [490, 140],
"size": [210, 50],
"flags": {},
"order": 8,
"mode": 0,
"inputs": [
{
"localized_name": "samples",
"name": "samples",
"type": "LATENT",
"link": 19
},
{ "localized_name": "vae", "name": "vae", "type": "VAE", "link": 8 }
],
"outputs": [
{
"localized_name": "IMAGE",
"name": "IMAGE",
"type": "IMAGE",
"slot_index": 0,
"links": [9]
}
],
"properties": { "Node name for S&R": "VAEDecode" },
"widgets_values": []
},
{
"id": 9,
"type": "SaveImage",
"pos": [830, 140],
"size": [260, 270],
"flags": {},
"order": 9,
"mode": 0,
"inputs": [
{
"localized_name": "images",
"name": "images",
"type": "IMAGE",
"link": 9
},
{
"localized_name": "filename_prefix",
"name": "filename_prefix",
"type": "STRING",
"widget": { "name": "filename_prefix" },
"link": null
}
],
"outputs": [],
"properties": {},
"widgets_values": ["ComfyUI"]
},
{
"id": 14,
"type": "CLIPTextEncode",
"pos": [50, 460],
"size": [430, 190],
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 13
},
{
"localized_name": "text",
"name": "text",
"type": "STRING",
"widget": { "name": "text" },
"link": null
}
],
"outputs": [
{
"localized_name": "CONDITIONING",
"name": "CONDITIONING",
"type": "CONDITIONING",
"slot_index": 0,
"links": [14, 21]
}
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind"
]
},
{
"id": 7,
"type": "CLIPTextEncode",
"pos": [50, 240],
"size": [430, 190],
"flags": {},
"order": 3,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 12
},
{
"localized_name": "text",
"name": "text",
"type": "STRING",
"widget": { "name": "text" },
"link": null
}
],
"outputs": [
{
"localized_name": "CONDITIONING",
"name": "CONDITIONING",
"type": "CONDITIONING",
"slot_index": 0,
"links": [15, 20]
}
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"(illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), (shot_hair:1.1), smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, (purple eyes:1.1), gray (jacket:1.1), white shirt, glasses, (small breasts:1.1),\n"
]
},
{
"id": 16,
"type": "EmptyLatentImage",
"pos": [-250, 90],
"size": [270, 110],
"flags": {},
"order": 1,
"mode": 0,
"inputs": [
{
"localized_name": "width",
"name": "width",
"type": "INT",
"widget": { "name": "width" },
"link": null
},
{
"localized_name": "height",
"name": "height",
"type": "INT",
"widget": { "name": "height" },
"link": null
},
{
"localized_name": "batch_size",
"name": "batch_size",
"type": "INT",
"widget": { "name": "batch_size" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"links": [22]
}
],
"properties": { "Node name for S&R": "EmptyLatentImage" },
"widgets_values": [768, 768, 1]
}
],
"links": [
[1, 4, 0, 3, 0, "MODEL"],
[8, 4, 2, 8, 1, "VAE"],
[9, 8, 0, 9, 0, "IMAGE"],
[11, 4, 1, 11, 0, "CLIP"],
[12, 11, 0, 7, 0, "CLIP"],
[13, 11, 0, 14, 0, "CLIP"],
[14, 14, 0, 3, 2, "CONDITIONING"],
[15, 7, 0, 3, 1, "CONDITIONING"],
[18, 4, 0, 15, 0, "MODEL"],
[19, 15, 0, 8, 0, "LATENT"],
[20, 7, 0, 15, 1, "CONDITIONING"],
[21, 14, 0, 15, 2, "CONDITIONING"],
[22, 16, 0, 3, 3, "LATENT"],
[24, 3, 0, 17, 0, "LATENT"],
[25, 17, 0, 15, 3, "LATENT"]
],
"groups": [],
"config": {},
"extra": {
"ds": {
"scale": 1.1284491351375,
"offset": [757.6336710071444, 145.5718113186996]
}
},
"version": 0.4
}
生成された画像




reForgeと変わらない、ちゃんとした品質のものを出すことができた。
あとがき
reForgeと同じ品質で、更に早く出せることが分かったので、これは乗り換えができそうだ。
Civitaiで配布されているワークフローを見る感じ、同じ絵柄で別の構図を出すワークフローなどもあるようなので、非常に期待できる。
他にもForge Coupleのような機能もあり、全体的にreForgeより高機能で、使い方次第では何でもできそうな気配を感じるので、今回、無事ComfyUIに乗り換えられたのはとてもよかった。
今回行った調査にはClaude Opus 4.6を使い、前回の問題点の調査と、その対策方法を調べたが、非常に有益な情報が得られたので、こういったことをするにもLLMも必須の存在といえることがよく分かった。
- 日本語だと機能を探しづらいため ↩
2025/08/25(月)AUTOMATIC1111からreForgeに乗り換えたらかなり良かった
更新日:
投稿日:
投稿日:
AUTOMATIC1111の更新は長らく止まっており、新しいツールを探していてComfyUIを試したりしていたのだが、Hire fixに相当する機能に当たることが出来ず、どうにもイマイチだった。
そこでかつてAUTOMATIC1111からフォークされ、AUTOMATIC1111にマージされたForgeからreForgeが新たに派生していることを知ったので試してみたが、これがかなり良かった。生成速度は爆速になったし、複数キャラの絡みも自然にできるようになった。
reForgeは既に開発が停止しているようだが、逆に言えば安定していると言う事でもある。
というわけで試した結果をつづっていく。
導入
git pullしたらwebui.bat叩いて終わりなので特筆することはない。AUTOMATIC1111とディレクトリ構造が同じなので、extentionやmodel, loraなどの環境はそのまま引っ越せる。
爆速化したベンチマーク
前回のベンチマークでは平均生成速度2.911it/s、生成時間120秒だったが、今回は平均生成速度4.352it/s、生成速度81秒まで短縮された。
これは前回最速を記録したUltra 7 265F + 4070Tiを12秒も凌ぐ速度で、極めて速い。正直コスパでNovelAIと勝負できるレベルだ。
ベンチマーク構成
ソフトウェア
reForegeにxformersは不要とのことで、xformersを入れていない。
| Env | Ver |
|---|---|
| version | f1.0.0v2-v1.10.1RC-latest-2446-ge1dcf9b4 |
| python | 3.11.9 |
| torch | 2.7.1+cu128 |
| xformers | N/A |
| gradio | 3.41.2 |
ハードウェア
前回とマザボが変わっているが、これによる差はないだろう。
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
りこベンチ
ベンチマーク用の設定
コマンドライン引数なしでwebui.batを実行
| 設定 | 値 |
|---|---|
| Model | ntrMIXIllustriousXL_xiii.safetensors [1207404b17] |
| Clip skip | 2 |
| ENSD | 31337 |
| Propmpt | (illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), {{shot_hair}}, smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, {{purple eyes}}, gray {{jacket}}, white shirt, glasses, {{small breasts}}, |
| Negative Prompt | nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind |
| VAE | Automatic |
| Sampleing method | DPM++ 2M |
| Hires. fix | True |
| Upscaler | Latent |
| Hires steps | 0 |
| Denoising strength | 0.8 |
| Upscale by | 2 |
| Sampleing steps | 20 |
| Width | 768px |
| Height | 768px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | -1 |
生成ログ
20/20 [00:02<00:00, 6.90it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 6.96it/s]
20/20 [00:11<00:00, 1.71it/s]
20/20 [00:02<00:00, 7.06it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 7.14it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 6.98it/s]
20/20 [00:11<00:00, 1.67it/s]
200/200 [01:21<00:00, 2.46it/s]
200/200 [01:21<00:00, 1.66it/s]
前回のベンチマークでは平均生成速度2.911it/s、生成時間120秒だったが、今回は平均生成速度4.352it/s、生成速度81秒まで短縮された。
平均生成速度
4.352it/s (前回比 +1.441it/s)
生成時間
81秒 (前回比 -39秒)
まとめ
明らかに爆速になった。これだけ早ければ何の文句もない。総合点でNovelAIと勝負できるレベルといっても過言ではないだろう。
複数キャラを配置できるForge Coupleの力
Forge CoupleというExtentionsが出ており、これを使うと複数キャラをNovelAI並みの自然さで配置できる。安定性ではNovelAIには敵わないのだが、無料で勝負できるところに価値がある。これがあればもうRegional Prompterは窓から投げ捨てていい。

Forge Coupleを使えばこのレベルは朝飯前だ。因みにこれはサンプルプロンプトそのままに近いが、キャラ同士の絡みも実現できる。
キャラ同士の絡ませ方の例(NSFW)
例えば、以下の条件であれば、ふたなりアスナと直葉の断面図あり挿入シーンという難題さえこなして見せる。かなりドギツイのが出てくるので試したい人はプロンプトをよく確認してほしい。かなり地獄のようなワードが入りすぎている。
nsfw, hentai illust, {num: 2girls}, 1dickgirls and 1girls, wet hair, drool,wet and messy, {cup: asuna to suguha}, very aesthetic, masterpiece, no text, from side, female sex, female sex from behind, female only
{num}, {cup}, couple, girl, kirigaya suguha, sao, large breast, large areola, white skin, (bob cut), armpit hair, pubic hair, doggy style, x-ray, creampie, ahegao, full body
{num}, {cup}, couple, dick girl, asuna (sao), A adult tall beauty crossdresser,shemale, little breasts, sagging breats, (dark nipple), little long nipples,wetty hair, hentai anime , long gloves and high socks, enjoying,smile,heart eyes, erection foreskin dick,smegma, armpit hair, pubic hair, hairy, tatoo,normal dick, sex, cum in cevio, ahegao, full body,
Negative prompt: lowres, artistic error, film grain, scan artifacts, worst quality, bad quality, jpeg artifacts, very displeasing, chromatic aberration, dithering, halftone, screentone, multiple views, logo, too many watermarks, negative space, blank page, low quality, child, text, speaking, censored. male, boy, male sex, 1boy
Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 6, Seed: 1605499267, Size: 768x512, Model hash: c3688ee04c, Model: waiNSFWIllustrious_v110, Denoising strength: 0.85, Clip skip: 2, Hires CFG Scale: 6, Hires upscale: 2, Hires upscaler: Latent, forge_couple: True, forge_couple_compatibility: False, forge_couple_mode: Advanced, forge_couple_separator: \n, forge_couple_mapping: "[[0, 1, 0, 1, 1], [0, 0.5, 0, 1, 1], [0.5, 1, 0, 1, 1]]", forge_couple_common_parser: { }, Pad conds: True, Version: f1.0.0v2-v1.10.1RC-latest-2446-ge1dcf9b4
ポイントは一行目のfrom side, female sex, female sex from behind, female onlyと、2~3行目のキャラクター設定行にある{num}, {cup}, couple,だ。
まずfrom sideのように構図を指定していないと破綻しやすい。NovelAIのようにいい感じにはしてくれない。
次にふたなり百合をする場合、female sex, female sex from behind, female only辺りがあると良い。男が出てくる確率が目に見えて減る。
キャラクター設定についても{num}, {cup}で一行目の変数を参照し、プレイスタイルや人物属性の設定を強めることで出現率が大幅に向上する。またcoupleを付けることで、二人が出てくる確率が上がる。これがないと一人しか出てこなかったり、男が出てくる確率が増える。
トラブルシューティング
ノイズ画像が生成される

この様なノイズ画像が生成される時に「Number of Couples and Masks mismatched」というエラーが出ている場合、余計な空行が入っているのが原因なので、それを消すと直る。
Empty lines are still counted; ensure you do not leave an empty line at the end;
2025/06/20(金)5070Tiは4070Tiより性能が悪い…?
更新日:
投稿日:
投稿日:
久々にPC構成を大刷新してみたのでベンチマークをしてみたが、かなり複雑な結果になった。
大まかにはCore Ultra 7 265FはCore i7 13700に、RTX 5070 TiはRTX 4070 Tiに劣るケースがありそうなことが判明したが、結果が複雑すぎて断言しづらい。
ベンチマーク構成
ソフトウェア
| Env | Ver |
|---|---|
| version | v1.10.1-89-g2174ce5a |
| python | 3.10.6 |
| torch | 2.7.0+cu128 |
| xformers | 0.0.30 |
| gradio | 3.41.2 |
ハードウェア
スペックアップ前後で単純に計測したところ、結果に疑問を持ったのでCPUとGPUを新旧それぞれで組み合わせて全数網羅で見ている。
| デバイス | 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|---|
| CPU | Intel Core i7 13700 | Intel Core i7 13700 | Intel Core Ultra 7 265F | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti |
| MEM | Crucial Ballistix BL2K16G32C16U4B * 4 | Crucial Ballistix BL2K16G32C16U4B * 4 | Crucial CT2K16G56C46U5 * 4 | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASUS TUF GAMING Z790-PLUS D4 | ASUS TUF GAMING Z790-PLUS D4 | ASUS TUF GAMING Z890-PLUS WIFI | ASUS TUF GAMING Z890-PLUS WIFI |
FF14 黄金のレガシー ベンチマーク
4070Tiより5070Tiの方がベンチスコアが若干高く出るが、Core i7 13700よりCore Ultra 7 265Fの方が顕著にスコアが低い。
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 27,439 | 29,138 | 22,393 | 23,479 |
おまけ:ローディングタイム
構成1-2は記録し忘れたので書いていない。
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 6.5秒 | - | 7.9秒 | 8.6秒 |
ローディングタイムはストレージ依存のはずなのでCPUやGPUの性能が大きく影響することはないはずだが、かなり差が出ていたので参考程度にとどめておく。結果は小数第二位で四捨五入している。
CPUのキャッシュメモリサイズやDDR5の4枚差しによる速度低下が影響している可能性もあるが、2-1と2-2はGPUのみの差なのでよくわかっていない。ひょっとしたらグラフィック自体の読み込み速度が低下しているのかもしれない。
この差はMMORPGをする上ではかなりのハンデになるため、私が現役プレイヤーであれば、このスペックダウンは受け入れられなかっただろう。特にFF14をしていた時は誰よりも早くローディングを終えるのが自慢の一つだった。
SDベンチ
トキベンチ
ベンチマーク用のSD設定
COMMANDLINE_ARGSは--xformers --opt-channelslast --medvramを使用。
| 設定 | 値 |
|---|---|
| Model | animagine-xl-3.1.safetensors [e3c47aedb0] |
| Clip skip | 2 |
| ENSD | 31337 |
| Prompt | 1girl, toki \(blue archive\), blue archive, toki sits cross-legged in her chair. looking at viewer, cowboy shot, masterpiece, best quality, newest, |
| Negative Prompt | nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, |
| VAE | Automatic |
| Sampleing method | Euler a |
| Sampleing steps | 15 |
| Width | 1024px |
| Height | 1024px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | 50 |
生成ログ
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 15/15 [00:04<00:00, 3.12it/s] | 15/15 [00:05<00:00, 2.67it/s] | 15/15 [00:05<00:00, 2.92it/s] | 15/15 [00:05<00:00, 2.78it/s] |
| 15/15 [00:04<00:00, 3.34it/s] | 15/15 [00:05<00:00, 2.92it/s] | 15/15 [00:04<00:00, 3.35it/s] | 15/15 [00:05<00:00, 2.95it/s] |
| 15/15 [00:04<00:00, 3.34it/s] | 15/15 [00:05<00:00, 2.91it/s] | 15/15 [00:04<00:00, 3.44it/s] | 15/15 [00:05<00:00, 2.96it/s] |
| 15/15 [00:04<00:00, 3.36it/s] | 15/15 [00:05<00:00, 2.95it/s] | 15/15 [00:04<00:00, 3.46it/s] | 15/15 [00:05<00:00, 2.93it/s] |
| 15/15 [00:04<00:00, 3.32it/s] | 15/15 [00:05<00:00, 2.97it/s] | 15/15 [00:04<00:00, 3.46it/s] | 15/15 [00:04<00:00, 3.01it/s] |
| 75/75 [00:33<00:00, 2.24it/s] | 75/75 [00:35<00:00, 2.08it/s] | 75/75 [00:31<00:00, 2.40it/s] | 75/75 [00:34<00:00, 2.20it/s] |
| 75/75 [00:33<00:00, 3.96it/s] | 75/75 [00:35<00:00, 3.30it/s] | 75/75 [00:31<00:00, 3.96it/s] | 75/75 [00:34<00:00, 3.32it/s] |
平均生成速度
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 3.296it/s | 2.884it/s | 3.326it/s | 2.926it/s |
生成時間
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 33秒 | 35秒 | 31秒 | 34秒 |
まとめ
この結果からは4070Tiより5070Tiの方が生成速度が遅いことが読み取れる。またCPUがCore Ultra 7 265Fの時に僅かに高速化しているが、これはPCIe4から5への変化が効いている可能性がある。
またUltra 7 265F+4070Tiの組み合わせが最速を叩き出している点も見逃せない。つまりこれはStableDiffusionにおいてはi7 13700よりUltra 7 265Fが優位であることを示しており、FF14のベンチとは結果が逆転することを意味している。
りこベンチ
りこベンチとは個人的によく使う設定をベースにしたベンチだ。トキベンチの設定は個人的に使わず、実用性がないので今後はこちらを主にしていくと思う。
COMMANDLINE_ARGSは--xformersを使用。
ベンチマーク用のSD設定
| 設定 | 値 |
|---|---|
| Model | ntrMIXIllustriousXL_xiii.safetensors [1207404b17] |
| Clip skip | 2 |
| ENSD | 31337 |
| Propmpt | (illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), {{shot_hair}}, smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, {{purple eyes}}, gray {{jacket}}, white shirt, glasses, {{small breasts}}, |
| Negative Prompt | nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind |
| VAE | Automatic |
| Sampleing method | DPM++ 2M |
| Hires. fix | True |
| Upscaler | Latent |
| Hires steps | 0 |
| Denoising strength | 0.8 |
| Upscale by | 2 |
| Sampleing steps | 20 |
| Width | 768px |
| Height | 768px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | -1 |
生成ログ
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 20/20 [00:05<00:00, 3.43it/s] | 20/20 [00:06<00:00, 2.94it/s] | 20/20 [00:03<00:00, 5.92it/s] | 20/20 [00:04<00:00, 4.51it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.13it/s] | 20/20 [00:11<00:00, 1.73it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.49it/s] | 20/20 [00:06<00:00, 3.06it/s] | 20/20 [00:03<00:00, 6.26it/s] | 20/20 [00:04<00:00, 4.79it/s] |
| 20/20 [00:11<00:00, 1.67it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.72it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.53it/s] | 20/20 [00:06<00:00, 3.03it/s] | 20/20 [00:03<00:00, 6.28it/s] | 20/20 [00:04<00:00, 4.81it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.36it/s] | 20/20 [00:06<00:00, 3.06it/s] | 20/20 [00:03<00:00, 6.15it/s] | 20/20 [00:04<00:00, 4.78it/s] |
| 20/20 [00:12<00:00, 1.62it/s] | 20/20 [00:17<00:00, 1.13it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.53it/s] | 20/20 [00:06<00:00, 3.08it/s] | 20/20 [00:03<00:00, 6.13it/s] | 20/20 [00:04<00:00, 4.57it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 200/200 [01:49<00:00, 1.82it/s] | 200/200 [02:11<00:00, 1.53it/s] | 200/200 [01:33<00:00, 2.13it/s] | 200/200 [02:00<00:00, 1.65it/s] |
| 200/200 [01:49<00:00, 1.66it/s] | 200/200 [02:11<00:00, 1.12it/s] | 200/200 [01:33<00:00, 1.68it/s] | 200/200 [02:00<00:00, 1.11it/s] |
平均生成速度
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 2.567it/s | 2.085it/s | 3.932it/s | 2.911it/s |
生成時間
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 109秒 | 131秒 | 93秒 | 120秒 |
まとめ
結果としてはトキベンチと変わらず、Ultra 7 265F+4070Tiの組み合わせが最速でi7 13700+5070Tiの組み合わせが最も遅い。
総括
結果しては複雑で、個人的にはどの道を選ぶか未だに悩んでいる。
まず、今回新規導入したデバイスについての評価は以下の感じだ。
Core Ultra 7 265F
- FF14ベンチではi7 13700に劣る
- StableDiffusionの生成速度ではi7 13700を上回る
RTX 5070 Ti
- FF14ベンチでは4070 Tiを僅かに上回る
- StableDiffusionの生成速度では4070 Tiより1.1~1.3倍遅い
この結果は非常に悩ましい。FF14ベンチの結果からみるとゲーミング性能だけで言えばi7 13700+5070Tiが最適解だが、StableDiffusionの生成速度ではUltra 7 265F+4070Tiが最適解となった。
ただ私はもうFF14をしておらず、あまりゲームもしていないため、FF14ベンチの結果はある程度無視できる。そうなるとStableDiffusionだ。生成速度は重要な要素だ。とはいえ、4070Tiではメモリ不足でControlNetが使えないケースもあった。
また最近話題になっているFramePackのkisekaeichiではVRAM16GB必須という話もあり、今回は生成速度よりメモリを取る判断をしたいと思う。少なくとも旧環境である構成1-1と現環境である構成2-2を比べた時の差は一割程度であり、十分許容できる。
正直、私にはベンチマークのためにハードウェアを組み替える環境がないので、ある程度の情報でジャッジせざるを得ない。ちもろぐの人みたいに組み換え環境がある人はこの辺りがやりやすいと思うが、私の場合はPCケースからマザボを引っ張り出してそう取り返して、もう一度ケースに戻す手間がかかる。一連の作業には1時間ほど掛かり非常に手間だ。
今回はあまりにも結果が結果だったので、やむを得ず、新環境に組み替えてから、一度元に戻してベンチを取り直す検証を行ったが、組み換えの手間に加え、高価なCPUグリスが無くなり結構キツイ思いをしている。ちなみに今は新環境に完全に復帰している。