- 投稿日:
例外設計についての個人的に思っていることを書き出してみる。整理できていないがいったん現状。TypeScriptのケースを意識して考えているが、根幹は例外スローのある言語ではどれも共通だと考えている。
例外とは何か?
本記事で扱う例外とはthrow new Error("ほげほげ");のように、いわゆるスローされ、try-catchされるものを指して扱う。
例外を多用しない
例外は多用しないことが望ましく、原則として処理が続行不能になる場合を除き、使わないほうが良いと考えている。これはスローされた例外は可視化されづらく、適切にハンドリングされないケースがよくあるからだ。
例外は構造化されたプログラムを破壊する
構造されたプログラムとは順次・反復・分岐の基本構造を階層的に組み合わせたものであり、いわゆる上から下に読めばわかるもの、構造化プログラミングによって作られるものだ。上から下に流れるため非常にわかりやすい。
これに対して存在するのがgotoを用いたプログラムだ。gotoを使うとコードの色んな場所に前後しながらジャンプすることが可能で、可読性を損ねてしまう。
そして例外は基本的にgotoのような存在である。例外が起きると例外オブジェクトが投げられ、これはどこに行きつくか予想することが難しい。行きつく先がなければ最悪プログラムがクラッシュする恐れすらある。
例外は処理コストが重い
恐らく大抵の言語において例外をcatchする行為はコストが重い。これはJavaでは特に有名な話だと思うが、Java以外でもそうだと思う。例えばNode.jsでtry-catchで例外を処理するプログラムと、if-elseで処理するプログラムを書き、その実行速度を比較するとif-elseの方が早い。
以下はエラーハンドリングをifで行うプログラムと、try-catchで行うプログラムを作り、100万回走行させたときの処理時間だ。catchに入るケースでは処理速度が低下することが分かる。例外が投げられず、tryの中に納まる限りは低下しない。
| 処理 | 処理時間(ms) |
|---|---|
| If正常系 | 4,453 |
| If異常系 | 4,204 |
| try-catch正常系 | 4,341 |
| try-catch異常系 | 7,883 |
これは例外が投げられる場合、最寄りのcatchポイントを探索するのに時間がかかるからではないかと考えている。
Node.js向け検証コード
前述の処理時間を出すのに使ったプログラム
// ==== 実行用共通部品
const execIf = (input) => {
if (input === 1) {
return true;
} else {
return false;
}
};
const execThrow = (input) => {
if (input === 1) {
return true;
} else {
throw new Error('ERR');
}
};
// ==== コールバック処理計測用関数
const getExecFuncElapsed = (cb) => {
const startAt = +new Date();
for (let i = 0; i < 1_000_000; i++) {
cb();
}
return +new Date() - startAt;
};
// ==== If/try-catch検証用、コールバック処理群
const execIfOk = () => {
const ret = execIf(1);
if (ret) {
console.log('OK=');
}
};
const execIfNg = () => {
const ret = execIf(0);
if (ret === false) {
console.log('ERR');
}
};
const execThrowOk = () => {
try {
execThrow(1);
console.log('OK=');
} catch (e) {
console.log('ERR');
}
};
const execThrowNg = () => {
try {
execThrow(0);
console.log('OK=');
} catch (e) {
console.log('ERR');
}
};
// ==== 計測処理
const elapsedIfOk = getExecFuncElapsed(execIfOk);
const elapsedIfNg = getExecFuncElapsed(execIfNg);
const elapsedThrowOk = getExecFuncElapsed(execThrowOk);
const elapsedThrowNg = getExecFuncElapsed(execThrowNg);
// ==== 結果出力
console.table({ elapsedIfOk, elapsedIfNg, elapsedThrowOk, elapsedThrowNg });
いつ例外を使うか?
基本的には大域脱出がしたいケースのみで使うべきだろう。最悪ハンドリングされずとも、基底階層でcatchされれば、それでよいケースで使うのが最も無難だと考える。
大域脱出とは要するにgotoだ。多重ネストや深い高階関数から浅い階層に一気にすり抜けるときに有効だろう。逆に一階層とか、抜ける階層が浅いレベルでは使わないほうが良い。
例えば処理が続行不能になったケースでは例外をスローし、基底階層でcatchし、エラーログを吐く、クライアントに対してエラーメッセージを返すなどの処理があればよいと考える。
但し例外を使うときは極力カスタム例外を使ったほうがよいと考える。
フレームワークやライブラリの例外をどう扱うか?
例えばバリデーションエラーやHttpClient系の4xx, 5xx系の例外スローはラッパーを作り、例外をエラーオブジェクトに変換するのも一つだと考える。
HTTP GETを行うクライアント関数であれば以下のようなラッパーを作り、正常時は正常レスポンスを返し、異常時でかつ想定内であればエラーオブジェクトを返す、そして想定外の例外であればリスローする、といった処理をすることができる。
const httpGet = (url) => {
try {
return fetch(url);
} catch (e) {
if (e instanceof AbortError) {
return createHttpErrorObj(e);
} else {
throw e;
}
}
}
こうすることで呼び出し元は正常時であればHTTPリクエストをそのままステータスコードに応じて処理し、Abortされた場合はリトライ、完全に予期せぬ内容であれば例外を基底階層まで飛ばして処理を中断するといったこともできる。
リトライに規定回数失敗した場合は、この関数の呼び元でnew OutOfTimesHttpRetryError()みたいな例外をスローするとよいだろう。
カスタム例外を使う
カスタム例外とは例外クラスを継承した例外クラスだ。
例えばC#ではExceptionのほかに、それを継承したSystemExceptionや、IndexOutOfRangeExceptionなど、様々なカスタム例外が存在する。
LaravelにもAuthorizationExceptionをはじめとし、多様なExceptionが存在する。
これらに限らず、大抵の言語やフレームワークには相応のカスタム例外が用意されているのが一般的で、業務システムやC2のプロダクトでも、例外をスローするケースではカスタム例外を作ることが望ましいと考える。
カスタム例外があると例外種別ごとにフィルタリングすることが可能になり、柔軟にハンドリングしやすく、ロギングの際にも例外種別を記録することで、後々の障害調査でも便利になるため有用だ。
例外を握りつぶさない
例外は時として握りつぶされることがある。そういう必要があるケースも少なからずあるだろう。しかし基本的に例外は握りつぶさないほうがよい。
例外は望ましくない現象が起きているはずで、本質的にハンドリングする必要がある。単に握りつぶしているだけでコメントやテストも書かれていなければ、もし例外が起きたとき、処理が正常に進むのかどうかコードから読み取ることが困難だ。
仮にテストがあったとしてもコードを読むときのコストが増えるので、基本的に握りつぶさないほうがよいだろう。
スローする場合は、例外クラスを用いる
JavaScript系では以下のようなエラーオブジェクトを作るケースもあると思うが、スローする場合は使わないほうが良い。
{
__type: 'HogeError',
message: 'fufagfuga',
payload: someObject
}
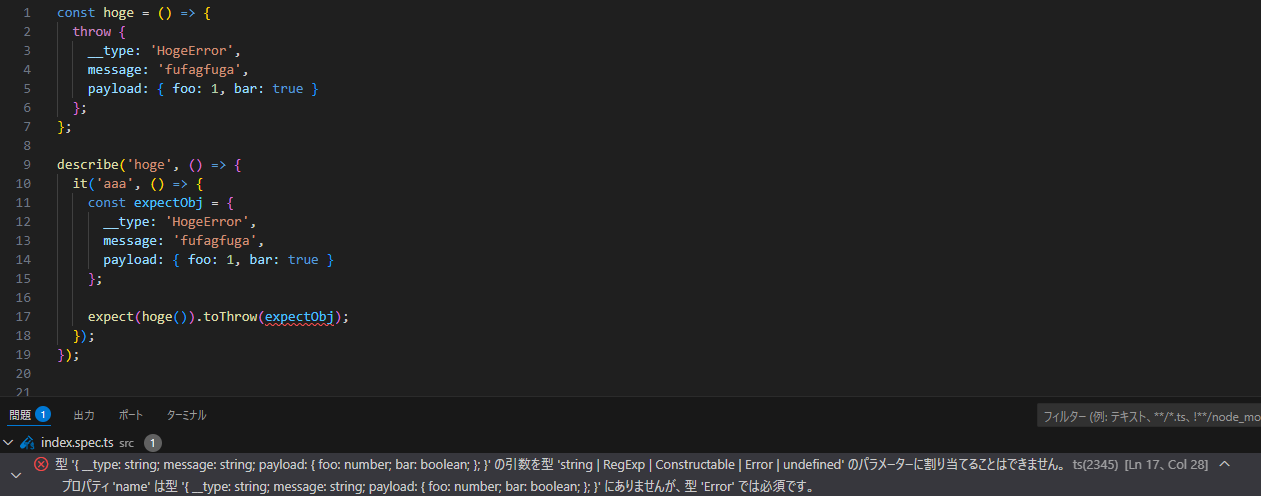
スローする場合はErrorクラスを継承したカスタムエラーをスローすべきだ。これはカスタムエラーにはスタックトレースなど、障害調査をするときなどに例外として標準的な情報が格納されているほか、instanceofでフィルタしやすい、クラスは型情報を持つのでリファクタが容易、error.__type === 'HogeError'は言語機能の再実装に近く標準的ではないからだ。テストフレームワークでも例外をキャッチするためのアサーションではErrorクラスの継承が必須となっているケースがあるため、TypeScriptでは型検査が上手く通らないケースがある。
- 投稿日:
今回は実際の開発現場で遭遇しそうなコードパターンを2つ挙げ、それらを主に可読性向上と保守コスト削減の視点から、どのように改善できるかを具体的に書いてゆく。
サンプルコードはTypeScript + GraphQLを使ったAPサーバーを想定して書いている。
命名とデータ構造の最適化
この項目ではエラーメッセージを返すサーバー側の処理について記述する。
元コード
resolvers/customer-info/helpers/invalid-reason.ts
type ReferencePageLinkMapKey = 'userFormIssue' | 'duplicateUserName' | 'someErrorMessage';
// exportされているがgetInvalidInfo(key, boolean)でreferencePageLinkMap.get(key)が返ってくることを確認するテストに使われているだけ
export const referencePageLinkMap: Map<ReferencePageLinkMapKey, string> = new Map([
['userFormIssue', 'https://help.example.com/23843ddvwa'],
['duplicateUserName', 'https://help.example.com/xdxdk2t5'],
['someErrorMessage', 'https://help.example.com/pp33s'],
...
]);
const invalidReason = {
inputIssue: {
message: '入力項目にエラーがあります。...',
links: [
{
label: '【登録時のヘルプページをご確認ください】',
url: referencePageLinkMap.get('userFormIssue') ?? '',
},
],
},
...
};
export const getInvalidInfo = ({
errorReasonType,
isModeA,
}: {
errorReasonType: ErrorReasonType;
isModeA: boolean;
}): Omit<SomeFormInvalidInfo, 'invalidReason'> => {
switch (errorReasonType) {
case 'INVALID_INPUT':
case 'SOME_INPUT_ERROR':
return invalidReason.inputIssue;
...
};
}
このコードの問題点
- 定義する必要性が希薄な型情報があり、改修コストが高い
- 変数や関数名、キー名などから相関する機能の関連性を読み取りづらい
- 定義されたスコープを超えて利用されているもので命名から機能の読み取りが難しいものがある
- リテラルがべた書きされており将来のリファクタリングに支障がある
- 不必要にMapが使用されており、実装が冗長になっている
- 静的な値の取得にNull合体演算子が使用されており、潜在不具合となりやすい
- 型情報がべた書きされすぎており、見通しが悪い
- 複数のフラグ値の正規化を利用側で行っており、複雑になっている
改善後コード
リソースファイルと実装が一緒くたであると読みづらいためファイルを分割する。パスも書いているがパスについては深く考慮できていない。
resources/messages/CustomerError.ts
export const ERROR_MESSAGES = {
formValidationError: {
message: '入力項目にエラーがあります。...',
helpLinks: [
{
label: '【登録時のヘルプページをご確認ください】',
url: 'https://help.example.com/23843ddvwa',
}
],
},
...
} as const;
まずtype ReferencePageLinkMapKeyは無駄に型の管理コストが増えるだけなので削除する。意味がないとは言わないが、型の追加削除によって発生するデグレードは普通は型検査でわかるためなくてよいだろう。
次にreferencePageLinkMapでは意味がわからないのでERROR_MESSAGESにリネームする。中身のキーもinputIssueでは分かりづらいのでformValidationErrorとし、フォームのバリデーションエラーであることが分かるようにする。linksについても何のリンクなのかわからないためヘルプのリンクであることを明示できるようにリネームする。
helpLinks.urlについては、共通のURLを参照する概念は普通ないか、あったとしても別に切り出して管理するのはコストなので直に書いてよいと考える。元のコードでもテストコード以外には使われていない。テストコードには実値を書かないと回帰テストとして機能しないため、この方式のほうがより良いと考える。
例えば以下のようなテストコードは回帰テストの観点では意味が薄い。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe(invalidReason.get('inputIssue'));
});
これは以下のように書くことでページのURLが変更されたときにテストが失敗するため、より価値のあるものになる。但しこれはexpect(invalidInfo).toStrictEquals({ ... })の形で一括判定したほうが、テストコードの可読性の観点からより良いだろう。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe('https://help.example.com/23843ddvwa');
});
ERROR_MESSAGESをリソース変数としてみなせば、これはべた書きというより定数定義とみなせるため、基本的には問題ないと考える。勿論これは同じURLを持つものが大量にあるなど、ケースによっては考慮の余地はあるだろう。
またMapをやめ、敢えて直値を書くことで万一存在しなかった場合に、元にあった以下の空文字が返ってきて機能しなくなる問題も解決している。そもそも通る余地がないロジックなので存在しなくてよい。
url: referencePageLinkMap.get('userFormIssue') ?? ''
またERROR_MESSAGESにas constを付与することで、意図しない破壊が起きる可能性を減らすことができる。
handlers/error/GetCustomerInfoError.ts
export const getCustomerInfoError = (errorType: CustomerErrorType) => {
switch (errorType) {
case CustomerErrorType.INVALID_INPUT:
case CustomerErrorType.SOME_INPUT_ERROR:
return ERROR_MESSAGES.formValidationError;
...
};
}
まずgetInvalidInfo()をgetCustomerInfoError()にリネームすることで意味を分かりやすくしている。次に複雑な型情報を除去してシンプル(= (errorType: CustomerErrorType) =>)にする。errorTypeはerrorReasonTypeとisModeAを合成した結果を渡すことを想定している。これによって、この関数内の複雑性を減らすことができる。またCustomerErrorTypeはENUMなので、case 'CODE1':のようにリテラルべた書きを回避できるうえ、仕様変更などで値が変わった時にも対応がしやすくなる。
また戻り値の型も削除する。これは静的解析により自明であるほか、Omit<SomeFormInvalidInfo, 'invalidReason'>とあるが、実際に返しているのはinvalidReasonであり、関連性がないためだ(おそらく、偶々よく似た型を転用しているのだろう)。またこの事例では更にinvalidReasonという変数名があり、Omitの内容と視覚的に競合し、コードの読解が難しいため、この修正により可読性が増す。
また改修前はエラーメッセージオブジェクトのキーと、ヘルプページのキー名、そしてswitchのキーの全てが食い違っており、見ていて混乱する内容だったが、ヘルプページのURLをべた書きするように変えたため、混乱する要素を減らせている。
まとめ
コードの記述量を減らし、長大なコードを別々のファイルに分けることや、過度に分割しすぎないことによって可読性が向上し、コード量が減ったため保守コストも削減できたと考えている。
半面、静的解析のコストは上がっているが、静的解析のコスト増よりも可読性がよく、保守コストが低いコードのほうが効率的な開発に寄与するだろう。
また静的な値を取得するためにMapを使い、TypeScriptを利用しているため、理論上undefinedが返ってこないのに、それを期待するロジックを削除することで、コードを読んだ人が混乱する可能性も削減している。
型安全で見通しの良いエラーハンドリング
この項目ではエラーメッセージを返すサーバー側のエラーハンドリングについて記述する。
元コード
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
if (error.graphQLErrors[0]?.extensions?.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
...
}
if (error instanceof SomeError) {
...
}
...
}
このコードの問題点
- エラーハンドリングが長々とべた書きされていて見通しが悪い
- 配列の添え字が直に指定されているが意図が読み取れない
- 例外処理なのにOptional chainingが多く確実な例外処理に支障がある(例外処理で例外が発生するリスクは最小限にする必要がある)
extensions配下の型情報が暗黙的でわからないgraphQLErrors: ReadonlyArray<{ extensions: { [attributeName: string]: unknown; } }>
改善後コード
const handleApolloError = (err: ApolloError) => {
if (err instanceof ApolloError) {
// graphQLErrorsが空であれば例外をスローし、そうでなければgraphQLErrorsを返す
const gqlErrors = parseGQLErrors(err.graphQLErrors);
// graphQLErrorsの中身をパースし、意味のある型を付けて返す
const extensions = parseThisFunctionErrors(gqlErrors);
if (extensions.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
}
}
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
handleApolloError(error);
} else if (error instanceof SomeError) {
...
}
...
}
べた書きされているとコードの見通しが悪いため、catch句の中では例外種別ごとにハンドリングする処理に飛ばし、そっちで処理できるようにする。
error.graphQLErrorsは要素が0の場合があるため、parseGQLErrors()のような共通関数を作り、要素があれば中身を返す、なければ例外をスローして、より上位の処理に飛ばすなどの処理を共通的に行うようにする。この仕組みを共通化することで、この要素に対する処理の一貫性を持たせることができる。
またgraphQLErrorsの詳細については処理によって内容が異なるであろうことから、ドメインごとにparseThisFunctionErrors()のような関数を作り、その中で適宜データを整形するのが望ましいだろう。
そうして結果的に意味のある型情報を持ったextensions、あるいは適当な結果情報をハンドリングすることで、型安全かつ、責務が別れ、疎結合な実装に寄与する。
この形式であればhandleApolloError()は必要に応じて別ファイルに切り出し単体テストを書くこともできるし、このままでもあっても規模が小さければ十分テスト可能だろう。
なお、parseGQLErrors()やparseThisFunctionErrors()の具体的な内容については今回は省略する。
- 投稿日:
Next.jsの全体設計を考えるときに疎結合性やテスト容易性を達成するときに考えているアーキテクチャについて簡単に書いてみる。
Page Router向けに作っていて、API Routesについては考慮していない。過去にこれに近い設計で開発していたことがあったが、単体テストによるデグレードや不具合、仕様漏れの検出はよくできていたと思う。今回書いたものは過去に考案し、開発していたもののブラッシュアップになる。
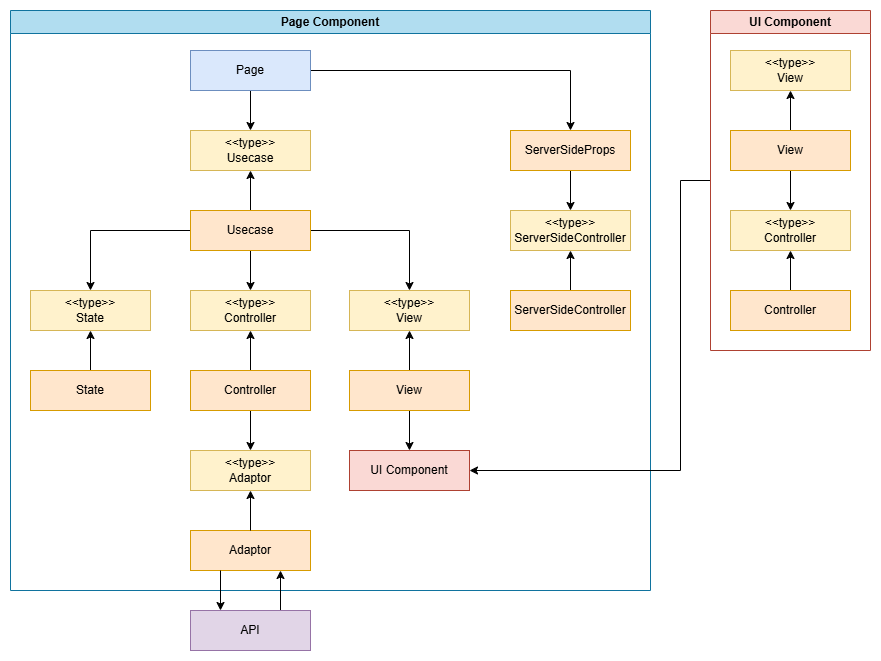
アーキテクチャ図
基本的に各レイヤー間はTypeScriptのtypeで仕切り、依存性を逆転させることで、テスト容易性や疎結合性を重視している。
ディレクトリ構成
アーキテクチャ図にないlibrariesが登場するが、これは汎用的な共通処理だ。
src
├─adaptors
│ └─User
│ ├─index.spec.ts
│ └─index.ts
├─components
│ └─form
│ └─TextInput
│ ├─index.spec.ts
│ └─index.ts
├─libraries
│ └─HttpClient
│ ├─index.spec.ts
│ └─index.ts
├─pages
│ └─hoge
│ ├─ServerSideProps.ts
│ ├─ServerSideController.spec.ts
│ ├─ServerSideController.ts
│ └─index.page.ts
└─usecaes
└─hoge
├─controller.spec.ts
├─controller.ts
├─state.spec.ts
├─state.ts
├─style.scss
├─usecase.tsx
├─view.spec.tsx
└─view.tsx
登場する各要素について
Page
画面本体。UsecaseとgetServerSidePropsを配置し、その橋渡しを行うだけの存在。
Usecase
StateとController、Viewを橋渡しする存在。
画面全体を別物にすり替える場合もここで行う。
useEffect()はここに書くが、中のロジックはController側に書く。
一見するとファサードであり、pageにべた書きしてもいいような内容だが、コードを書く時のコロケーションの観点から敢えて分離している。
また、画面のページレイアウトが全く別物になるなど劇的な変化がある場合は、この階層で分岐制御(ユースケース別の切り替え)する。
State
useState()で作った状態を定義する場所。それ以外は何もしない。
Controller
イベントハンドラによる処理を配置する場所。APIコールもここから行う。
状態については、typeを経由してState側で宣言した状態を注入して利用する。
状態を外部から注入するため、状態変化時のテストがしやすい。また画面からロジックをはがしているため、ロジック単体のテストが可能。
Adaptor
APIを呼ぶだけの存在。データの加工や例外ハンドリングは呼び元で行う。
APIを呼ぶだけの責務とすることで、複数のコンポーネントから呼ばれたときに同じAPIを呼ぶコードが重複したり、呼び出し元によってデータ加工手法を分けるなどの煩雑な実装を回避するのが目的。
テストとしては引数や戻り値、呼び出し方法が実装時から変わっていないかを見る観点のみあれば回帰テストとして機能する。
View
ほぼ純粋なJSXを書く場所。ロジックは原則として書かない。booleanを使ったDOMの切り替えは記述してよい。
制御はUsecaseでStateを合成したControllerで行う。
表示非表示の分岐のみにすることでtesting-libraryを利用したJSXの表示切替を単体テストとして実装できる。
UI Component
TextInputみたいな細かいパーツや、再利用されるフォームUIなど、UI系の共通部品。
基本的に状態は持たないが、無限ループが起きず、再利用されない状態(親に渡す必要がなく、自分自身に閉じた状態)については持ってよいと考えている。例えば、OK/CancelのあるモーダルでOKが押された時だけ呼び元に返す状態は持ってよい。
View, Controller
ページコンポーネント向けの内容に準ずる。Usecaseを持つほど大規模なコンポーネントはないと思うので、Usecaseなしで繋ぎ合わせてよいと考えている。
ServerSideProps
getServerSideProps()の中身。Page側では以下のようにして呼び出す想定。
import { execServerSideProps } from './ServerSideProps';
export const getServerSideProps = (async () => {
execServerSideProps();
});
ServerSideController
ServerSidePropsの中で利用するロジック。APIを呼ぶ場合はAdaptorとも繋がる。
利点
- 各レイヤーやコンポーネントでの単体テストが容易
- MVC的な構造のため理解しやすい
- SOLID原則で得られる利益を享受しやすい
- レビュー時に意図しないファイルに差分があった場合に、問題を検知できる
- コードマージ時のコンフリクト範囲を限定しやすい
欠点
- ボイラープレートコードが増える
- とはいえ、DDDよりは少ない
- Modelに相当するものがないため、ControllerがFatになる。またModel処理の共通化ができない
- Modelをどこに配置すべきかを検討できていない
- typeに破壊的変更が起きると数珠繋ぎに修正が必要になり、コストが重い
- その代わり型で各コンポーネントの関係性がわかる利点もある
あとがき
構想自体は4年前に考えたものだがアウトプットができていなかった。まだ煮詰まっていない上に考慮出来ていない部分もあるが、AppRouterの登場からだいぶ経ち、陳腐化してきそうだったので、取り敢えず吐き出した。
- 投稿日:
最近思っているNext.jsを使った画面設計に関する考えを箇条書きで雑に殴り書きしていく。この記事は考えの垂れ流しなので深い説明はしない。AppRouterではなく、PageRouterの考え。
- TypeScriptで実装し、型が騙せるような実装は極力避け、コードによる戻り値の型指定は不具合の原因になることがあるため、可能な限り型推論に任せる
- SOLIDな設計を意識することで疎結合でテストしやすい設計になる
- Clean Archtectureを意識することでSOLIDのSを意識しやすくなる
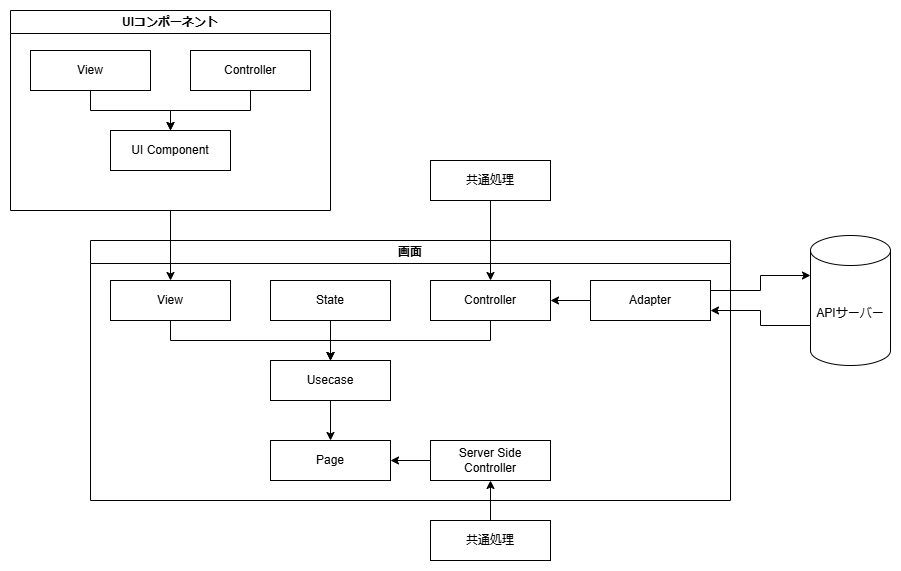
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
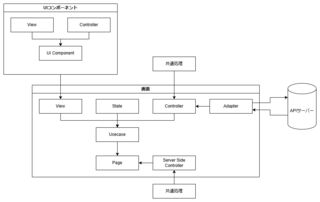
- ただこれはModelに相当するものがなく、ビジネスロジックの共通化に課題が出てくるのと、ControllerがFatになりすぎると考えており、そこが課題になると考えている。
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
- テストが容易なコードは必然的に疎結合になる
- 疎結合にする場合、命名を抽象的にしておくと処理の入れ替えが容易になる(命名が具象、つまり実装の詳細に依存しないため)
- 疎結合にするとパーツが増えるので認知負荷が上がる
- 疎結合でかつ、命名が抽象化されている場合、仕様を知らない人にとっては実際の処理内容を推測しづらくなる
- つまりこれは属人性が増えると考える
- 例外についてはErrorクラスを継承し、カスタム例外を作成して、用途に応じたハンドリングができるようにする
- 原則として処理を止める場合にのみ用いるべきで、続行する場合には使わない
- 例外は原則としてスローして、カスタムエラーは特定の階層でフィルタしてハンドリング、全てすり抜けてきたものはルート処理でキャッチしてハンドリングすることで、取りこぼしをゼロにする。例外の握り潰しは原則行わない
- 基本的にすべてロギングする
- 処理を継続するものについては例外とせず、ワーニング用の処理フローを作成し、それに則って行う(例えば入力バリデーションはワーニング)
- 投稿日:
単体テストは、コードの品質を向上させ、開発効率を高めるために欠かせないものだ。本記事では、単体テストを導入することで得られるメリットとその理由について解説する。
単体テストを書くことについて
単体テストを書くことには賛否両論あると思うが、私は書いたほうが良いと考えている。これは単にテストコードを書くことによってデグレが起きづらくなるからだけではなく、可読性の向上やコンフリクト頻度の減少など、様々な恩恵があるからだ。
この記事では、単体テストを書くことで得られるメリットについて書いていく。特に、関数を活用した開発(クラスを使わないスタイル)、TypeScriptでReactの関数コンポーネントを書くようなケースを前提に話を進める。
関数が小さくなる
単体テストの目的は、関数やクラスといった単位でその振る舞いを検証することだ。しかし、もし関数が1000行に及び、クロージャや分岐、ループが複雑にネストされていると、テストは非常に困難になる。つまり、これを回避しようとすると、自然と関数のサイズは小さくなり、責務が一つにまとまる設計となる。
関数が小さくなることでスコープが短くなり、見通しが良くなるほか、変数名を簡略化できる利点も生まれる。長すぎる変数名は基本的に有害だ。例えば以下のようなコードは誰も見たくないはずだ。(しかもよく見ると罠のようにも見えるコードだ)
const loooooooooooooooooooongVariableNameExtraResult = `${loooooooooooooooooooongVariableNameExtraParameter1} ${loooooooooooooooooooongVariableNameExtraParameter3} ${shortVar} ${loooooooooooooooooooongVariableNameExtraParameter2}`;
例えば、Go言語では一文字変数が一般的に受け入れられているが、これは関数のスコープが非常に短く、簡潔なコードが成立しやすい文化があるからだ。
疎結合な設計にしやすくなる
密結合なコードはテストがしづらい。そのため、単体テストを書こうとすると、自然と疎結合な設計になりやすくなる。具体的には、依存性逆転の原則に従った設計を採用するようになる。
例えば、次のようなコードはDate ()を直接使用しており、テストが困難だ。このような場合、Date ()をモックするために専用のライブラリやハックを使うことが多くなり、プログラムの保守性が悪化しがちだ。しかし、依存を外部から注入する設計にすれば、そういった心配は不要になる。
const isOneDayLater = (time: number) => {
return (+new Date() - time) > 86_400_000;
};
しかし、以下のように外部から値を注入すればモックしなくともテストコードを書くのが容易になる。第二引数に値を入れればいいからだ。
const isOneDayLater = (time: number, baseEpochTime: number) => {
return (baseEpochTime - time) > 86_400_000;
};
コンフリクトが起きづらくなる
Gitを利用した並行開発においてはブランチをマージするときにコンフリクト、つまりコードの競合が起きることがしばしばある。しかしこれまでに書いたように責務別にモジュール化された簡素なコードではコンフリクトの規模が自然に小さくなり、コンフリクト自体が減ったり、万一起きた時でも影響範囲が限定されるようになる。
コンフリクトの解消ミスがあり本番障害が出た、後続のQAフェーズなどで差し戻しが起きたみたいなのはよくある光景だと思うが、単体テストの導入による設計の改善があれば、それが起きた時のコストを減らすのに貢献することが可能だ。
コードの見通しが良くなる
適切に単体テストを意識してコードを書くと、自然と「べた書き」から「モジュール化」されたコードに変わる。
べた書きされたコードの例
例えば次のような関数は冗長だ。この程度の長さならまだしも、これが500行、1000行と増えていくと読むのが大変になる。現実ではもっとネストが酷かったり、前後に長大関数がいて、注意深く読まないと解読不能ということもままある。そしてこの関数をテストするのは書いてある処理すべてを検査する必要があるので、テストコードも長くなり、しんどい。
export const registerUser = async (user: User) => {
if (!/^\d+$/.test(user.id)) {
throw new Error('ユーザーIDの書式が不正です。');
}
if (user.firstName === '') {
throw new Error('姓が入力されていません。');
}
if (user.lastName === '') {
throw new Error('名が入力されていません。');
}
if (user.gender === '') {
throw new Error('性別が入力されていません。');
}
if (user.address === '') {
throw new Error('住所が入力されていません。');
}
const resp = await fetch('https://example.com/api/v1/user', {
method: 'POST',
body: JSON.stringify({
id: Number(user.id),
name: `${user.firstName} ${user.lastName}`,
gender:
user.gender === '0' ? 'male' : user.gender === '1' ? 'female' : 'other',
address: user.address,
}),
})
.then(async (resp) => await resp.json())
.catch((e) => e);
if (resp.status === 200) {
return resp;
} else {
const payl = resp.json();
return {
errorMessage: payl.errorMessage,
};
}
};
モジュール化されたコードの例
次のように書けば34行あった関数が9行にまで減り、見通しが良くなる。
export const registerUser = async (user: User) => {
validateUser(user);
const payload = createRegisterUserPayload(user);
const resp = await requestRegisterUser(payload);
return validateRegisterUserResponse(resp);
};
関数の中で何をしているかわからないという声もあるだろうが、関数名から内容を読み取れるようにしておけば問題にならない。読み取れない処理を入れなければいいのだ。こういう風にべた書きを一定の粒度で関数化することをモジュール化と呼ぶ。
この時、それぞれの関数(validateUser()など)は単一責務を持つため、単体テストのスコープが明確になる。親となる関数(この場合registerUser())のテストでは、子関数をモックすることで簡潔なテストが可能だ。この場合、親となる関数は子関数を呼び出すことが責務になる。
再テストの効率化
コードを直すことはよくあることで、コードを書いているときに一度書いたコードを直したり、レビュー指摘で直したりする。この時に、関係する部分を手動でテストするのは非効率だ。しかし、単体テストがあれば、その工数を大幅に削減できる。
特に分岐の網羅性が重要な場合、単体テストがあるとないとでは開発者の苦痛が大幅に変わるだろう。例えば、4つの分岐があるロジックでさえ、全数網羅では16パターンにも達するため、これを手動で見るのは手間である。しかしテストコードがあれば、自動テストを蹴るだけでいい。心理的負担も時間もこちらの方がローコストで現実的だ。
実装者が設計した時の意図がある程度読み取れる
コードを見ていて「こんなケースはないだろう」と思うことはしばしばあると思うが、そんな時にもしテストコードが存在すればケース名が書いてあるはずだ。それによって当時どのような意図で実装されたのかを知ることができる。これはコードの理解をより深く助ける手助けとなり、「負債に見えたから消したら不具合が出た」といったケースを減らすことに貢献することができる。
手動テストはなくならない
単体テストが充実していても、手動テストが完全になくなるわけではない。特に初回実装時は、プログラムが正しく動作するかどうかを確認する必要があるため、手動テストで動作確認を行い、その上で単体テストを信頼できる状態にするのが基本だ。
単体テストの限界と現実的な運用
さて、ここまで持ち上げてきた単体テストだが、決して銀の弾丸ではない。単体テストを入れてもバグを完全にゼロにすることは出来ないし、正しくないテストコードを書いたり、レビューが不十分であればテストが不正に通過する可能性もある。
正しくないテストコードを書かないための工夫としては、テストコードを書いた後に実装側を修正し、意図的にテストが落ちるようにしたときに、テストが落ちることを確認することが有用だ。これによって、実装が正しくない状態になったときにテストが正しく落ちることが確認できる。逆に落ちなかった場合、そのテストは機能していないと言える。
またテストを全数書くというのも非現実的であるため、TypeScriptの開発であれば型を騙すasのようなものは使わず、極力正しい型を検証できるように静的解析に任せるのが良い。戻り値の型指定も場合によっては型を騙すのに使えるケースがあるため、バグを生み出す元になる場合もあり、気を付けたほうが良い。
何より単体テストで見れるのは単体であり、結合は見れないため、あくまで単体テストはベースのロジックを担保するものとして使い、全体面は結合テストやe2eテスト、手動テストで見ていくのが良いだろう。
理想的には単体テストで網羅し、正常系と異常系のそれぞれ1パターンを結合で、初回実装時のみ手動テストというのがよいと考えている。これは結合テストで網羅ケースを書いてしまうと単体テストを書く意味がないうえに、重複テストが大量に発生し、実行速度が遅くなるし、規模が大きい分メンテナンスが大変になるからだ。
e2eテストは決済などのクリティカルケースにはあったほうが良いと思うが、コストの重さからしてそれ以外にはあまりなくてよいと思う。大抵のケースで手動の方が楽だろう。手動テストでは結果の誤りが出る可能性は残るが、些末な処理で100点を目指しても仕方がないので、多少の不具合は許容で良いのではないかと思う。
単体テストが有効に機能しづらいケース
単体テストは銀の弾丸ではないため、機能しないケースが当然ある。
元から単体テストがないプロジェクトに導入するケース
元々単体テストが導入されていないプロジェクトでは多くの困難を伴う。
例えば、関数やクラスがべた書きされており、責務が曖昧なまま複雑に絡み合っているコードでは、単体テストを書くこと自体が非常に難しい。分解しようにも目に見えている範囲だけを直せないケースも少なくない。これは他の機能がその機能と強く結合しており、根幹となる部分から直していかないと上手くいかないケースがあるからだ。
この状態の関数に対するテストを書いても、リファクタリングで分割された時の動作保証がやりづらい。何故ならこの手のものは大抵きれいに分割できず、再集計になるまでに紆余曲折をたどるからだ。
単体テストに対する理解が異なるケース
「単体テスト」の「単体の単位」が上手く認識されていない場合、本来あるべき単体テストの意義や役割が意識されていないことがある。これは結合テストやe2eテストが単体テストとして扱われているケースだ。
例えば画面の単体テストの定義が、実際に画面を操作し、APIをコールし、その結果に基づいた動作の確認だったり、複数の関数を呼び出す関数を単体として考えているケースでは、単体に対する意識が異なるため、本来あるべき単体テストの導入が難しいことがある。
有効な開発標準やコーディング規約が存在しないケース
有効な開発標準やコーディング規約がなく、コードの裁量がメンバー個々人に委ねられているケースでは、チームメンバーがそれぞれ独自のスタイルでコードを書いていることもあり、より問題を複雑化させることもある。
こういったケースではありとあらゆるコードが想定外の振る舞いをするため、単体テストの導入を阻む障壁となる。
破壊的変更が多いケース
これは要件や仕様などの上流部分が固まらず、日々変動するようなプロジェクトの話だ。
いつ仕様が固まるかわからないのでコードだけは書き続ける必要があり、日々変わるので動作確認もおろそかになる。このようなプロジェクトでは書いたコードが無価値化することが日常であるため、テストコードを書くという行為自体が陳腐化していきがちだ。
単体テストを書く文化がないケース
プロジェクトの方針として単体テストを書くことを推奨していなかったり、認めていない場所がある。こういった場所では、単体テストの重要性が理解されていないことも少なくなく、テストを書くことがむしろ「余計な作業」として扱われることがある。そういったシーンで単体テストを書くと、プロジェクト内で孤立するリスクがあり、難しい。
まとめ
単体テストを書くことで自然とSOLID的な設計に近づき、コードが読みやすくなり、ある程度変更に強く、開発速度も上がり、一定の品質も担保出来るため、単体テストを書くことによる恩恵は少なくない。これは間違いなくメリットだ。
しかし一方で、単体テストは銀の弾丸ではなく、密結合でテストしにくいコードや、頻繁に仕様変更が発生するプロジェクト、文化的に単体テストが認められていない環境では上手く機能しないケースもある。