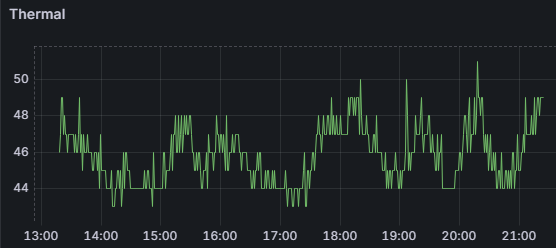
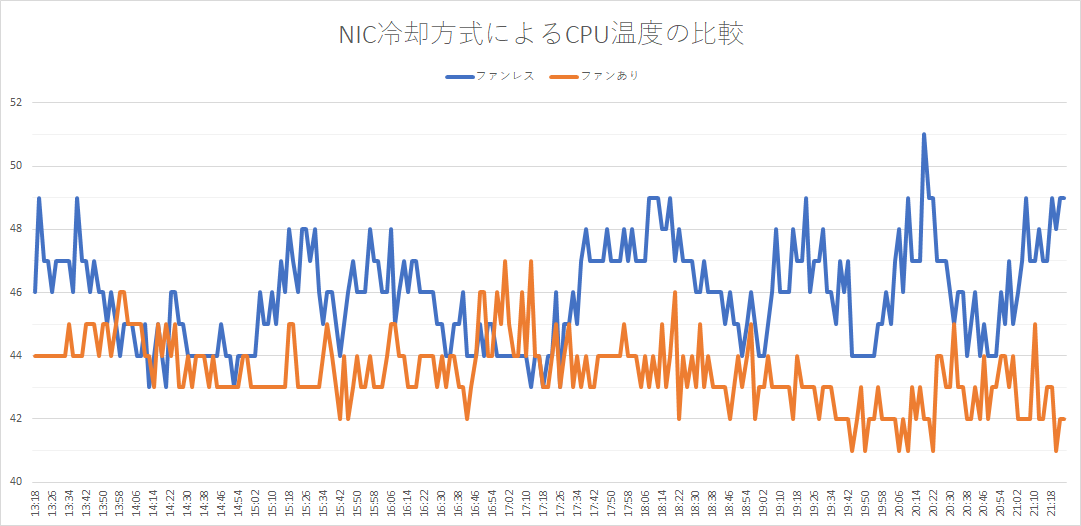
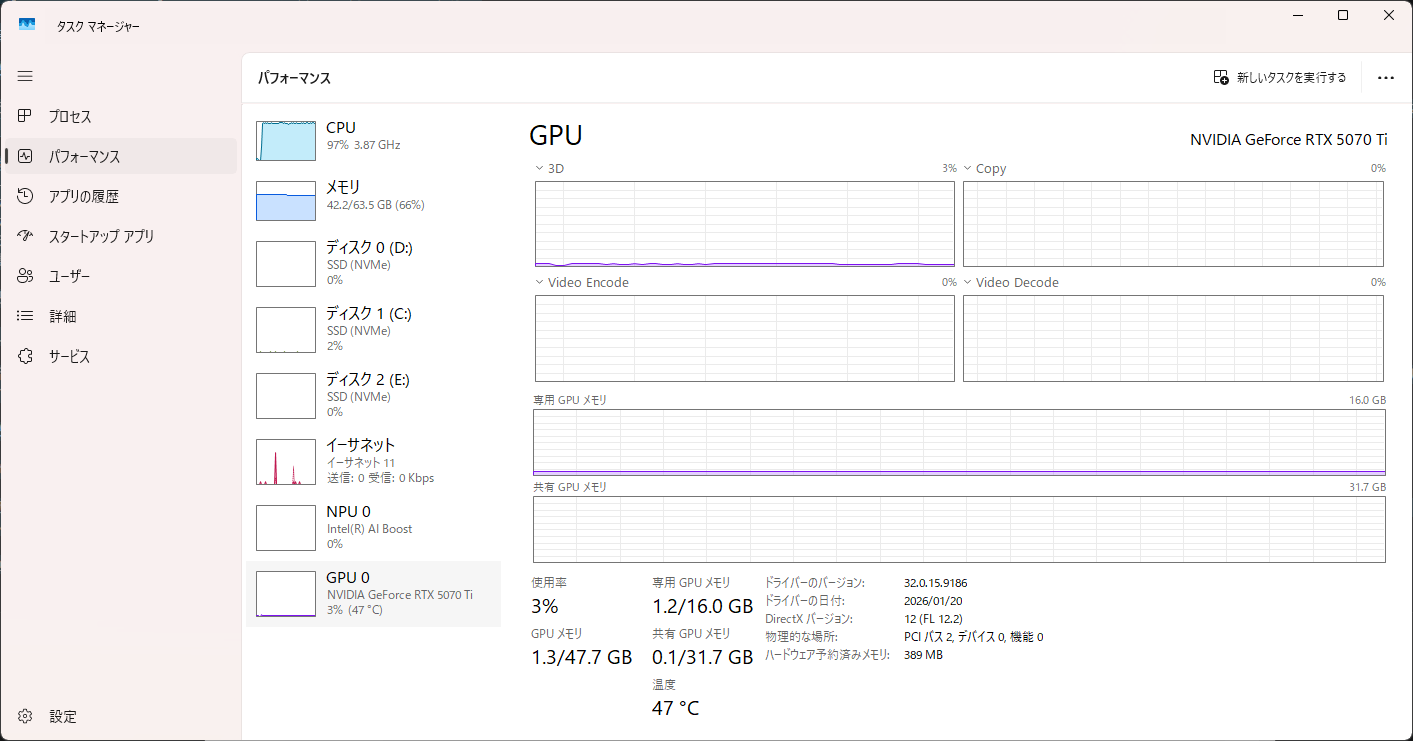
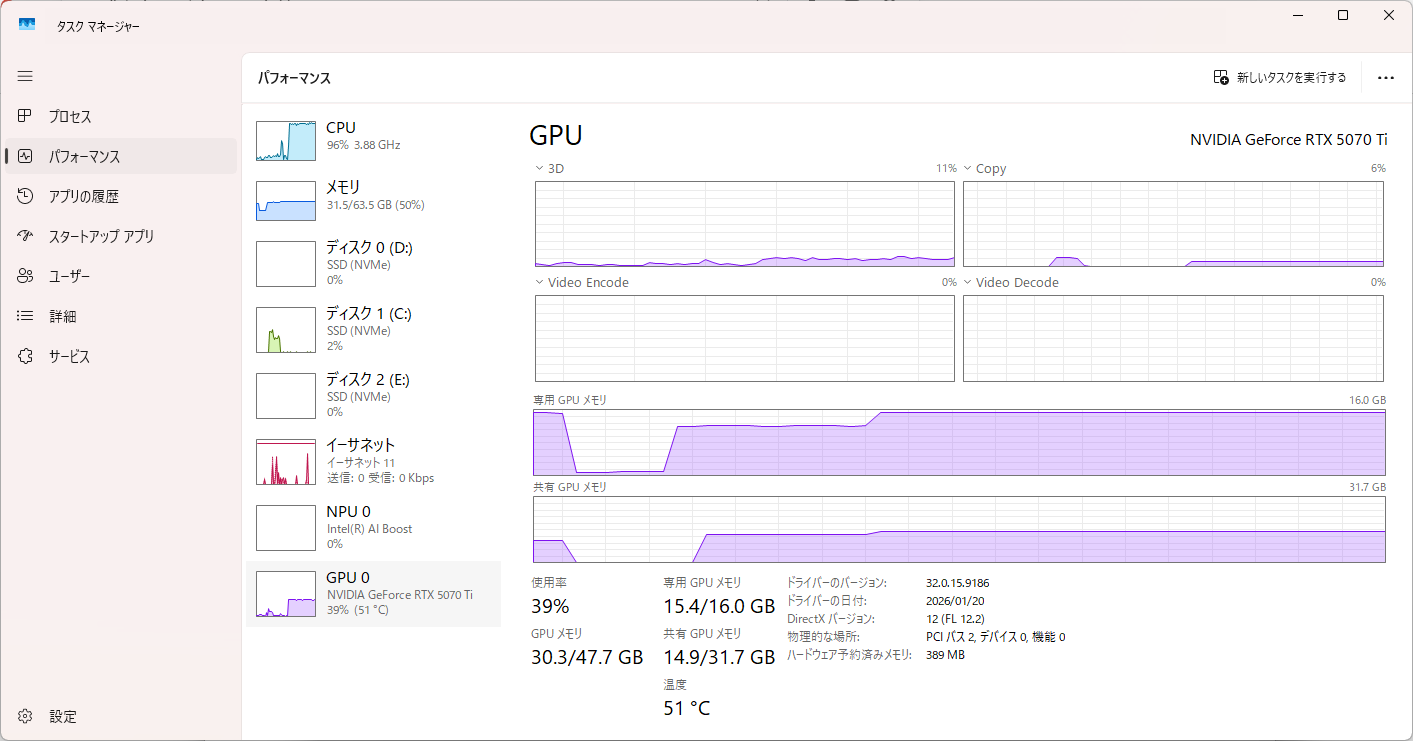
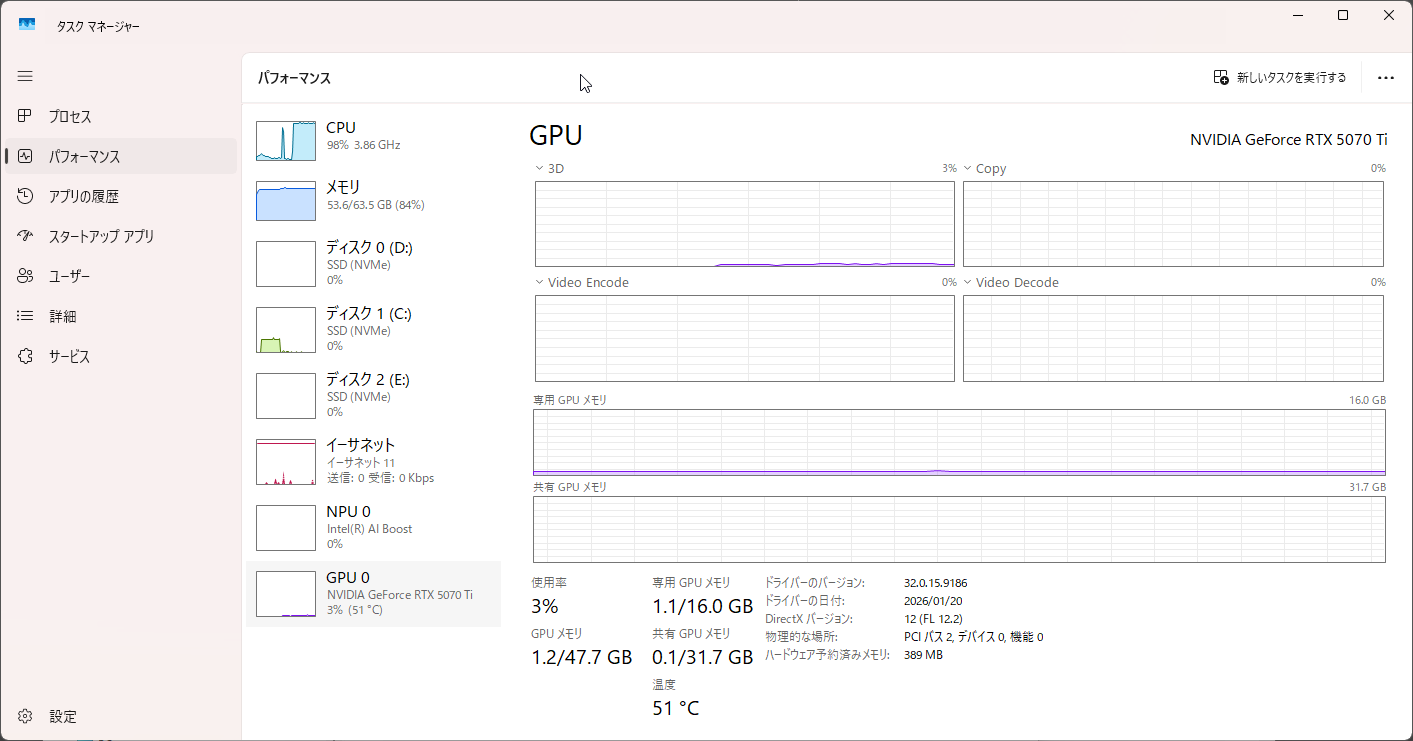
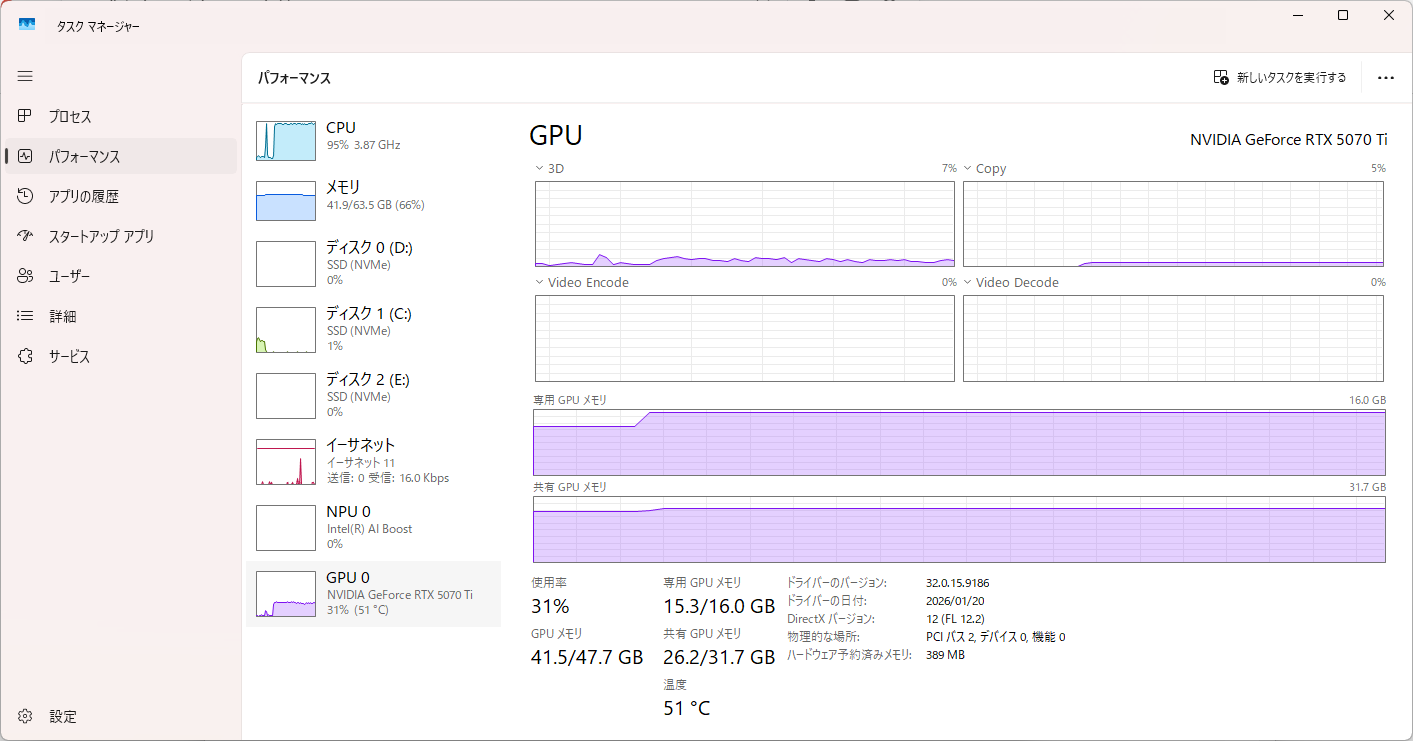
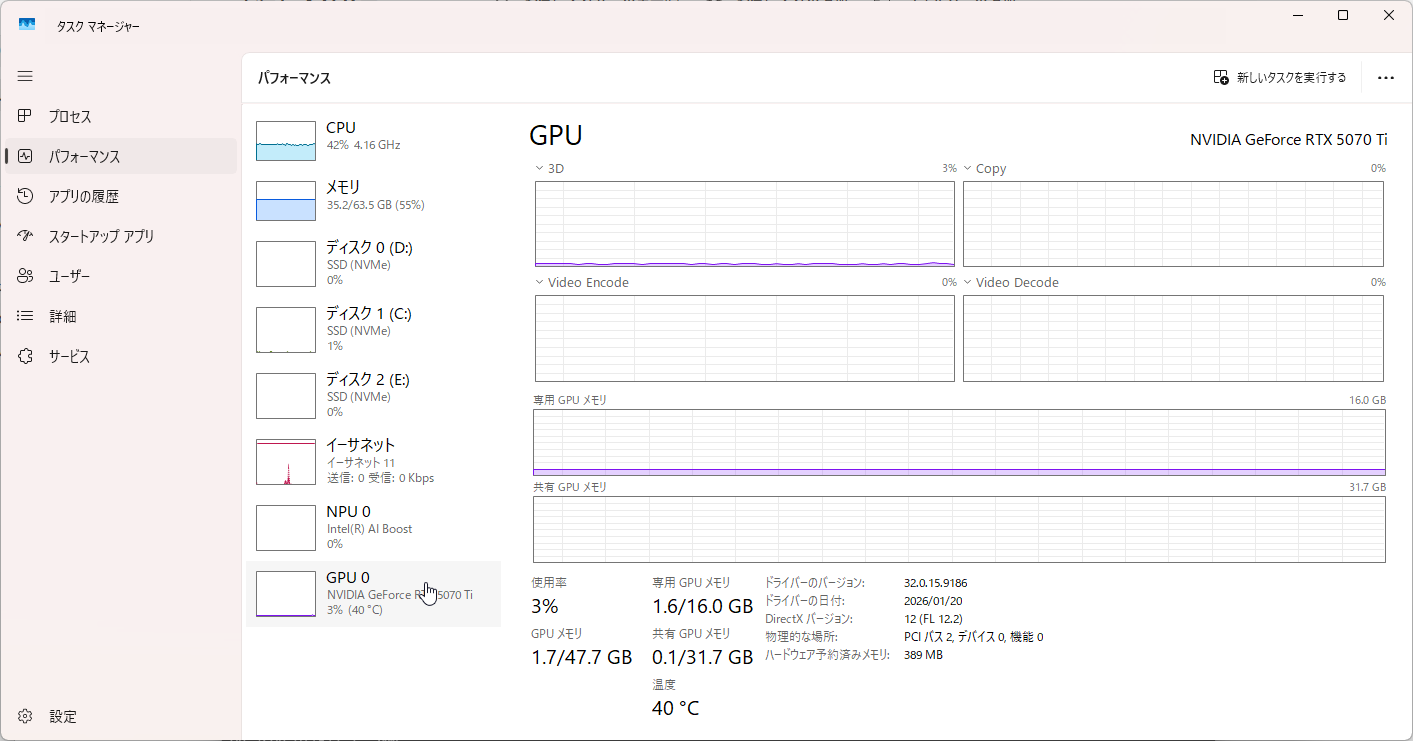
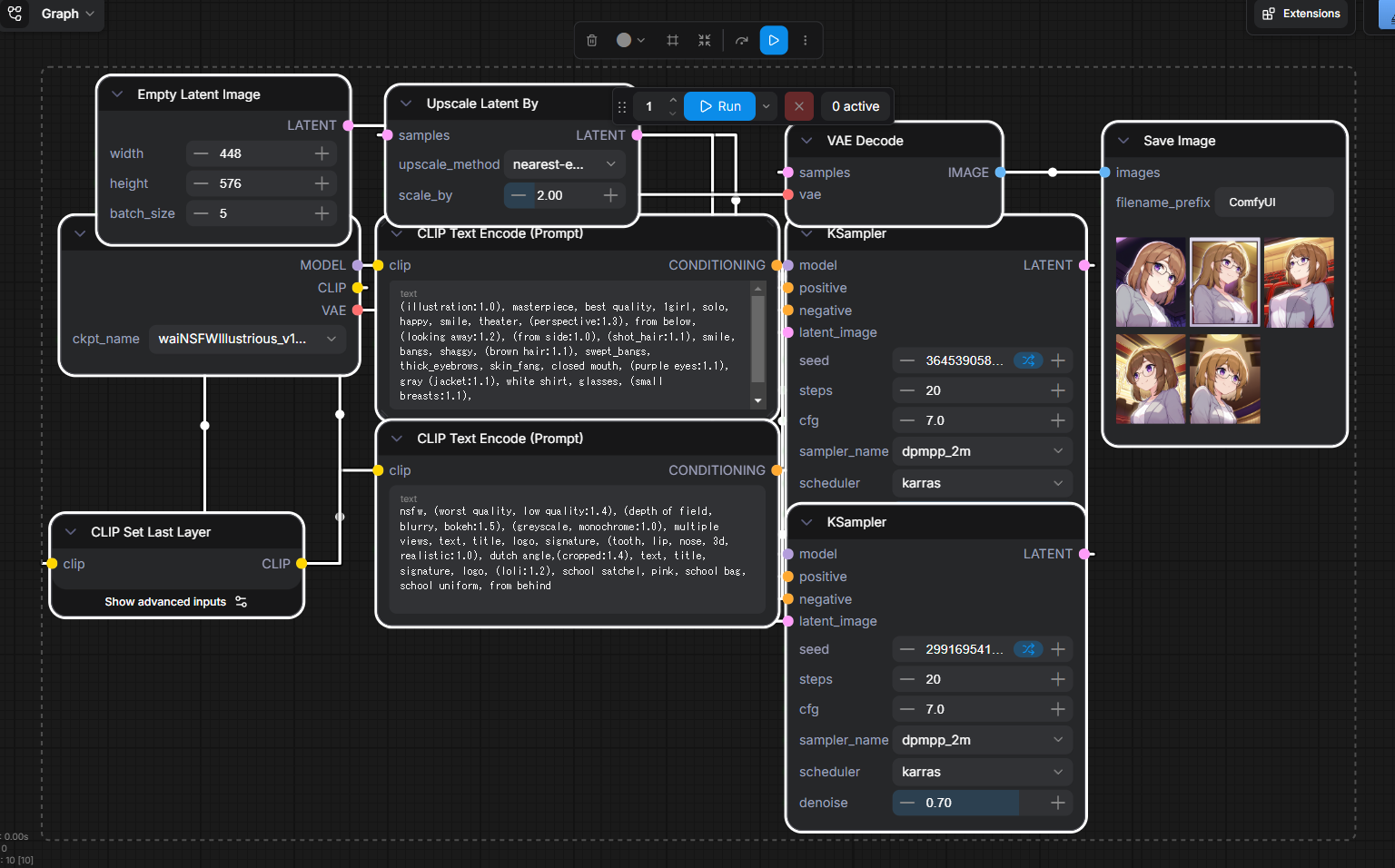
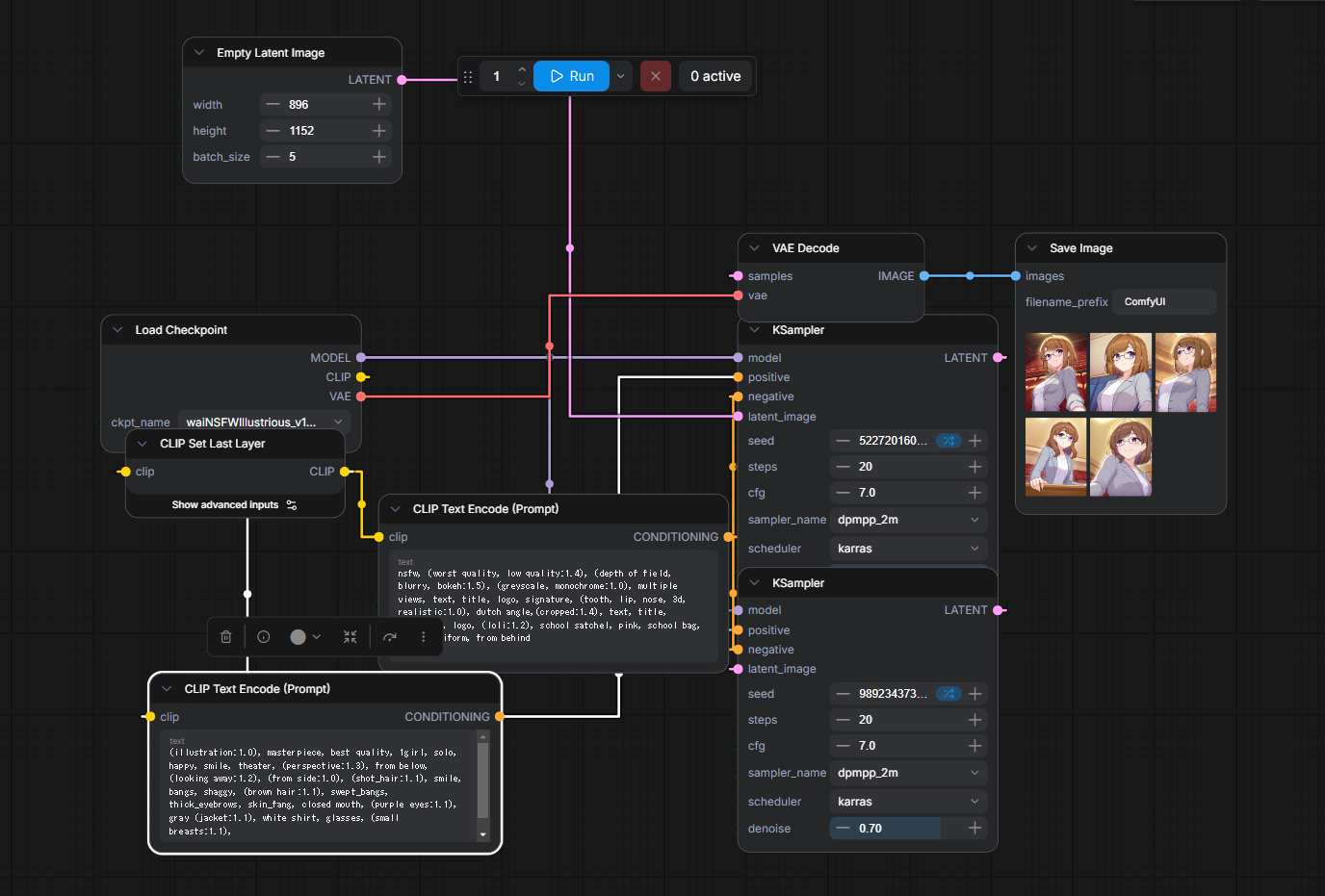
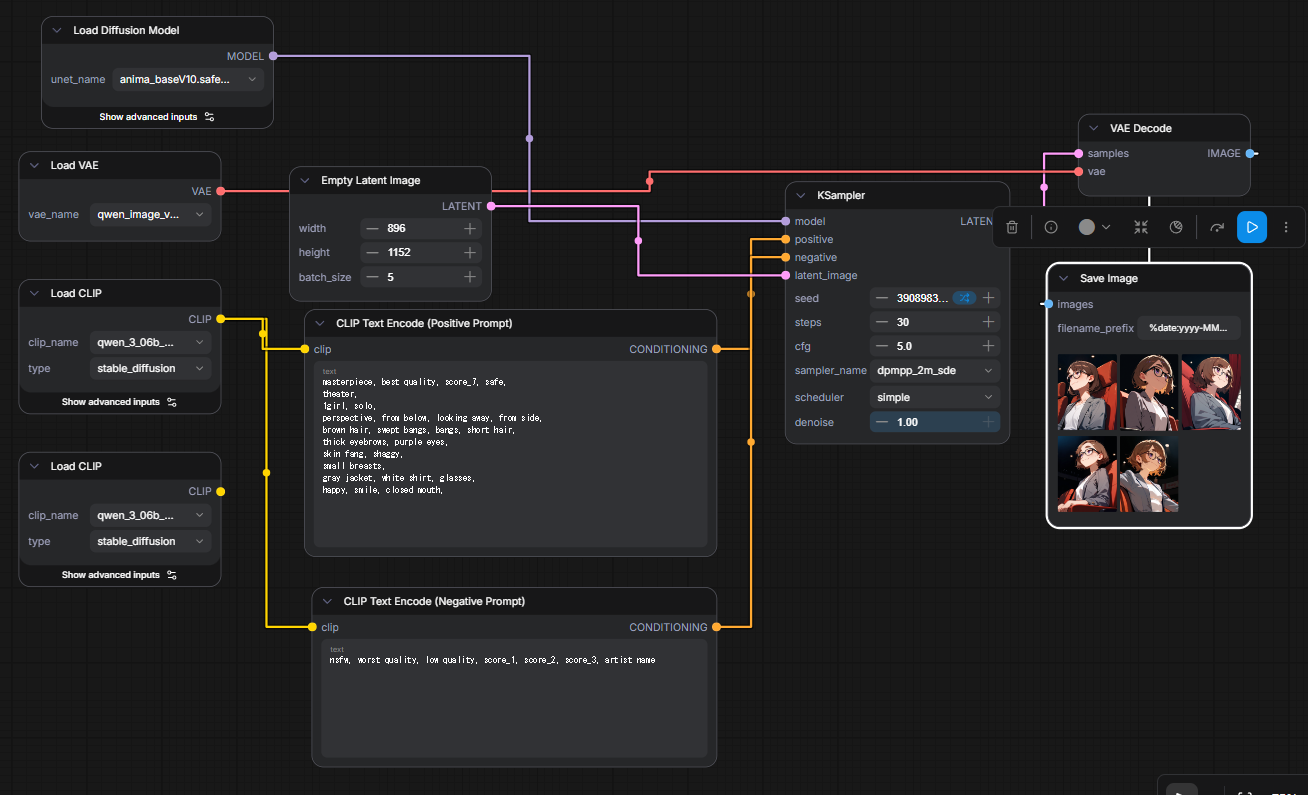
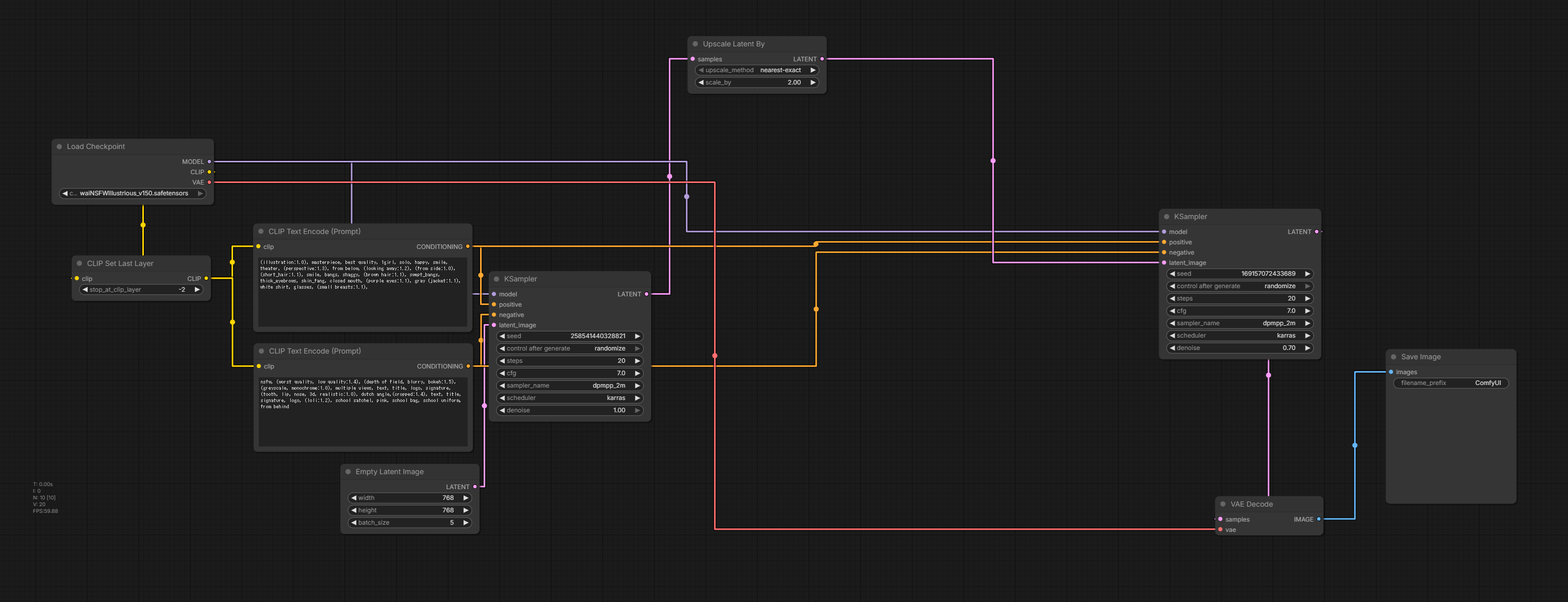
りこベンチ設定では64.76秒を記録し、AUTOMATIC1111からreForgeに乗り換えた時のスコアである81秒と比べると16.24秒も早くなっている。
{
"id": "6de0fdb5-59c2-4625-b494-4097461da37e",
"revision": 0,
"last_node_id": 17,
"last_link_id": 25,
"nodes": [
{
"id": 4,
"type": "CheckpointLoaderSimple",
"pos": [-290, 240],
"size": [320, 100],
"flags": {},
"order": 0,
"mode": 0,
"inputs": [
{
"localized_name": "ckpt_name",
"name": "ckpt_name",
"type": "COMBO",
"widget": { "name": "ckpt_name" },
"link": null
}
],
"outputs": [
{
"localized_name": "MODEL",
"name": "MODEL",
"type": "MODEL",
"slot_index": 0,
"links": [1, 18]
},
{
"localized_name": "CLIP",
"name": "CLIP",
"type": "CLIP",
"slot_index": 1,
"links": [11]
},
{
"localized_name": "VAE",
"name": "VAE",
"type": "VAE",
"slot_index": 2,
"links": [8]
}
],
"properties": { "Node name for S&R": "CheckpointLoaderSimple" },
"widgets_values": ["waiNSFWIllustrious_v150.safetensors"]
},
{
"id": 11,
"type": "CLIPSetLastLayer",
"pos": [-260, 380],
"size": [270, 60],
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 11
},
{
"localized_name": "stop_at_clip_layer",
"name": "stop_at_clip_layer",
"type": "INT",
"widget": { "name": "stop_at_clip_layer" },
"link": null
}
],
"outputs": [
{
"localized_name": "CLIP",
"name": "CLIP",
"type": "CLIP",
"links": [12, 13]
}
],
"properties": { "Node name for S&R": "CLIPSetLastLayer" },
"widgets_values": [-2]
},
{
"id": 3,
"type": "KSampler",
"pos": [490, 240],
"size": [320, 270],
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"localized_name": "model",
"name": "model",
"type": "MODEL",
"link": 1
},
{
"localized_name": "positive",
"name": "positive",
"type": "CONDITIONING",
"link": 15
},
{
"localized_name": "negative",
"name": "negative",
"type": "CONDITIONING",
"link": 14
},
{
"localized_name": "latent_image",
"name": "latent_image",
"type": "LATENT",
"link": 22
},
{
"localized_name": "seed",
"name": "seed",
"type": "INT",
"widget": { "name": "seed" },
"link": null
},
{
"localized_name": "steps",
"name": "steps",
"type": "INT",
"widget": { "name": "steps" },
"link": null
},
{
"localized_name": "cfg",
"name": "cfg",
"type": "FLOAT",
"widget": { "name": "cfg" },
"link": null
},
{
"localized_name": "sampler_name",
"name": "sampler_name",
"type": "COMBO",
"widget": { "name": "sampler_name" },
"link": null
},
{
"localized_name": "scheduler",
"name": "scheduler",
"type": "COMBO",
"widget": { "name": "scheduler" },
"link": null
},
{
"localized_name": "denoise",
"name": "denoise",
"type": "FLOAT",
"widget": { "name": "denoise" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"slot_index": 0,
"links": [24]
}
],
"properties": { "Node name for S&R": "KSampler" },
"widgets_values": [
735067360423163,
"randomize",
20,
7,
"dpmpp_2m",
"karras",
1
]
},
{
"id": 17,
"type": "LatentUpscaleBy",
"pos": [60, 100],
"size": [270, 90],
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"localized_name": "samples",
"name": "samples",
"type": "LATENT",
"link": 24
},
{
"localized_name": "upscale_method",
"name": "upscale_method",
"type": "COMBO",
"widget": { "name": "upscale_method" },
"link": null
},
{
"localized_name": "scale_by",
"name": "scale_by",
"type": "FLOAT",
"widget": { "name": "scale_by" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"links": [25]
}
],
"properties": { "Node name for S&R": "LatentUpscaleBy" },
"widgets_values": ["nearest-exact", 2]
},
{
"id": 15,
"type": "KSampler",
"pos": [490, 550],
"size": [320, 270],
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{
"localized_name": "model",
"name": "model",
"type": "MODEL",
"link": 18
},
{
"localized_name": "positive",
"name": "positive",
"type": "CONDITIONING",
"link": 20
},
{
"localized_name": "negative",
"name": "negative",
"type": "CONDITIONING",
"link": 21
},
{
"localized_name": "latent_image",
"name": "latent_image",
"type": "LATENT",
"link": 25
},
{
"localized_name": "seed",
"name": "seed",
"type": "INT",
"widget": { "name": "seed" },
"link": null
},
{
"localized_name": "steps",
"name": "steps",
"type": "INT",
"widget": { "name": "steps" },
"link": null
},
{
"localized_name": "cfg",
"name": "cfg",
"type": "FLOAT",
"widget": { "name": "cfg" },
"link": null
},
{
"localized_name": "sampler_name",
"name": "sampler_name",
"type": "COMBO",
"widget": { "name": "sampler_name" },
"link": null
},
{
"localized_name": "scheduler",
"name": "scheduler",
"type": "COMBO",
"widget": { "name": "scheduler" },
"link": null
},
{
"localized_name": "denoise",
"name": "denoise",
"type": "FLOAT",
"widget": { "name": "denoise" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"slot_index": 0,
"links": [19]
}
],
"properties": { "Node name for S&R": "KSampler" },
"widgets_values": [
968711531111656,
"randomize",
20,
7,
"dpmpp_2m",
"karras",
0.7
]
},
{
"id": 8,
"type": "VAEDecode",
"pos": [490, 140],
"size": [210, 50],
"flags": {},
"order": 8,
"mode": 0,
"inputs": [
{
"localized_name": "samples",
"name": "samples",
"type": "LATENT",
"link": 19
},
{ "localized_name": "vae", "name": "vae", "type": "VAE", "link": 8 }
],
"outputs": [
{
"localized_name": "IMAGE",
"name": "IMAGE",
"type": "IMAGE",
"slot_index": 0,
"links": [9]
}
],
"properties": { "Node name for S&R": "VAEDecode" },
"widgets_values": []
},
{
"id": 9,
"type": "SaveImage",
"pos": [830, 140],
"size": [260, 270],
"flags": {},
"order": 9,
"mode": 0,
"inputs": [
{
"localized_name": "images",
"name": "images",
"type": "IMAGE",
"link": 9
},
{
"localized_name": "filename_prefix",
"name": "filename_prefix",
"type": "STRING",
"widget": { "name": "filename_prefix" },
"link": null
}
],
"outputs": [],
"properties": {},
"widgets_values": ["ComfyUI"]
},
{
"id": 14,
"type": "CLIPTextEncode",
"pos": [50, 460],
"size": [430, 190],
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 13
},
{
"localized_name": "text",
"name": "text",
"type": "STRING",
"widget": { "name": "text" },
"link": null
}
],
"outputs": [
{
"localized_name": "CONDITIONING",
"name": "CONDITIONING",
"type": "CONDITIONING",
"slot_index": 0,
"links": [14, 21]
}
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind"
]
},
{
"id": 7,
"type": "CLIPTextEncode",
"pos": [50, 240],
"size": [430, 190],
"flags": {},
"order": 3,
"mode": 0,
"inputs": [
{
"localized_name": "clip",
"name": "clip",
"type": "CLIP",
"link": 12
},
{
"localized_name": "text",
"name": "text",
"type": "STRING",
"widget": { "name": "text" },
"link": null
}
],
"outputs": [
{
"localized_name": "CONDITIONING",
"name": "CONDITIONING",
"type": "CONDITIONING",
"slot_index": 0,
"links": [15, 20]
}
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"(illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), (shot_hair:1.1), smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, (purple eyes:1.1), gray (jacket:1.1), white shirt, glasses, (small breasts:1.1),\n"
]
},
{
"id": 16,
"type": "EmptyLatentImage",
"pos": [-250, 90],
"size": [270, 110],
"flags": {},
"order": 1,
"mode": 0,
"inputs": [
{
"localized_name": "width",
"name": "width",
"type": "INT",
"widget": { "name": "width" },
"link": null
},
{
"localized_name": "height",
"name": "height",
"type": "INT",
"widget": { "name": "height" },
"link": null
},
{
"localized_name": "batch_size",
"name": "batch_size",
"type": "INT",
"widget": { "name": "batch_size" },
"link": null
}
],
"outputs": [
{
"localized_name": "LATENT",
"name": "LATENT",
"type": "LATENT",
"links": [22]
}
],
"properties": { "Node name for S&R": "EmptyLatentImage" },
"widgets_values": [768, 768, 1]
}
],
"links": [
[1, 4, 0, 3, 0, "MODEL"],
[8, 4, 2, 8, 1, "VAE"],
[9, 8, 0, 9, 0, "IMAGE"],
[11, 4, 1, 11, 0, "CLIP"],
[12, 11, 0, 7, 0, "CLIP"],
[13, 11, 0, 14, 0, "CLIP"],
[14, 14, 0, 3, 2, "CONDITIONING"],
[15, 7, 0, 3, 1, "CONDITIONING"],
[18, 4, 0, 15, 0, "MODEL"],
[19, 15, 0, 8, 0, "LATENT"],
[20, 7, 0, 15, 1, "CONDITIONING"],
[21, 14, 0, 15, 2, "CONDITIONING"],
[22, 16, 0, 3, 3, "LATENT"],
[24, 3, 0, 17, 0, "LATENT"],
[25, 17, 0, 15, 3, "LATENT"]
],
"groups": [],
"config": {},
"extra": {
"ds": {
"scale": 1.1284491351375,
"offset": [757.6336710071444, 145.5718113186996]
}
},
"version": 0.4
}




reForgeと変わらない、ちゃんとした品質のものを出すことができた。