検索条件
全8件
(2/2ページ)
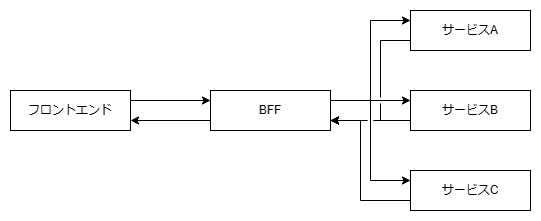
この記事では下図のシステム構成を前提に話を進めるものとする。この時、BFFの部分のアーキテクチャをREST APIにするか、GraphQLにするかというのが今回の話。
/api/v1/userからユーザー名だけを取得したい場合に、ユーザーIDや年齢といった余計なデータが付随してしまうことがあったり、このエンドポイントからそのユーザーのログイン履歴を取得することができなければそれはアンダーフェッチになる今回は何故単体テスト書くのかというのを個人的な見地から書いていく。TypeScriptとJestで記述するが、他の言語でも応用は可能だと思う。
関数やクラスのメソッドを単体としてみた場合の振る舞いを確かめるものである。以下はその一例だ。
hoge.ts
export const joinString = (string1: string, string2: string) => {
return `${string1}${string2}`;
};
hoge.spec.ts
import { joinString } from '.';
describe('joinString', () => {
it('引数として渡した文字列が正しく結合されること', () => {
const actual = joinString('123', 'abcd');
expect(actual).toBe('123abcd');
});
it('第一引数が空文字の時に第二引数のみが出力されること(空文字が結合されること)', () => {
const actual = joinString('', 'edfg');
expect(actual).toBe('edfg');
});
it('第二引数が空文字の時に第一引数のみが出力されること(空文字が結合されること)', () => {
const actual = joinString('zxcvb', '');
expect(actual).toBe('zxcvb');
});
});
結合テストやe2eテストではなく、何故単体テストをするか、これは実務面では結構出てくる疑問だと思うので、以下で説明する。
まず単体テストは一般的に結合テストやe2eテストに比べ、実行速度が速く、コードを修正したときに素早く回し、デグレードしていないかの確認に使うときに有益である。これは単体テストは実際にサーバーを起動したり、ヘッドレスブラウザでUI操作を行うなどしないためだ。他にも同じ処理を何度も見るのでテストのオーバーヘッドが膨らみ、実行時間が落ちるといったこともある。単体テストであれば簡単なロジックの実行しかしないし、結合部分はすべてモックにするため高速に実行できる利点がある。
次に結合テストやe2eテストは共通処理を一個直すと、それを使っている処理のテストをすべて直す必要があり、保守性がよくない。単体テストは基本的に直した箇所のテストコードを直すだけなので保守性が高い。
最後に単体テストでは基本的に関数単体を見るためテストコードが肥大化しづらく、見通しが良いので何をテストしているのかが結合テストやe2eテストと比べて分かりやすい。またスコープが関数単体であるため、カバレッジが取りやすく、いわゆるC0, C1, C2と言われる、命令網羅、分岐網羅、条件網羅の三点を網羅しやすい。結合やe2eでは共通処理の全機能を使うとは限らないため、この網羅がしづらい。
これについてはSOLID原則を使った設計が一番無難だと考える。画面であれば更にMVCモデルを使うのがよい。
基本的に画面の実装は密結合になりやすい。密結合になっているとテストが書きづらいのでModelとViewとControllerに分けてテストをしやすくするのが目的だ。きちんと分けた場合、Viewは文字列が出ているか、表示項目が出ているかみたいなテストだけでよく、Modelはビジネスロジックのテストをするだけでいいし、Controllerは互いの橋渡しができているかを見ればいい。このため、テストコードをシンプルにできるのが利点だ。
欠点は画面の項目数が多い場合、インターフェースがそれに応じて肥大化するため、画面に仕様変更が入ったときに保守性が悪くなることだ。ここは品質とのトレードオフで許容するしかないと思う。
一つの関数で完結している関数はそれでいいとして、他の関数を呼んでいる関数をどのように単体テストするかという部分。よくあるパターンとしては他の関数ごとテストしてしまうことだが、これでは結合観点になってしまう。
この部分については呼び出す関数をモックすることで単体観点で確認することが出来る。呼び出す先の関数が単体テストで網羅されていれば、その関数の振る舞いは正しいはずなので、呼び出す側としては呼び出す関数をモックして、関数が正常終了したケースと、異常終了したケースでカバレッジが取れるようにテストすればよい。これは例えば次のようなテストを書くことが出来る。
index.ts
import { isEmpty } from './lib/string-util';
export const validate = (hoge: string) => {
if (isEmpty(hoge)) {
throw new Error('空です。');
} else {
// 何もしない
}
};
index.spec.ts
import { validate } from '.';
import * as empty from './lib/string-util';
jest.mock('./lib/string-util');
describe('validate', () => {
it('hogeが空文字の場合、例外がスローされること', () => {
jest.spyOn(empty, 'isEmpty').mockReturnValueOnce(true);
expect(() => {
validate('aaaa');
}).toThrow(new Error('空です。'));
});
it('hogeが空文字でない場合、例外がスローされないこと', () => {
jest.spyOn(empty, 'isEmpty').mockReturnValueOnce(false);
expect(() => {
validate('aaaa');
}).not.toThrow(new Error('空です。'));
});
});
このテストではisEmpty()の実際の振る舞いを一切見ていないため、validate()の単体テストということが出来る。但しisEmpty()のテストが漏れていると機能しないため、これをきちんと機能させる場合、呼び出し先の関数の単体テストも必須だ。
単体テストは単体を見るものなので、当たり前だが単体しか見ることが出来ない。結合観点やe2e観点はなく、単体テストが通っているからデグレやバグがないという通りはない。
基本的に単体テストは動作確認が人間がやり、カバレッジが網羅できており、テストしている内容も正しければ以後のテストを工数を削るためのものである。過去に行った動作確認でテストが通っていて、今も通っているのだから恐らく動作しているだろうということを見るためのもので、単体テストが通っているからデグレがないとか、そんなことの保証はない。
では単体テストを何のためにするかだが、複数の確認工程鵜を作ることでバグを作りこむことを防ぐ役割が一つだ。例えば単体テスト+結合テスト+e2eテスト+人による動作確認やテストと言ったように多層の防御があれば、不具合が起きる可能性を減らすことが出来る。もう一つはコードの仕様となることだ。実装を見て意図が読み取れないコードであってもテストコードがあればわかることもあるだろう。つまるところ実装品質を保つための防御機構の一つとみなすことが出来る。
テストコードを書いても、そのテストコードが有効に動いているかどうかの観点が抜けていると有意なものとならないので、テストコードの動作確認は必要だ。偶にテストコードは動いているが、偶々テストがパスしてそれっぽく動いているだけみたいなこともある。TDDでやってもこれは起きえる。
期待値や結果値をいじって落ちるかどうかや、パラメーターなどの条件をいじって落ちるかは見たほうが良い。何をしてもパスする場合、そのテストコードは無意味である。
文字列の入力パターンを見るテストや組み合わせテストではカバレッジを網羅していてもテストケースが漏れていることがある。例えば次のテストコードはカバレッジ100%だがtrueになる場合のテストが不足している。もしも関数の中身が必ずfalseを返す実装になっている場合に、これを確かめることが出来ない。実装を知っているからこれでいいとみなすのではなく、基本的には実装を知らない体で書いた方が良い。とはいえ、限度はあるので現実的に起きうる条件でテストするのが無難だろう。この辺りはSIerで堅めの開発をしていると身に付きやすいのだが、個人の感性に左右される部分であり難しいところでもあると思う。
index.ts
export const isEmpty = (str: string) => {
return str === '';
};
index.spec.ts
import { isEmpty } from '.';
describe('isEmpty', () => {
it('空文字でない時にfalseが返る事', () => {
const actual = isEmpty('aa');
expect(actual).toBe(false);
});
});
例えば以下の実装であれば引数は文字列型なので文字列以外が来ることは考えなくていい。
export const isEmpty = (str: string) => {
return str === '';
};
しかし以下の実装では何が来るかわからない。テストとしてはありとあらゆる値が来ることを想定して書かないとリファクタリングに耐えられないだろう。そんなテストは書きたくない。そもそも実装からどれほどテストを書けばいいのか予測し辛いのもある。
export const isEmpty = (str: any) => {
return str === '';
};
もしどうしても何が来るかわからない場合はunknownにしておくとよいだろう。何故なら以下のコードはエラーになるからだ。
export const isEmpty = (str: unknown) => {
return str === '';
};
また全体的にきちんと型で縛っておくと、改修などで型が変わった時に実装コードやテストで型不整合が発生する機会が増え、型チェックでエラーが発生するため、未然に不具合を防ぎやすくなる筈だ。
ここ数年見かける有効期限付きのURLの名前には署名付きURLとか、Private Cache Distributionパターンの様なものがあるらしい。
これはFantiaみたいな課金サービスを利用している人にはもはや当たり前だと思うが、ページを表示してから一定時間たつと画像が表示できなくなるが、一定時間内であればそのURLは誰でも見れるみたいなやつだ。要するにURLに短めの有効期限を付けて認証されたユーザーにしか見えなくする仕組みのことだ。