2025/08/06(水)AIを使った開発に取り組み始めてみた雑感
投稿日:
今までLLMを使う場合、文書校正や整理、ERP辺りが多かったが、そろそろコード作成にも必要だなと感じたので取り組んでみた結果の初回の雑感。
Claude Opus 4との直接対話
LLMエージェントを使わない、チャットインターフェースでの直接対話で行ってみたこと。これはClaude Opus 4で行っている。
簡単なボイラープレートやプログラムが関の山
正直、LLMとの単純な対話で作れるのは3カラムのハンバーガーメニュー付きのような画面のボイラープレートや、WebでJSを使った画像判定スクリプトあたりが関の山だと感じている。
それ以上のものも作れる可能性はあるが、要件定義とコードレビューが大変なので厳しい気がしている。
プログラムの変換は苦手
まず私はTampermonkeyで5分ごとにAPIをポーリングし、結果をパースして条件に応じてOSに通知トーストを出す、400行ほどのスクリプトを作っている。
そこで、このソースコードを丸っと渡して、C#.NETに変換してほしいと頼んでみたが、これは失敗した。根本的にビルドが通らないコードが出てきて多少の修正でどうにかなるレベルでもなく、全くダメだった。
ファイル構成もよくなく、ModelやControllerレベルではファイル分割されているものの、1ファイルの中に複数クラスが納められていたり、何ともな結果だった。
TSDocを書いているため、上手く推論できればInterfaceやClassも作れると思ったが、これは難しいようだった。
特定の設定方法を書くのは得意
OpenWrtの特定の設定を書かせることは得意だった。これはそのまま適用できた。やはりスコープが限定されているのが得意だと感じた。
Claude Codeを少しつついてみた感想
ファイル保存などの手間がいらなくなる
当たり前だがローカルマシン上に結果を出力するため、チャットインターフェースのように頑張ってファイルを保存したり、ディレクトリを切る必要は全くなくなる。
ボイラープレートの作成は得意
PHPを利用したMVC構成で簡単なブログをフルスクラッチで作ってほしいといえば、それらしい形のものは出してくれた。
動くかどうかは全く試していないが、大まかなスケルトンを作って貰って、そっからいじっていくベースとしては使えるような気がした。
やっぱりプログラムの変換は苦手
adiaryのテンプレートエンジン部分をPHPに書き換えてほしいと依頼してみたが、やはり動かないものが出てきた。adiaryの設計が極めて複雑でコンテキストが読み取りづらいのはあると思うが、やはりこの手の作業は苦手なようだ。
現状で見えてきたこと
そこまで大して使ったわけではないが、とりあえず所感として。
恐らく小規模でコンテキストの薄いコードを書かせるのが筋がよさそう。これは複雑な要件をLLMに伝えるのは難しいし、考えるのも大変なのと、コード変換も400行レベルでも厳しいと感じたからだ。
つまり、既存システムの移行は苦手なのではないかと思っている。なのでWordPressをGoで作り直すみたいなことは相当難しいと思う。逆にSOLID原則やClean Architectureのような、スコープが狭く責務が明確なものは作りやすいのではないかと感じた。
また仮にLLMが全て書いてくれるとしても、人がレビューしないとバグがあった時に当たりをつけるのが大変とか、知らない仕様が紛れ込んだりとかもあるため、LLMに書かせすぎるべきではなく、あくまで補助ツール程度に留めておくのが良いと考えている。
LLMの制約を味方にする開発術という記事を見た感じ、複雑なタスクを段階的に分解し、LLMの処理可能な単位に分解することが重要だと感じている。つまりこれは疎結合のほうが向いているということだ。また標準化されていて、属人性がないコードのほうが制約が少なくなるので、LLMもやりやすくなるだろう。これは標準化されておらず、属人性が高いコードは往々にしてカオスで、判断軸がなく、LLMの思考がぶれるからだと思われる。
結局どうしていくか
正直まだどう実用化していくかの展望は見えていない。
何はともあれ使い続けていくことが大切な気はしているので、個人的にはClaude Codeを使い続けていきたい。少なくとも面倒なボイラープレートを書く部分については非常に優秀なので、大まかに作らせて微調整するみたいな用途では間違いなく活路がある。こういうのは引き出しが多ければ多いほど活用できるだろうから、基礎を忘れないように自学していくことも引き続き重要で、LLMに教えてもらうのもいいだろう。適切に使えばLLMからは多くの学びを得られる。
2024/11/22(金)普段開発する時に考えていることを雑に書く
投稿日:
普段でWeb系のコードを書いているときに、こういうのがよいのではないか?と考えていることを雑に書いてゆく。いわゆるクラスを使わず関数を主体にして実装するなんちゃって関数型モデルみたいなやつの話。雑に書いているのでところどころ変なかもしれない。コードはNext.jsを題材にして書いている。
端的に言うとSOLIDを軸に、適切にDRY、KISS、YAGNIといった一般的な設計原則を織り込み、MVCのように役割分担のあるアーキテクチャを利用することや、実装方式を統一することを意識している。
実装方式の統一
実装方式、コーディングスタイルを統一することで、微妙な書き方の差異に起因する不具合や、レビュー時のコスト、新人が来たときの迷いを減らせる。恐らくこれこそが最も重要な設計原則だと思う。
例えば以下のコードは書き方は違うがやりたいことは似ている処理群だ。もしチームに新人が来た場合、新人はどちらを書けばよいだろうか?レビューの時に複数の実装パターンが混ざったときにレビュアーはどう対応すればいいだろうか?
// undefinedの判定方法の違い。よほど特殊なことをしているのでなければ、基本的に後者でいい
if (typeof hoge === 'undefined') { }
if (hoge === undefined) { }
// 関数の定義方法の違い。どちらかに統一するほうが望ましい
function func1(param: T) { }
const func1 = (param: T) => {}
// 仮引数の定義方法の違い。これは分割代入とそれ以外で致命的に振る舞いが変わることがあるので統一することが望ましい
const func2 = ({ hoge, piyo }: { hoge: string, piyo: number }) => {}
const func2 = (param: { hoge: string, piyo: number }) => {}
type Func2Param = {
hoge: string;
piyo: number;
}
const func2 = (param: Func2Param) => {}
何よりこれらの処理は同じような処理に見えて、微妙に振る舞いが変わるものがある。それを意識せずコードスタイルとして表現していた場合に不具合を引き起こすトリガーになりやすい。特に分割代入はオブジェクトの参照が切れるので予期せぬ動作になりやすいし、関数のスコープが長くなってきたときに由来が解りづらくなるケースがある。逆に分割代入をしないことによって変数名が冗長になることもある。
こういった問題を解決するために、コードの書き方をあらかじめチームで決めておくのがよい。特にチーム開発でコードの書き方に秩序がないプロジェクトは品質が低い傾向があると感じる。例えば車のタイヤを全て別のメーカーにしていても車は走行できるが、基本的にメーカーが違う場合、品質などの差異があるので、追々予期せぬ問題が発生する可能性がある。それと同じ問題がコードにもあると私は考えている。
他にも同じことがしたいのに複数の実装方法があるとgrepしづらかったり、直感的ではないなど、コードを読んだ人間の認知負荷の増大に繋がるため、基本的には統一されていたほうがよいだろう。
MVCのように役割分担のあるアーキテクチャ
私が普段考えているレイヤリングはMVCとClean Architectureを足して二で割ったようなものだ。DDDや厳密なClean Arctectureだと複雑で重くなりがちなので、このくらいが丁度いいのではないかと考えている。これでも十分複雑なのは承知している。
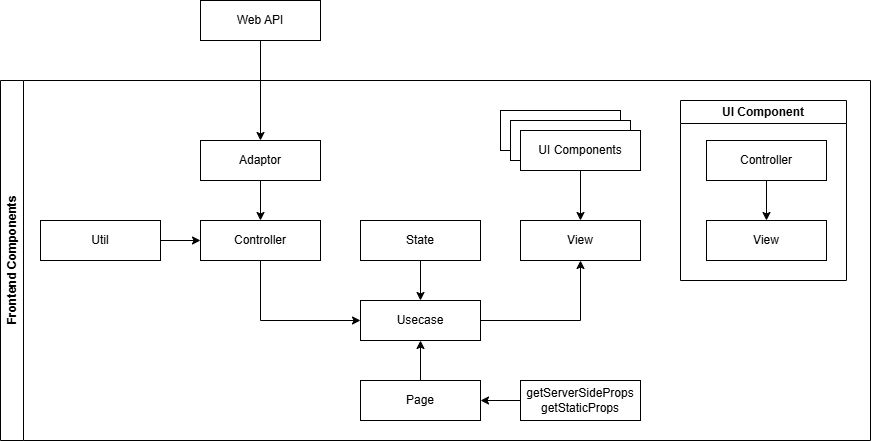
| コンポーネント | 役割 |
|---|---|
| Adaptor | APIコールなど、外部と接続するためのアダプタ関数。呼び出し処理以外を一切含まない。 ここでデータの操作や例外処理は行わず、必要な場合は呼び出しの前後で行う |
| Util | 全体的な共通処理や、画面単位の細かいロジック類 |
| Controller | 画面で利用するイベントコールバック処理。useEffect()みたいなのもここ |
| State | 画面で利用する状態 |
| View | 画面のビュー、ほぼ純粋なJSX/TSXで、booleanによる表示分岐のうち、単純なもののみ扱う。ネストしたり、複合条件を使った分岐は扱わず、必要に応じてUI Components側に移譲する |
| UI Components | 画面のビューで利用するUI部品、状態はすべてprops経由で受け取り、自身では持たない |
| Usecase | Pageコンポーネントに埋め込む存在。画面のController, State, Viewの繋ぎ合わせと、Pageコンポーネントから来たgetServerSideProps()やgetStaticProps()の結果を適切なコンポーネントに注入する |
| Page | ページコンポーネント。Usecaseコンポーネントの埋め込みとgetServerSideProps()やgetStaticProps()の呼び出しのみを行う。 |
| getServerSideProps getStaticProps |
getServerSideProps()やgetStaticProps()で処理するコードを書く |
SOLIDを意識する
リスコフの置換原則と、インターフェース分離の原則については、今回のケースでは無視でいいと思っている。
| 原則 | 効能 |
|---|---|
| 単一責任の原則 | 関数の実装を単一責務として切り出すことで、関数の肥大化を防げ、再利用性を高めることができるほか、単体テストが書きやすくなる |
| 開放閉鎖の原則 | 関数のインターフェースを抽象化し、不変のものとすることで仕様変更などの変化に対応しやすくなる |
| 依存性逆転の原則 | その関数に必要な依存性をインターフェース経由で注入することで、関数内の処理が関数本体に依存しなくなり、疎結合になるほか、注入する依存性をモックなどに変えることでテストが容易になる |
単一責任の原則
一つの関数には一つの責務だけを持たせようという原則だ。
一例としてReactでよくみられるreducerは以下のように書ける。これはreducerはaction.typeに応じた関数を呼び出すことを責務として、実際の処理は関数に移譲するといった内容だ。
const reducer = (state, action) => {
switch (action.type) {
case 'update_account':
updateAccountProc(state, action.payload);
break;
...
}
}
この実装であればreducer関数のテストは呼び出す関数をすべてモックしておき、action.typeに応じた関数が、想定通りの引数で呼ばれているかどうかを確認するだけでいい。各関数は関数単体でテストが書けるのでシンプルだ。
もしこれが関数呼び出しではなく、処理がベタで書いてあると単体の規模が大きくなり、コードの見通しが悪くなり、比例してテストコードも長くなり、個人的にはあまりよくないと思っている。コードの見通しは良いほうがよいし、責務ごとに関数を切ることでコードマージ時のコンフリクトの規模を抑えられることや、Feature flagを導入しやすくなるなど、利点は多いと思う。
欠点としては細切れになることによって、パッと見何をしているかわかりづらくなることがあると思うが、適切に抽象化し、関数名をちゃんとつけていれば基本的にそこは考慮しなくてよいと考えている。
開放閉鎖の原則
この原則は拡張に対しては開かれており、修正に対しては閉じられていないといけないということだ。
例えば以下のコンポーネントではUsernameという単語がAccountNameに代わったときにPropsを書き換える必要があるが、もしもuserNameというワードを使わずにonChangeやvalueといった抽象的な用語にしておけば、変更を不要にできる。
type Props = {
onUserNameChanged: (username: string) => void;
userName: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
props.onUserNameChanged(event.target.value);
};
return <input type="text" onChange={onChange} value={props.userName} />;
}
多くのライブラリやAPIではメソッド名やプロパティ名は汎用的な名称になっていることが多く、アップデートで名前が破壊されることはそこまで多くない。こういった風に実装しておくことで内部実装への影響なく処理ができるという寸法だ。
依存性逆転の原則
これは下位コンポーネントに実装を持たせず、上位コンポーネントから中小を介して実装を注入する原則だ。
例えば以下のような実装がある場合、「この辺りに長い色んな処理があるものとする」の部分を仕様変更などで書き換えないといけなくなることがある。
type Props = {
onChange: (value: string) => void;
value: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
/**
* この辺りに長い色んな処理があるものとする
*/
props.onChange(event.target.value);
/**
* この辺りに長い色んな処理があるものとする
*/
};
return <input type="text" onChange={onChange} value={props.value} />;
}
しかし、props.onChangeの中に前後の処理を挟んでいれば、これを回避することができるし、onChangeの中に処理がうじゃうじゃあるのも責務として過剰だと思うので、親からonChangeに対し何かしらの処理をすることが自明な関数を注入することで、こういった問題を回避できる。
DRYについて
この原則については、基本的に過度に意識する必要はなくシステム全体の共通部品以外は二重実装を許容して構わないと考えている。
これは余りにもDRYにしすぎると、仕様変更などで影響箇所が広がりすぎて修正が困難になるからというのと、共通部品が多すぎると探すのが大変で、最悪自力で実装されるケースもあるためだ。
KISSについて
程度問題ではあるが、DDDのような冗長で難解な設計原則は避け、ある程度単純なものにしたほうがいいというのは思っている。
べた書きをすることでコードジャンプが減って見通しがいいという意見は行き過ぎだと考えている。
YAGNIについて
これは技術選定フェーズで主に使うもので、何かの技術を入れるとき、その技術である必要がなければ使わないのがよいと考えている。
例えばWeb画面からAPIを叩くときにGraphQLを採用するケースがよくあると思うが、RESTやWebAPIで済むならそちらのほうがよい可能性がある。
GraphQLはWeb標準ではなく、ライブラリによって実装もまちまちで、複雑な仕組みが絡み合っており、全容を理解するのはなかなか難しいうえに、HTTPの上にあるため、使いこなすためには基礎の理解が必要だ。スキーマ設計も難しく、単純にやるとWebAPIと特に変わらないものができてしまう。そう考えたときに、絶対にGraphQLでないといけないというケースがないのであれば、より簡単な技術を使ったほうがよいと思っている。
複雑なものを作っている時間で休憩でもしたほうが頭がすっきりするだろう。
処理の境界を挟んだ時に影響が波及しないようにする
これはAPI通信など、外部から貰ってきたデータがあったときに、内部向けにデータ変換を行うということだ。
例えばAPIからisHoge, isPiyo, isFugaというデータが来るパターンがあり、この三つのフィールドはいずれか一つしかtrueにならないケースがあるとして、画面ではこれに対応するラジオボタンを持っている場合、trueだった項目を文字列として持っておくと便利だ。こういった場合に、使う場所で毎回変換処理を挟むと将来的に修正漏れが起きるリスクが増えたり、個々の場所で微妙に違う実装になって実装方式に統一がなくなったり。そもそも出現箇所が増えて認知負荷が増えるなど厄介だ。
これを防ぐために、一番最初にレスポンスを受けた時点で変換処理を挟み、以後それを引き回すというのがよいと考えている。APIに戻すときはisHoge, isPiyo, isFugaのフォーマットに戻す必要があるのが、その場合はAPIを叩く前に逆変換の処理を挟むと、データ変換処理が入り口と出口だけに存在することになり、データフローがシンプルになる。
他にもAPIと画面の境界でENUMの内容を変換する処理を入れておくとAPI側がしれっとリファクタなどで名称変更をしたときに、異常値を検出しやすくなるし、画面の開発者は基本的にAPIのことを考えなくてもよくなるので楽になると思っている(境界部分を設計する人間だけが考えればよくなる)
あとがき
雑に書こうとしたものの、結局まとまりきらず、まとめようとしても永遠に終わらなかったので一旦吐き出してみた。多分全部話そうとすると発散しすぎて収拾がつかなくなるので、個々について深ぼったことを書いて、最後にそれをまとめたほうがいいのかもしれない。
といっても何を書くかが問題になってくるので、日々思ったことを雑にアウトプットしつつ、あとで振り返ってまとめていくのがいいのかもしれない。
2022/01/10(月)Reactでより良い開発をするために意識したいこと
更新日:
投稿日:
投稿日:
別にReactに限った話でもないのですが、実務で悩ましいコードにあたって頭を抱えてる内にハゲてきたので、ハゲがこれ以上進まない事を祈り書きました。いやいっそのこと全ハゲになりたいですが、それはさておき
とりあえず個人的には以下2点を意識すれば起きないとは思うので、Next.jsを使った簡単なサンプルを交えながら3例ほどケーススタディ形式で紹介していきます
- 密結合にしない
- シンプルに実装する
挙げている事例については例示用にフルスクラッチで書いています(主題と関係ないコードは端折ってます
ここはこうした方がより良いのでは?などのご意見があれば是非コメントいただけると嬉しいです
コンポーネントのOptional引数のオーバーライド
コンポーネント引数をコンポーネント側で書き換えるような実装はどうかなと思います
問題点
- 親の預かり知らぬところで値が設定されている
- 誰かが知らずに設定値をすり替えたりしたら不具合が起きそうです
- 型のコメントと設定値が異なる
- 型のコメントと実装が異なるので、誰かが直すかもしれません
- すると、コンポーネントを参照している全コンポーネントに影響が波及します
- そもそも型と実装は本質的に関係ないので、こういった運用はNG
- 型のコメントと実装が異なるので、誰かが直すかもしれません
一例
type AccountContainerProps = {
email: string;
// デフォルトtrue
isUpdate?: boolean;
// デフォルトfalse
gotNotify?: boolean;
};
export const AccountContainer = ({
isUpdate = true,
gotNotify = true,
...props
}: AccountContainerProps) => {
...
}
改善案
呼び元で明示的に指定するように変更しています
これによって親は子の実装を知る必要がなくなり、責務がそこで閉じるようになりました
改善点
- 親の預かり知らぬところで値が設定されなくなった
- これで子コンポーネントで値が変わることに怯える必要はなくなりました
- 型の初期値コメントを削除できた
- 実装と一致する保証がないコメントは削除するべきでしょう
type AccountContainerProps = {
email: string;
isUpdate: boolean;
gotNotify: boolean;
};
export const AccountContainer = (props: AccountContainerProps) => {
...
}
コンポーネントのOptional引数の多重オーバーライド
コンポーネントのOptional引数のオーバーライドが多重化されている上に、なんか途中で更に書き換えられているとかいう地獄
どうしてそんなことをするのか…
一例
type AccountTemplateProps = {
email: string;
// デフォルトtrue
isUpdate?: boolean;
// デフォルトfalse
gotNotify?: boolean;
from: 'register' | 'update';
};
export const AccountTemplate = ({
isUpdate = false,
gotNotify = true,
...props
}: AccountTemplateProps) => {
if (props.from === 'register') isUpdate = false;
return <AccountContainer {...props} />;
};
type AccountContainerProps = {
email: string;
// デフォルトtrue
isUpdate?: boolean;
// デフォルトfalse
gotNotify?: boolean;
};
export const AccountContainer = ({
isUpdate = true,
gotNotify = true,
...props
}: AccountContainerProps) => {
...
}
改善案
前項のように明示的に値を渡してあげるようにしましょう
直列に分散されたコンポーネント
コンポーネントの中にコンポーネントがネストされ続けてるパターンです
一見して何をしているのか分かりづらい上、StateやらHookやら色んな処理が各コンポーネントに分散配置されていることもあります
問題点
- 親からみると子が何をしているのかが分かりづらい
- コンポーネント名が意味をなしていない(責務が別れていない)
- 子コンポーネントが状態を持っているため、親コンポーネントでハンドリングができない
- 子コンポーネントのロジック変更が参照している全コンポーネントのロジックに波及する
一例
親コンポーネント
RegisterHeaderなる物が差し込まれていることだけがわかります
このコンポーネントが何をするのかはパッと見ではよくわかりません
const AccountUpdatePage = () => {
return <Register header={<RegisterHeader />} />;
};
ラッピングしているコンポーネント
ラッパーなのでこのコンポーネントそのものは何をしているのかわかりません
type RegisterProps = {
header: JSX.Element;
};
export const Register = (props: RegisterProps) => {
return <>{props.header}</>;
};
差し込まれているコンポーネントの中身
どうやらRegisterHeaderはRegisterContentを含むようです
なんでヘッダーの中にコンテンツがあるのでしょうか…
export const RegisterHeader = () => {
return (
<>
<p>head</p>
<RegisterContent />
</>
);
};
差し込まれているコンポーネントの子
現在のパスに応じて叩くAPIを変えるような実装がされていますが、もしパスが変わったり増えたりしたらこのコンポーネントの実装を知らない限り面倒なことになります
export const RegisterContent = () => {
const rt = useRouter();
const currentPath = rt.pathname;
const url =
currentPath === 'register'
? 'https://example.com/kaiin/touroku'
: 'https://example.com/kaiin/koshin';
const [username, setUsername] = useState<string | undefined>(undefined);
const onSubmit = (ev: React.FormEvent<HTMLFormElement>) => {
ev.preventDefault();
axios.post(url, {
username,
});
};
return (
<>
<form onSubmit={onSubmit}>
<input
type="text"
value={username}
onChange={(ev) => setUsername(ev.target.value)}
/>
<button>送信</button>
</form>
<RegisterFooter />
</>
);
};
export const RegisterFooter = () => {
return <p>foot</p>;
};
改善案
改善点
- 親から子への見通しが改善された
- コンポーネント名が名前の通りの意味を持つようになった
- ヘッダーはヘッダー、フォームはフォーム、フッターはフッターの責務だけに集中できます
Registerとか言う謎コンポーネントも姿を消しました
- 状態をすべて親に集約した
- 子コンポーネントのロジック変更が起きる確率が減った
- 子コンポーネント側のロジックを減らし、親から渡されるコールバックで行うようにしたため、子コンポーネントのロジック変更が他に影響する確率が減りました
親コンポーネント
- ひとまずヘッダーと入力フォーム、フッターがあるんだなという事が解るようにはなったと思います
- 状態を親に集約したのでAPI叩く時のURIも態々パスから判断しなくて良くなったのでコードの複雑性が減っています
const usePageState = () => {
const [username, setUsername] = useState('');
return {
username,
setUsername,
};
};
const onSubmit = (username: string) => {
axios.post('https://example.com/kaiin/koshin', {
username,
});
};
const AccountUpdatePage = () => {
const ps = usePageState();
return (
<>
<RegisterHeader />
<RegisterForm
onChangeUsername={ps.setUsername}
username={ps.username}
onSubmit={() => onSubmit(ps.username)}
/>
<RegisterFooter />
</>
);
};
ヘッダー
export const RegisterHeader = () => {
return <p>head</p>;
};
入力フォーム
type RegisterFormProps = {
username: string;
onChangeUsername: (value: string) => void;
onSubmit: () => void;
};
const onChangeUsername = (
ev: React.ChangeEvent<HTMLInputElement>,
setState: (value: string) => void
) => {
const value = ev.target.value;
setState(value);
};
const onSubmit = (
ev: React.FormEvent<HTMLFormElement>,
onSubmit: () => void
) => {
ev.preventDefault();
onSubmit();
};
export const RegisterForm = (props: RegisterFormProps) => {
return (
<>
<form onSubmit={(ev) => onSubmit(ev, props.onSubmit)}>
<input
type="text"
value={props.username}
onChange={(ev) => onChangeUsername(ev, props.onChangeUsername)}
/>
<button>送信</button>
</form>
</>
);
};
フッター
export const RegisterFooter = () => {
return <p>foot</p>;
};