2026/03/05(木)最近作ったWebツールの話とか
投稿日:
最近二つほどツールを作り、Webツール置き場に配置したので、そこで得た学びや、作る時に意識したことについても書いてゆく。
ENV Checker
まずENV Checkerを作った話。

端的に言うとCyberSyndrome : ENV Checker - 環境変数チェッカーのパクリである。但しJSがないと動かない。
違いとしてはCyberSyndrome側で見れる情報のうち、ユーザー環境に起因しない情報を大幅に削り、ユーザー環境をメインに出せるようにしているほか、IPv4とIPv6の表示にも対応している。
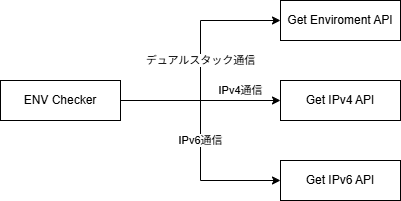
作りとしては必要な情報を返すAPIを3つ用意し、ページを表示したときにJSがそれぞれを叩きに行き、その結果を表示している。
Get Enviroment APIはIPアドレス以外の環境変数を返却するもので、Get IPv4 APIはIPv4アドレスとホスト名、Get IPv6 APIはIPv6アドレスを返すように作ってある。
なぜこの様な分け方にしたかというと、Get Enviroment APIはIPのバージョンを問わない情報しか返さないが、IPアドレスまで返すようにするとIPv4に付随する情報やIPv6アドレスを返すことになるため処理が煩雑になる。
これは実装としてはCGIの環境変数をそのまま返しているのでREMOTE_ADDRに:が含まれているかどうかを見てIPv4か、IPv6かを振り分ける処理が必要になるからだ。
一方でGet Enviroment APIが環境変数だけを返すことに専念できるのならば、IPv4に付随する情報はGet IPv4 APIを叩けば取れるし、IPv6はGet IPv6 APIを叩けば取れるため、分岐処理が不要になる。
これによって各APIは単一の責務だけを持つことになり、コードの複雑化を回避できるといった寸法だ。この程度のシンプルな実装に求めることではないし、現状では無価値ではあるのだが、常日頃から意識することで、より複雑なものを作る時にも生かせるだろうし、将来何か改修するときにも作りが単純なほうが理解しやすいと思うので、こうしている。
IPv4とIPv6のAPIをどう分けているかというと、これはDNSレベルで解決している。Get IPv4 APIのエンドポイントにはAレコードのみを、Get IPv6 APIのエンドポイントにはAAAAレコードのみを設定することで、クライアントが接続する際に使用するIPバージョンを強制している。
こうすることで、各APIは単純にREMOTE_ADDRをそのまま返すだけでよくなり、IPバージョンの判定ロジックを一切持たなくて済むのが利点だ。欠点としてはAPIの数が一つ増えるため、管理コストは増えているといえるだろう。しかし分岐ロジックというのは往々にしてバグを生む存在であり、ないに越したことはないと思い、こういう設計にした。
また画面の描画をJavaScriptにさせているのも、こういったいわゆる関心の分離の思想によるところが大きい。やろうと思えばIPアドレス以外はCGIで表示して、IPアドレスのところだけをJSで書き換えることも、当然できる。出来るのだが、責務を分けるにはデータを返すだけのエンドポイントと、それを受けてJSで書き換える手法のほうが、より責務がはっきりしていて、わかりやすいのでこうしている。疎結合ということでもある。
項目値をダブルクリック・タップすることで値をコピーできるようにしているのも、地味だがこだわりポイントだ。
余談だが、先日Value-DomainでcertbotのDNS Challengeをやるスクリプトを書き直したのは、このドメインにTLS証明書を付与したり、DDNSできるようにする目的があったのが大きい。
というのも、このENV Checkerの開発にはipv4.lycolia.infoとipv6.lycolia.infoというドメインが関係しており、私の自宅サーバーの環境はIPv4がコロコロ変わるためDDNSが必須だった。
私が利用しているDNSレジストラであるValue-DomainはDDNS用のエンドポイントがあるのだが、1回1ドメインしか更新できず、60秒に1度しか叩けないという制約があり、これを回避するためには、Value-DomainのDNS APIに対して、一回で複数ドメインのAレコードを書き換える必要があった。
また同時に、以前使っていた、TLS証明書更新ツールである、value-domain-dns-cert-register (vddcr)はNode.jsのアップデートなどに伴う頻繁なメンテナンスが必要だったり、動作検証不足があったり、様々な面倒ごとがあり、これ以上触りたくなかった。
そんなこんなの流れがあり、ENV Checkerを作る中でOpenWrtからValue-Domainに複数サブドメインのDDNSを行うツールを作ったり、新たなTLS証明書更新ツールを作り、その検証をしたりしたのだ。
QRコードジェネレーター
もう一つはQRコードジェネレーターを作った話。
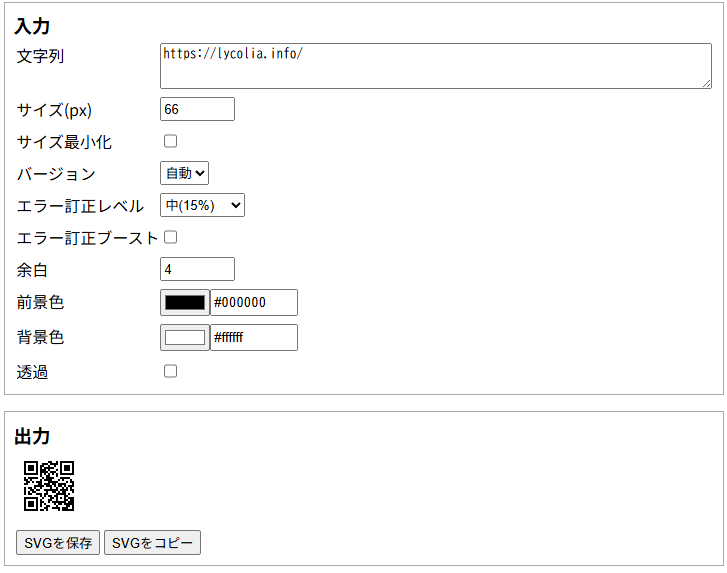
QRコードジェネレーターなどググれば無数に出てくるわけだが、意外と読み取り可能な最小サイズかつ、それをSVGで出力できるものを見つけることができなかった。そこで作ることにした。
とはいえ、作ったのはフロントエンドだけで、QRコードの生成自体はqrcode-svgを使わせてもらっている。これはこのライブラリのデモサイトで、理想の要件のものが作れることが分かったからだ。
なぜデモサイトで使えるのに、わざわざ作ったかだが、まずこのデモサイトでは最小サイズのQRコードを簡単に得ることが困難だったほか、256px以下のサイズにすることが想定されていないように見えたからだ。少なくともUIをクリックしてDIMENSIONを256px未満にしようとしても出来なかった。
また、デモサイトはいつか消える可能性もあるし、ブックマークするのも面倒なので、自分でホスティング出来るなら、それをするに越したことはなかったというのもある。

これを作っている中で得た学びとしては、カラーパレットの入力UIがWeb標準で可能になっていたことだ。そこら中で見かけるし標準であるんちゃうか?と調べたらあったので採用した。こういう複雑なものは昔であれば恐らく何かしらのライブラリを使うか、気合で作る必要があったと思うが、全く世の中は便利になったものだ。
また、こちらの実装方法については、HTMLの標準機能でカラーパレットを使ったカラーコード入力UIを作る方法の記事で紹介している。
他にもQRコードの周りには余白が必要ということも知れた。QRコードの開発元であるデンソーウェーブでは余白の求め方の計算式が解説されている。仕様上は適切な余白がない場合、読み込めない可能性があるようだ。これは恐らく周囲の図形とQRコード本体を光学的に分けて認識させるために必要なのだと思う。
なお、今回作成したQRコードジェネレーターには余白の自動調整機能は実装していない。理由は単純でサイズを自由に変えられる仕様上、帳尻をつけるのが面倒だからだ。要は手抜きである。
ついでにWebツール置き場の保守性や解りやすさを少し上げたりした
Webツール置き場のドメイン配下は元々全てペラのHTMLで実装していたのだが、ページが増えるごとに共通部分のhead要素の管理が煩雑になっていた。そこで、PHPに置き換えることにした。
結果として、以下のように、head要素の中身を共通化することができた。
まぁやっていることとしては高校時代にPHPで静的HTMLの内容を共通化していたのと何ら変わらないので、何故今更そんなことを…という感じだが、元々は静的HTMLで済むものは静的HTMLのほうが表示速度が速くシンプルでよいよなという意図で、静的HTMLにしていたのだが、数が増えてくるとそうも言ってられないということで対応した形だ。こういうのは事前に考慮しすぎると、早すぎる共通化やKISSの法則的なリスクを孕むと思っていて、定期的に振り返り、都度対応するほうが良いと感じている。いや、この程度の内容でそこまで考える必要はないと思うが…w
<!DOCTYPE html>
<html lang="ja">
<head>
- <meta charset='utf-8'>
- <meta http-equiv='X-UA-Compatible' content='IE=edge'>
- <title>Slackのリマインダーコマンドを作るやつ</title>
- <meta name="referrer" content="no-referrer-when-downgrade"/>
- <meta name="viewport" content="width=device-width, initial-scale=1">
- <meta name="author" content="Lycolia Rizzim">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <meta property="og:site_name" content="Lycolia">
- <meta property="og:title" content="Slackのリマインダーコマンドを作るやつ">
- <meta property="og:description" content="必要事項を埋めることでSlackの/remindコマンドを生成するやつ">
- <meta property="og:type" content="website">
- <meta property="og:image" content="https://tool.lycolia.info/slack-remider-creator/OGP.png">
- <link rel="stylesheet" href="style.css">
- <script src="check.js"></script>
- <!-- Matomo -->
- <script>
- var _paq = window._paq = window._paq || [];
- /* tracker methods like "setCustomDimension" should be called before "trackPageView" */
- _paq.push(['trackPageView']);
- _paq.push(['enableLinkTracking']);
- (function() {
- var u="https://analytics.lycolia.info/";
- _paq.push(['setTrackerUrl', u+'matomo.php']);
- _paq.push(['setSiteId', '3']);
- _paq.push(['enableHeartBeatTimer', 10]);
- var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
- g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
- })();
- </script>
- <!-- End Matomo Code -->
+<?php
+require_once('../template.php');
+
+renderCommonHead(
+ thumbnail: 'https://tool.lycolia.info/slack-remider-creator/OGP.png',
+ title: 'Slackのリマインダーコマンドを作るやつ',
+ description: '必要事項を埋めることでSlackの/remindコマンドを生成するやつ'
+);
+?>
</head>
template.phpの中身
関心ごとに関数を切り分け、呼び出される側は呼び出す側に依存するように設計することで、親が子の変更に引きずられないように保守性を意識した設計にしている。他にもほとんど固定値であるものについては運用を平易にする観点からOptional化して、初期値を設定している。
<?php
function buildMatomo() {
return <<<END
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://analytics.lycolia.info/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '3']);
_paq.push(['enableHeartBeatTimer', 10]);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
END;
}
function buildCommonMeta(string $title, string $thumbnail) {
return <<<END
<meta charset='utf-8'>
<meta http-equiv='X-UA-Compatible' content='IE=edge'>
<title>$title</title>
<meta name="referrer" content="no-referrer-when-downgrade"/>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="author" content="Lycolia Rizzim">
<meta name="thumbnail" content="$thumbnail">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-32x32.png" sizes="32x32">
<link rel="icon" href="https://lycolia.info/assets/brands/lycolia-192x192.png" sizes="192x192">
<link rel="apple-touch-icon" href="https://lycolia.info/assets/brands/lycolia-180x180.png">
END;
}
function buildOG(
?string $thumbnail,
?string $site_name,
?string $title,
?string $description,
?string $type
) {
$tags = " <meta property=\"og:type\" content=\"$type\">\n";
$tags .= " <meta property=\"og:site_name\" content=\"$site_name\">\n";
if ($thumbnail !== null) {
$tags .= " <meta property=\"og:image\" content=\"$thumbnail\">\n";
}
if ($title !== null) {
$tags .= " <meta property=\"og:title\" content=\"$title\">\n";
}
if ($description !== null) {
$tags .= " <meta property=\"og:description\" content=\"$description\">\n";
}
return $tags;
}
function renderCommonHead(
?string $thumbnail = 'https://lycolia.info/assets/brands/lycolia-OGP.png',
?string $site_name = 'Lycolia.info',
?string $title = null,
?string $description = null,
?string $type = 'website'
) {
$head = buildCommonMeta($title, $thumbnail);
$head .= buildOG(
thumbnail: $thumbnail,
site_name: $site_name,
title: $title,
description: $description,
type: $type
);
$head .= buildMatomo();
echo $head;
}
また他にも、ドメイン直下にあるページの構造を見直した。
具体的にはulとliでリストにしていた部分をdl dt ddに直し、各ツールの内容を少し解りやすくした。ただ余りにも見た目が殺風景すぎるので、liに戻してカードUIをはめ込むようにするかもしれない。
| 変更前 | 変更後 |
|---|---|
 |
 |
2025/07/28(月)久々にクラスを書いたので、設計時の考えを書いてみる
投稿日:
自動生成されたHTMLから社員情報を引っこ抜くスクリプトを作った時に考えたことを書き出してみる。ブラウザのDevToolsを使った簡易ツールを書いていて、頭に浮かんだことだ。データやコードは架空の内容なので実在しない。
ベースのHTML
大まかに最初に目に入ってきたのはこんな内容だった。機械生成されているせいかフォーマットがガタガタ気味だ。
<span class="Content">
<span id="undefined">SHAIN.XLS page1</span>
</span>
<span class="Content">
<br>
<span id="undefined">社員リスト</span>
<span id="undefined"></span>
</span>
<span class="Content">
<br>
<span id="hoge1">00001</span>
<span id="fuga1">:山菱喜一</span>
</span>
<span class="Content">
<br>
<span id="hoge2">00002</span>
<span id="fuga2">:鈴木与一</span>
</span>
<span class="Content">
<br>
<span id="hoge3">00011</span>
<span id="fuga3">:茨城妙子</span>
</span>
<span class="Content">
<span id="undefined">SHAIN.XLS</span>
<span id="undefined"> page2</span>
</span>
<span class="Content">
<br>
<span id="hoge4">00012</span>
<span id="fuga4">:奈良楓</span>
</span>
...
まずは関数ベースで考える
ひとまず普段は関数ベースで実装しているので関数ベースで実装する。書いていてgetEmployee(name, list)の仮引数にあるlistは冗長ではないかということに気づく。
const emp_list = document.getElementsByClassName('Content');
[...emp_list].reduce((acc, cur) => {
if (cur.id === 'undefined' || cur.children.length !== 3) {
return acc;
} else {
const id = cur.children[1].innerText;
const name = cur.children[2].innerText.replace(/^:/, '');
if (/^\d+$/.test(id)) {
acc.push({ id, name });
}
return acc;
}
}, []);
const getEmployee = (name, list) => {
const re = new RegExp(`.*${name}.*`);
const result = list.filter((emp) => re.test(emp));
console.log(result);
};
クラスにしてみる
そしてクラスにしたほうが素直にならないかと考え、クラスにしてみた。getEmployee(name, list)はsearch(name)となり、冗長性が減ったほか、抽象的な表現で分かりやすくなった気がする。
class EmployeeSearch {
constructor() {
const emp_list = document.getElementsByClassName('Content');
this.list = [...emp_list].reduce((acc, cur) => {
if (cur.id === 'undefined' || cur.children.length !== 3) {
return acc;
} else {
const id = cur.children[1].innerText;
const name = cur.children[2].innerText.replace(/^:/, '');
if (/^\d+$/.test(id)) {
acc.push({ id, name });
}
return acc;
}
}, []);
}
search(name) {
const re = new RegExp(`.*${name}.*`);
const result = this.list.filter((emp) => re.test(emp.name));
console.log(result);
}
}
追加仕様に合わせ関数を新設し、クラスを改良する
動作確認をしていく中で表示と名前が分かれたパターンを発見したので、これに合わせて直してゆく。
<span class="Content">
<br>
<span id="hoge2">00002</span>
<span id="fuga2">:飯田</span>
<span id="piyo2">太郎</span>
</span>
この対応をしようとすると分岐が必要だと考えたが、愚直にやってしまうとコンストラクタの中がごちゃつく上、テストもしづらいと考え、DOMをパースする処理を外部関数に切り出し、それを呼ぶことにした。
const getEmployeeFromList = (domList) => {
const id = domList[1].innerText;
const name1 = domList[2].innerText.replace(/^:/, '');
if (domList.length === 3) {
return {
id,
name: name1
}
} else {
const name2 = domList[3].innerText;
return {
id,
name: `${name1}${name2}`
}
}
};
class EmployeeSearch {
constructor() {
const emp_list = document.getElementsByClassName('Content');
this.list = [...emp_list].reduce((acc, cur) => {
if (cur.id === 'undefined' || cur.children.length < 3) {
return acc;
} else {
const { id, name } = getEmployeeFromList(cur.children);
if (/^\d+$/.test(id)) {
acc.push({ id, name });
}
return acc;
}
}, []);
}
search(name) {
const re = new RegExp(`.*${name}.*`);
const result = this.list.filter((emp) => re.test(emp.name));
console.log(result);
}
}
更により良くするには?
ブラウザのDevToolsにあるConsoleで書いたコードなので、現実問題テストコードも書かないし、そこまで凝る必要もないのが、よりよい設計にするにはコンストラクタでパースせず、事前にパース処理した結果をコンストラクタを通じて注入して処理するようにするとよいだろう。そうすると責務が分離され、テストがしやすく、コードもきれいになると考える。
クラスにするか、関数にするか
これはまだ正直答えが見えていないが、インスタンスを引き回す場合はクラスのほうが都合がいい可能性がある気がしてきている。
関数でもできるにはできるが、毎回引数にインスタンス相当のものを渡すのは冗長である可能性がある。疎結合という文脈では関数のほうがより良い可能性もあるが、人間の認知負荷や、保守性との兼ね合いだと思う。
明確な損益分岐点はまだ見えていないし、今回のケースだと割とどっちでもいい部分もあるとは思う。
2025/06/04(水)例外設計について普段考えていること
投稿日:
例外設計についての個人的に思っていることを書き出してみる。整理できていないがいったん現状。TypeScriptのケースを意識して考えているが、根幹は例外スローのある言語ではどれも共通だと考えている。
例外とは何か?
本記事で扱う例外とはthrow new Error("ほげほげ");のように、いわゆるスローされ、try-catchされるものを指して扱う。
例外を多用しない
例外は多用しないことが望ましく、原則として処理が続行不能になる場合を除き、使わないほうが良いと考えている。これはスローされた例外は可視化されづらく、適切にハンドリングされないケースがよくあるからだ。
例外は構造化されたプログラムを破壊する
構造されたプログラムとは順次・反復・分岐の基本構造を階層的に組み合わせたものであり、いわゆる上から下に読めばわかるもの、構造化プログラミングによって作られるものだ。上から下に流れるため非常にわかりやすい。
これに対して存在するのがgotoを用いたプログラムだ。gotoを使うとコードの色んな場所に前後しながらジャンプすることが可能で、可読性を損ねてしまう。
そして例外は基本的にgotoのような存在である。例外が起きると例外オブジェクトが投げられ、これはどこに行きつくか予想することが難しい。行きつく先がなければ最悪プログラムがクラッシュする恐れすらある。
例外は処理コストが重い
恐らく大抵の言語において例外をcatchする行為はコストが重い。これはJavaでは特に有名な話だと思うが、Java以外でもそうだと思う。例えばNode.jsでtry-catchで例外を処理するプログラムと、if-elseで処理するプログラムを書き、その実行速度を比較するとif-elseの方が早い。
以下はエラーハンドリングをifで行うプログラムと、try-catchで行うプログラムを作り、100万回走行させたときの処理時間だ。catchに入るケースでは処理速度が低下することが分かる。例外が投げられず、tryの中に納まる限りは低下しない。
| 処理 | 処理時間(ms) |
|---|---|
| If正常系 | 4,453 |
| If異常系 | 4,204 |
| try-catch正常系 | 4,341 |
| try-catch異常系 | 7,883 |
これは例外が投げられる場合、最寄りのcatchポイントを探索するのに時間がかかるからではないかと考えている。
Node.js向け検証コード
前述の処理時間を出すのに使ったプログラム
// ==== 実行用共通部品
const execIf = (input) => {
if (input === 1) {
return true;
} else {
return false;
}
};
const execThrow = (input) => {
if (input === 1) {
return true;
} else {
throw new Error('ERR');
}
};
// ==== コールバック処理計測用関数
const getExecFuncElapsed = (cb) => {
const startAt = +new Date();
for (let i = 0; i < 1_000_000; i++) {
cb();
}
return +new Date() - startAt;
};
// ==== If/try-catch検証用、コールバック処理群
const execIfOk = () => {
const ret = execIf(1);
if (ret) {
console.log('OK=');
}
};
const execIfNg = () => {
const ret = execIf(0);
if (ret === false) {
console.log('ERR');
}
};
const execThrowOk = () => {
try {
execThrow(1);
console.log('OK=');
} catch (e) {
console.log('ERR');
}
};
const execThrowNg = () => {
try {
execThrow(0);
console.log('OK=');
} catch (e) {
console.log('ERR');
}
};
// ==== 計測処理
const elapsedIfOk = getExecFuncElapsed(execIfOk);
const elapsedIfNg = getExecFuncElapsed(execIfNg);
const elapsedThrowOk = getExecFuncElapsed(execThrowOk);
const elapsedThrowNg = getExecFuncElapsed(execThrowNg);
// ==== 結果出力
console.table({ elapsedIfOk, elapsedIfNg, elapsedThrowOk, elapsedThrowNg });
いつ例外を使うか?
基本的には大域脱出がしたいケースのみで使うべきだろう。最悪ハンドリングされずとも、基底階層でcatchされれば、それでよいケースで使うのが最も無難だと考える。
大域脱出とは要するにgotoだ。多重ネストや深い高階関数から浅い階層に一気にすり抜けるときに有効だろう。逆に一階層とか、抜ける階層が浅いレベルでは使わないほうが良い。
例えば処理が続行不能になったケースでは例外をスローし、基底階層でcatchし、エラーログを吐く、クライアントに対してエラーメッセージを返すなどの処理があればよいと考える。
但し例外を使うときは極力カスタム例外を使ったほうがよいと考える。
フレームワークやライブラリの例外をどう扱うか?
例えばバリデーションエラーやHttpClient系の4xx, 5xx系の例外スローはラッパーを作り、例外をエラーオブジェクトに変換するのも一つだと考える。
HTTP GETを行うクライアント関数であれば以下のようなラッパーを作り、正常時は正常レスポンスを返し、異常時でかつ想定内であればエラーオブジェクトを返す、そして想定外の例外であればリスローする、といった処理をすることができる。
const httpGet = (url) => {
try {
return fetch(url);
} catch (e) {
if (e instanceof AbortError) {
return createHttpErrorObj(e);
} else {
throw e;
}
}
}
こうすることで呼び出し元は正常時であればHTTPリクエストをそのままステータスコードに応じて処理し、Abortされた場合はリトライ、完全に予期せぬ内容であれば例外を基底階層まで飛ばして処理を中断するといったこともできる。
リトライに規定回数失敗した場合は、この関数の呼び元でnew OutOfTimesHttpRetryError()みたいな例外をスローするとよいだろう。
カスタム例外を使う
カスタム例外とは例外クラスを継承した例外クラスだ。
例えばC#ではExceptionのほかに、それを継承したSystemExceptionや、IndexOutOfRangeExceptionなど、様々なカスタム例外が存在する。
LaravelにもAuthorizationExceptionをはじめとし、多様なExceptionが存在する。
これらに限らず、大抵の言語やフレームワークには相応のカスタム例外が用意されているのが一般的で、業務システムやC2のプロダクトでも、例外をスローするケースではカスタム例外を作ることが望ましいと考える。
カスタム例外があると例外種別ごとにフィルタリングすることが可能になり、柔軟にハンドリングしやすく、ロギングの際にも例外種別を記録することで、後々の障害調査でも便利になるため有用だ。
例外を握りつぶさない
例外は時として握りつぶされることがある。そういう必要があるケースも少なからずあるだろう。しかし基本的に例外は握りつぶさないほうがよい。
例外は望ましくない現象が起きているはずで、本質的にハンドリングする必要がある。単に握りつぶしているだけでコメントやテストも書かれていなければ、もし例外が起きたとき、処理が正常に進むのかどうかコードから読み取ることが困難だ。
仮にテストがあったとしてもコードを読むときのコストが増えるので、基本的に握りつぶさないほうがよいだろう。
スローする場合は、例外クラスを用いる
JavaScript系では以下のようなエラーオブジェクトを作るケースもあると思うが、スローする場合は使わないほうが良い。
{
__type: 'HogeError',
message: 'fufagfuga',
payload: someObject
}
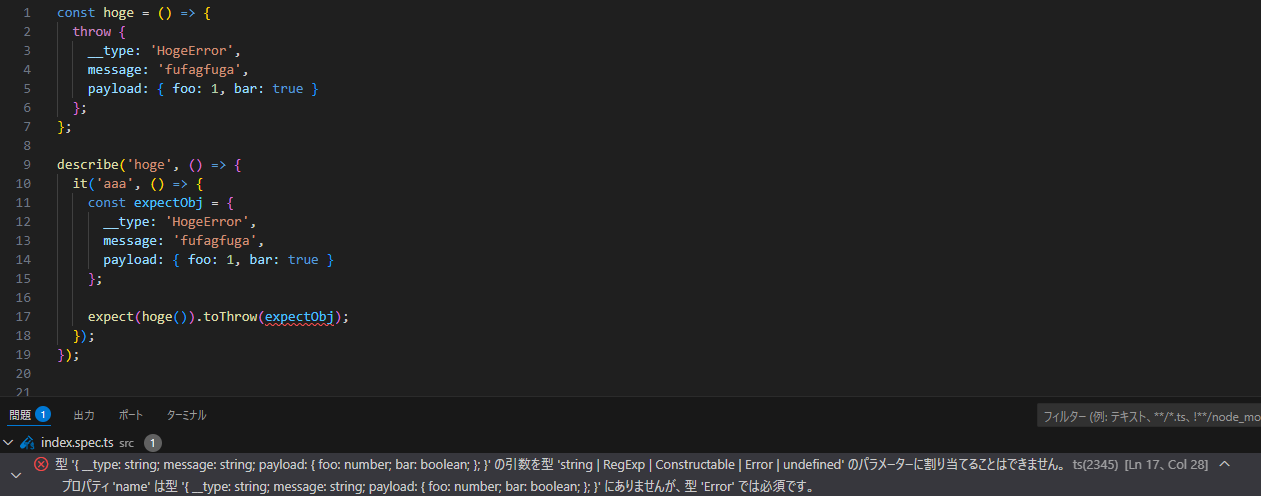
スローする場合はErrorクラスを継承したカスタムエラーをスローすべきだ。これはカスタムエラーにはスタックトレースなど、障害調査をするときなどに例外として標準的な情報が格納されているほか、instanceofでフィルタしやすい、クラスは型情報を持つのでリファクタが容易、error.__type === 'HogeError'は言語機能の再実装に近く標準的ではないからだ。テストフレームワークでも例外をキャッチするためのアサーションではErrorクラスの継承が必須となっているケースがあるため、TypeScriptでは型検査が上手く通らないケースがある。
2025/04/24(木)実務で出会いそうなコードの改善術
更新日:
投稿日:
投稿日:
今回は実際の開発現場で遭遇しそうなコードパターンを2つ挙げ、それらを主に可読性向上と保守コスト削減の視点から、どのように改善できるかを具体的に書いてゆく。
サンプルコードはTypeScript + GraphQLを使ったAPサーバーを想定して書いている。
命名とデータ構造の最適化
この項目ではエラーメッセージを返すサーバー側の処理について記述する。
元コード
resolvers/customer-info/helpers/invalid-reason.ts
type ReferencePageLinkMapKey = 'userFormIssue' | 'duplicateUserName' | 'someErrorMessage';
// exportされているがgetInvalidInfo(key, boolean)でreferencePageLinkMap.get(key)が返ってくることを確認するテストに使われているだけ
export const referencePageLinkMap: Map<ReferencePageLinkMapKey, string> = new Map([
['userFormIssue', 'https://help.example.com/23843ddvwa'],
['duplicateUserName', 'https://help.example.com/xdxdk2t5'],
['someErrorMessage', 'https://help.example.com/pp33s'],
...
]);
const invalidReason = {
inputIssue: {
message: '入力項目にエラーがあります。...',
links: [
{
label: '【登録時のヘルプページをご確認ください】',
url: referencePageLinkMap.get('userFormIssue') ?? '',
},
],
},
...
};
export const getInvalidInfo = ({
errorReasonType,
isModeA,
}: {
errorReasonType: ErrorReasonType;
isModeA: boolean;
}): Omit<SomeFormInvalidInfo, 'invalidReason'> => {
switch (errorReasonType) {
case 'INVALID_INPUT':
case 'SOME_INPUT_ERROR':
return invalidReason.inputIssue;
...
};
}
このコードの問題点
- 定義する必要性が希薄な型情報があり、改修コストが高い
- 変数や関数名、キー名などから相関する機能の関連性を読み取りづらい
- 定義されたスコープを超えて利用されているもので命名から機能の読み取りが難しいものがある
- リテラルがべた書きされており将来のリファクタリングに支障がある
- 不必要にMapが使用されており、実装が冗長になっている
- 静的な値の取得にNull合体演算子が使用されており、潜在不具合となりやすい
- 型情報がべた書きされすぎており、見通しが悪い
- 複数のフラグ値の正規化を利用側で行っており、複雑になっている
改善後コード
リソースファイルと実装が一緒くたであると読みづらいためファイルを分割する。パスも書いているがパスについては深く考慮できていない。
resources/messages/CustomerError.ts
export const ERROR_MESSAGES = {
formValidationError: {
message: '入力項目にエラーがあります。...',
helpLinks: [
{
label: '【登録時のヘルプページをご確認ください】',
url: 'https://help.example.com/23843ddvwa',
}
],
},
...
} as const;
まずtype ReferencePageLinkMapKeyは無駄に型の管理コストが増えるだけなので削除する。意味がないとは言わないが、型の追加削除によって発生するデグレードは普通は型検査でわかるためなくてよいだろう。
次にreferencePageLinkMapでは意味がわからないのでERROR_MESSAGESにリネームする。中身のキーもinputIssueでは分かりづらいのでformValidationErrorとし、フォームのバリデーションエラーであることが分かるようにする。linksについても何のリンクなのかわからないためヘルプのリンクであることを明示できるようにリネームする。
helpLinks.urlについては、共通のURLを参照する概念は普通ないか、あったとしても別に切り出して管理するのはコストなので直に書いてよいと考える。元のコードでもテストコード以外には使われていない。テストコードには実値を書かないと回帰テストとして機能しないため、この方式のほうがより良いと考える。
例えば以下のようなテストコードは回帰テストの観点では意味が薄い。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe(invalidReason.get('inputIssue'));
});
これは以下のように書くことでページのURLが変更されたときにテストが失敗するため、より価値のあるものになる。但しこれはexpect(invalidInfo).toStrictEquals({ ... })の形で一括判定したほうが、テストコードの可読性の観点からより良いだろう。
it('INVALID_INPUTの時にurlが正しい結果になること', () => {
const invalidInfo = getInvalidInfo('INVALID_INPUT', false);
expect(invalidInfo.links[0].url).toBe('https://help.example.com/23843ddvwa');
});
ERROR_MESSAGESをリソース変数としてみなせば、これはべた書きというより定数定義とみなせるため、基本的には問題ないと考える。勿論これは同じURLを持つものが大量にあるなど、ケースによっては考慮の余地はあるだろう。
またMapをやめ、敢えて直値を書くことで万一存在しなかった場合に、元にあった以下の空文字が返ってきて機能しなくなる問題も解決している。そもそも通る余地がないロジックなので存在しなくてよい。
url: referencePageLinkMap.get('userFormIssue') ?? ''
またERROR_MESSAGESにas constを付与することで、意図しない破壊が起きる可能性を減らすことができる。
handlers/error/GetCustomerInfoError.ts
export const getCustomerInfoError = (errorType: CustomerErrorType) => {
switch (errorType) {
case CustomerErrorType.INVALID_INPUT:
case CustomerErrorType.SOME_INPUT_ERROR:
return ERROR_MESSAGES.formValidationError;
...
};
}
まずgetInvalidInfo()をgetCustomerInfoError()にリネームすることで意味を分かりやすくしている。次に複雑な型情報を除去してシンプル(= (errorType: CustomerErrorType) =>)にする。errorTypeはerrorReasonTypeとisModeAを合成した結果を渡すことを想定している。これによって、この関数内の複雑性を減らすことができる。またCustomerErrorTypeはENUMなので、case 'CODE1':のようにリテラルべた書きを回避できるうえ、仕様変更などで値が変わった時にも対応がしやすくなる。
また戻り値の型も削除する。これは静的解析により自明であるほか、Omit<SomeFormInvalidInfo, 'invalidReason'>とあるが、実際に返しているのはinvalidReasonであり、関連性がないためだ(おそらく、偶々よく似た型を転用しているのだろう)。またこの事例では更にinvalidReasonという変数名があり、Omitの内容と視覚的に競合し、コードの読解が難しいため、この修正により可読性が増す。
また改修前はエラーメッセージオブジェクトのキーと、ヘルプページのキー名、そしてswitchのキーの全てが食い違っており、見ていて混乱する内容だったが、ヘルプページのURLをべた書きするように変えたため、混乱する要素を減らせている。
まとめ
コードの記述量を減らし、長大なコードを別々のファイルに分けることや、過度に分割しすぎないことによって可読性が向上し、コード量が減ったため保守コストも削減できたと考えている。
半面、静的解析のコストは上がっているが、静的解析のコスト増よりも可読性がよく、保守コストが低いコードのほうが効率的な開発に寄与するだろう。
また静的な値を取得するためにMapを使い、TypeScriptを利用しているため、理論上undefinedが返ってこないのに、それを期待するロジックを削除することで、コードを読んだ人が混乱する可能性も削減している。
型安全で見通しの良いエラーハンドリング
この項目ではエラーメッセージを返すサーバー側のエラーハンドリングについて記述する。
元コード
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
if (error.graphQLErrors[0]?.extensions?.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
...
}
if (error instanceof SomeError) {
...
}
...
}
このコードの問題点
- エラーハンドリングが長々とべた書きされていて見通しが悪い
- 配列の添え字が直に指定されているが意図が読み取れない
- 例外処理なのにOptional chainingが多く確実な例外処理に支障がある(例外処理で例外が発生するリスクは最小限にする必要がある)
extensions配下の型情報が暗黙的でわからないgraphQLErrors: ReadonlyArray<{ extensions: { [attributeName: string]: unknown; } }>
改善後コード
const handleApolloError = (err: ApolloError) => {
if (err instanceof ApolloError) {
// graphQLErrorsが空であれば例外をスローし、そうでなければgraphQLErrorsを返す
const gqlErrors = parseGQLErrors(err.graphQLErrors);
// graphQLErrorsの中身をパースし、意味のある型を付けて返す
const extensions = parseThisFunctionErrors(gqlErrors);
if (extensions.ERROR_KBN === 'ERR_XYZ') {
// エラー処理
} else if ...
}
}
try {
// API呼び出しなど
} catch (error) {
if (error instanceof ApolloError) {
handleApolloError(error);
} else if (error instanceof SomeError) {
...
}
...
}
べた書きされているとコードの見通しが悪いため、catch句の中では例外種別ごとにハンドリングする処理に飛ばし、そっちで処理できるようにする。
error.graphQLErrorsは要素が0の場合があるため、parseGQLErrors()のような共通関数を作り、要素があれば中身を返す、なければ例外をスローして、より上位の処理に飛ばすなどの処理を共通的に行うようにする。この仕組みを共通化することで、この要素に対する処理の一貫性を持たせることができる。
またgraphQLErrorsの詳細については処理によって内容が異なるであろうことから、ドメインごとにparseThisFunctionErrors()のような関数を作り、その中で適宜データを整形するのが望ましいだろう。
そうして結果的に意味のある型情報を持ったextensions、あるいは適当な結果情報をハンドリングすることで、型安全かつ、責務が別れ、疎結合な実装に寄与する。
この形式であればhandleApolloError()は必要に応じて別ファイルに切り出し単体テストを書くこともできるし、このままでもあっても規模が小さければ十分テスト可能だろう。
なお、parseGQLErrors()やparseThisFunctionErrors()の具体的な内容については今回は省略する。
2025/03/31(月)個人的に考えてるNext.jsのアーキテクチャ
更新日:
投稿日:
投稿日:
Next.jsの全体設計を考えるときに疎結合性やテスト容易性を達成するときに考えているアーキテクチャについて簡単に書いてみる。
Page Router向けに作っていて、API Routesについては考慮していない。過去にこれに近い設計で開発していたことがあったが、単体テストによるデグレードや不具合、仕様漏れの検出はよくできていたと思う。今回書いたものは過去に考案し、開発していたもののブラッシュアップになる。
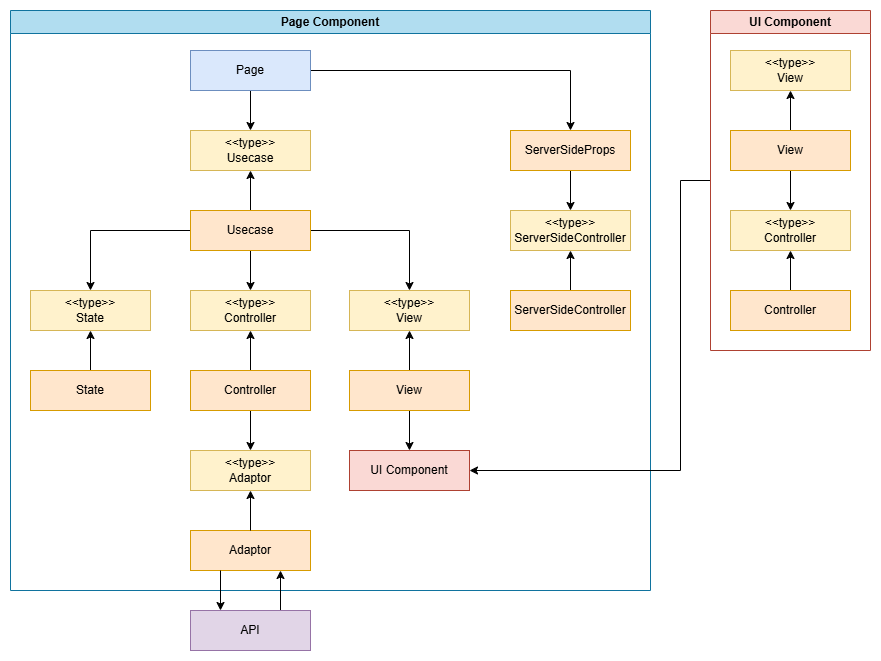
アーキテクチャ図
基本的に各レイヤー間はTypeScriptのtypeで仕切り、依存性を逆転させることで、テスト容易性や疎結合性を重視している。
ディレクトリ構成
アーキテクチャ図にないlibrariesが登場するが、これは汎用的な共通処理だ。
src
├─adaptors
│ └─User
│ ├─index.spec.ts
│ └─index.ts
├─components
│ └─form
│ └─TextInput
│ ├─index.spec.ts
│ └─index.ts
├─libraries
│ └─HttpClient
│ ├─index.spec.ts
│ └─index.ts
├─pages
│ └─hoge
│ ├─ServerSideProps.ts
│ ├─ServerSideController.spec.ts
│ ├─ServerSideController.ts
│ └─index.page.ts
└─usecaes
└─hoge
├─controller.spec.ts
├─controller.ts
├─state.spec.ts
├─state.ts
├─style.scss
├─usecase.tsx
├─view.spec.tsx
└─view.tsx
登場する各要素について
Page
画面本体。UsecaseとgetServerSidePropsを配置し、その橋渡しを行うだけの存在。
Usecase
StateとController、Viewを橋渡しする存在。
画面全体を別物にすり替える場合もここで行う。
useEffect()はここに書くが、中のロジックはController側に書く。
一見するとファサードであり、pageにべた書きしてもいいような内容だが、コードを書く時のコロケーションの観点から敢えて分離している。
また、画面のページレイアウトが全く別物になるなど劇的な変化がある場合は、この階層で分岐制御(ユースケース別の切り替え)する。
State
useState()で作った状態を定義する場所。それ以外は何もしない。
Controller
イベントハンドラによる処理を配置する場所。APIコールもここから行う。
状態については、typeを経由してState側で宣言した状態を注入して利用する。
状態を外部から注入するため、状態変化時のテストがしやすい。また画面からロジックをはがしているため、ロジック単体のテストが可能。
Adaptor
APIを呼ぶだけの存在。データの加工や例外ハンドリングは呼び元で行う。
APIを呼ぶだけの責務とすることで、複数のコンポーネントから呼ばれたときに同じAPIを呼ぶコードが重複したり、呼び出し元によってデータ加工手法を分けるなどの煩雑な実装を回避するのが目的。
テストとしては引数や戻り値、呼び出し方法が実装時から変わっていないかを見る観点のみあれば回帰テストとして機能する。
View
ほぼ純粋なJSXを書く場所。ロジックは原則として書かない。booleanを使ったDOMの切り替えは記述してよい。
制御はUsecaseでStateを合成したControllerで行う。
表示非表示の分岐のみにすることでtesting-libraryを利用したJSXの表示切替を単体テストとして実装できる。
UI Component
TextInputみたいな細かいパーツや、再利用されるフォームUIなど、UI系の共通部品。
基本的に状態は持たないが、無限ループが起きず、再利用されない状態(親に渡す必要がなく、自分自身に閉じた状態)については持ってよいと考えている。例えば、OK/CancelのあるモーダルでOKが押された時だけ呼び元に返す状態は持ってよい。
View, Controller
ページコンポーネント向けの内容に準ずる。Usecaseを持つほど大規模なコンポーネントはないと思うので、Usecaseなしで繋ぎ合わせてよいと考えている。
ServerSideProps
getServerSideProps()の中身。Page側では以下のようにして呼び出す想定。
import { execServerSideProps } from './ServerSideProps';
export const getServerSideProps = (async () => {
execServerSideProps();
});
ServerSideController
ServerSidePropsの中で利用するロジック。APIを呼ぶ場合はAdaptorとも繋がる。
利点
- 各レイヤーやコンポーネントでの単体テストが容易
- MVC的な構造のため理解しやすい
- SOLID原則で得られる利益を享受しやすい
- レビュー時に意図しないファイルに差分があった場合に、問題を検知できる
- コードマージ時のコンフリクト範囲を限定しやすい
欠点
- ボイラープレートコードが増える
- とはいえ、DDDよりは少ない
- Modelに相当するものがないため、ControllerがFatになる。またModel処理の共通化ができない
- Modelをどこに配置すべきかを検討できていない
- typeに破壊的変更が起きると数珠繋ぎに修正が必要になり、コストが重い
- その代わり型で各コンポーネントの関係性がわかる利点もある
あとがき
構想自体は4年前に考えたものだがアウトプットができていなかった。まだ煮詰まっていない上に考慮出来ていない部分もあるが、AppRouterの登場からだいぶ経ち、陳腐化してきそうだったので、取り敢えず吐き出した。