2025/02/27(木)Next.jsの設計に対する最近の考えを殴り書き
投稿日:
最近思っているNext.jsを使った画面設計に関する考えを箇条書きで雑に殴り書きしていく。この記事は考えの垂れ流しなので深い説明はしない。AppRouterではなく、PageRouterの考え。
- TypeScriptで実装し、型が騙せるような実装は極力避け、コードによる戻り値の型指定は不具合の原因になることがあるため、可能な限り型推論に任せる
- SOLIDな設計を意識することで疎結合でテストしやすい設計になる
- Clean Archtectureを意識することでSOLIDのSを意識しやすくなる
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
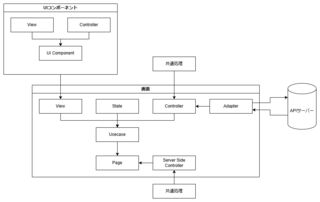
- ただこれはModelに相当するものがなく、ビジネスロジックの共通化に課題が出てくるのと、ControllerがFatになりすぎると考えており、そこが課題になると考えている。
- 画面として考える場合、実装レイヤーとしてはAPIを呼ぶ以外何もしないAdapter、ビジネスロジックやイベントハンドリングの実処理などを行うController、画面要素を配置しただけのView、画面状態を保持するState、それらをつなぎ合わせるUsecaseが、Usecaseを置くだけのPage(Next.jsのpageコンポーネントに埋め込むコンポーネント)、SSGやSSRをする場合のServer Side Controllerがあるとよいと考えている。大まかには下図のような感じで考えていて、過去の実務でもこれに相当するものを作ったことがある。
- テストが容易なコードは必然的に疎結合になる
- 疎結合にする場合、命名を抽象的にしておくと処理の入れ替えが容易になる(命名が具象、つまり実装の詳細に依存しないため)
- 疎結合にするとパーツが増えるので認知負荷が上がる
- 疎結合でかつ、命名が抽象化されている場合、仕様を知らない人にとっては実際の処理内容を推測しづらくなる
- つまりこれは属人性が増えると考える
- 例外についてはErrorクラスを継承し、カスタム例外を作成して、用途に応じたハンドリングができるようにする
- 原則として処理を止める場合にのみ用いるべきで、続行する場合には使わない
- 例外は原則としてスローして、カスタムエラーは特定の階層でフィルタしてハンドリング、全てすり抜けてきたものはルート処理でキャッチしてハンドリングすることで、取りこぼしをゼロにする。例外の握り潰しは原則行わない
- 基本的にすべてロギングする
- 処理を継続するものについては例外とせず、ワーニング用の処理フローを作成し、それに則って行う(例えば入力バリデーションはワーニング)
2024/12/02(月)単体テストを書くメリット
更新日:
投稿日:
投稿日:
単体テストは、コードの品質を向上させ、開発効率を高めるために欠かせないものだ。本記事では、単体テストを導入することで得られるメリットとその理由について解説する。
単体テストを書くことについて
単体テストを書くことには賛否両論あると思うが、私は書いたほうが良いと考えている。これは単にテストコードを書くことによってデグレが起きづらくなるからだけではなく、可読性の向上やコンフリクト頻度の減少など、様々な恩恵があるからだ。
この記事では、単体テストを書くことで得られるメリットについて書いていく。特に、関数を活用した開発(クラスを使わないスタイル)、TypeScriptでReactの関数コンポーネントを書くようなケースを前提に話を進める。
関数が小さくなる
単体テストの目的は、関数やクラスといった単位でその振る舞いを検証することだ。しかし、もし関数が1000行に及び、クロージャや分岐、ループが複雑にネストされていると、テストは非常に困難になる。つまり、これを回避しようとすると、自然と関数のサイズは小さくなり、責務が一つにまとまる設計となる。
関数が小さくなることでスコープが短くなり、見通しが良くなるほか、変数名を簡略化できる利点も生まれる。長すぎる変数名は基本的に有害だ。例えば以下のようなコードは誰も見たくないはずだ。(しかもよく見ると罠のようにも見えるコードだ)
const loooooooooooooooooooongVariableNameExtraResult = `${loooooooooooooooooooongVariableNameExtraParameter1} ${loooooooooooooooooooongVariableNameExtraParameter3} ${shortVar} ${loooooooooooooooooooongVariableNameExtraParameter2}`;
例えば、Go言語では一文字変数が一般的に受け入れられているが、これは関数のスコープが非常に短く、簡潔なコードが成立しやすい文化があるからだ。
疎結合な設計にしやすくなる
密結合なコードはテストがしづらい。そのため、単体テストを書こうとすると、自然と疎結合な設計になりやすくなる。具体的には、依存性逆転の原則に従った設計を採用するようになる。
例えば、次のようなコードはDate ()を直接使用しており、テストが困難だ。このような場合、Date ()をモックするために専用のライブラリやハックを使うことが多くなり、プログラムの保守性が悪化しがちだ。しかし、依存を外部から注入する設計にすれば、そういった心配は不要になる。
const isOneDayLater = (time: number) => {
return (+new Date() - time) > 86_400_000;
};
しかし、以下のように外部から値を注入すればモックしなくともテストコードを書くのが容易になる。第二引数に値を入れればいいからだ。
const isOneDayLater = (time: number, baseEpochTime: number) => {
return (baseEpochTime - time) > 86_400_000;
};
コンフリクトが起きづらくなる
Gitを利用した並行開発においてはブランチをマージするときにコンフリクト、つまりコードの競合が起きることがしばしばある。しかしこれまでに書いたように責務別にモジュール化された簡素なコードではコンフリクトの規模が自然に小さくなり、コンフリクト自体が減ったり、万一起きた時でも影響範囲が限定されるようになる。
コンフリクトの解消ミスがあり本番障害が出た、後続のQAフェーズなどで差し戻しが起きたみたいなのはよくある光景だと思うが、単体テストの導入による設計の改善があれば、それが起きた時のコストを減らすのに貢献することが可能だ。
コードの見通しが良くなる
適切に単体テストを意識してコードを書くと、自然と「べた書き」から「モジュール化」されたコードに変わる。
べた書きされたコードの例
例えば次のような関数は冗長だ。この程度の長さならまだしも、これが500行、1000行と増えていくと読むのが大変になる。現実ではもっとネストが酷かったり、前後に長大関数がいて、注意深く読まないと解読不能ということもままある。そしてこの関数をテストするのは書いてある処理すべてを検査する必要があるので、テストコードも長くなり、しんどい。
export const registerUser = async (user: User) => {
if (!/^\d+$/.test(user.id)) {
throw new Error('ユーザーIDの書式が不正です。');
}
if (user.firstName === '') {
throw new Error('姓が入力されていません。');
}
if (user.lastName === '') {
throw new Error('名が入力されていません。');
}
if (user.gender === '') {
throw new Error('性別が入力されていません。');
}
if (user.address === '') {
throw new Error('住所が入力されていません。');
}
const resp = await fetch('https://example.com/api/v1/user', {
method: 'POST',
body: JSON.stringify({
id: Number(user.id),
name: `${user.firstName} ${user.lastName}`,
gender:
user.gender === '0' ? 'male' : user.gender === '1' ? 'female' : 'other',
address: user.address,
}),
})
.then(async (resp) => await resp.json())
.catch((e) => e);
if (resp.status === 200) {
return resp;
} else {
const payl = resp.json();
return {
errorMessage: payl.errorMessage,
};
}
};
モジュール化されたコードの例
次のように書けば34行あった関数が9行にまで減り、見通しが良くなる。
export const registerUser = async (user: User) => {
validateUser(user);
const payload = createRegisterUserPayload(user);
const resp = await requestRegisterUser(payload);
return validateRegisterUserResponse(resp);
};
関数の中で何をしているかわからないという声もあるだろうが、関数名から内容を読み取れるようにしておけば問題にならない。読み取れない処理を入れなければいいのだ。こういう風にべた書きを一定の粒度で関数化することをモジュール化と呼ぶ。
この時、それぞれの関数(validateUser()など)は単一責務を持つため、単体テストのスコープが明確になる。親となる関数(この場合registerUser())のテストでは、子関数をモックすることで簡潔なテストが可能だ。この場合、親となる関数は子関数を呼び出すことが責務になる。
再テストの効率化
コードを直すことはよくあることで、コードを書いているときに一度書いたコードを直したり、レビュー指摘で直したりする。この時に、関係する部分を手動でテストするのは非効率だ。しかし、単体テストがあれば、その工数を大幅に削減できる。
特に分岐の網羅性が重要な場合、単体テストがあるとないとでは開発者の苦痛が大幅に変わるだろう。例えば、4つの分岐があるロジックでさえ、全数網羅では16パターンにも達するため、これを手動で見るのは手間である。しかしテストコードがあれば、自動テストを蹴るだけでいい。心理的負担も時間もこちらの方がローコストで現実的だ。
実装者が設計した時の意図がある程度読み取れる
コードを見ていて「こんなケースはないだろう」と思うことはしばしばあると思うが、そんな時にもしテストコードが存在すればケース名が書いてあるはずだ。それによって当時どのような意図で実装されたのかを知ることができる。これはコードの理解をより深く助ける手助けとなり、「負債に見えたから消したら不具合が出た」といったケースを減らすことに貢献することができる。
手動テストはなくならない
単体テストが充実していても、手動テストが完全になくなるわけではない。特に初回実装時は、プログラムが正しく動作するかどうかを確認する必要があるため、手動テストで動作確認を行い、その上で単体テストを信頼できる状態にするのが基本だ。
単体テストの限界と現実的な運用
さて、ここまで持ち上げてきた単体テストだが、決して銀の弾丸ではない。単体テストを入れてもバグを完全にゼロにすることは出来ないし、正しくないテストコードを書いたり、レビューが不十分であればテストが不正に通過する可能性もある。
正しくないテストコードを書かないための工夫としては、テストコードを書いた後に実装側を修正し、意図的にテストが落ちるようにしたときに、テストが落ちることを確認することが有用だ。これによって、実装が正しくない状態になったときにテストが正しく落ちることが確認できる。逆に落ちなかった場合、そのテストは機能していないと言える。
またテストを全数書くというのも非現実的であるため、TypeScriptの開発であれば型を騙すasのようなものは使わず、極力正しい型を検証できるように静的解析に任せるのが良い。戻り値の型指定も場合によっては型を騙すのに使えるケースがあるため、バグを生み出す元になる場合もあり、気を付けたほうが良い。
何より単体テストで見れるのは単体であり、結合は見れないため、あくまで単体テストはベースのロジックを担保するものとして使い、全体面は結合テストやe2eテスト、手動テストで見ていくのが良いだろう。
理想的には単体テストで網羅し、正常系と異常系のそれぞれ1パターンを結合で、初回実装時のみ手動テストというのがよいと考えている。これは結合テストで網羅ケースを書いてしまうと単体テストを書く意味がないうえに、重複テストが大量に発生し、実行速度が遅くなるし、規模が大きい分メンテナンスが大変になるからだ。
e2eテストは決済などのクリティカルケースにはあったほうが良いと思うが、コストの重さからしてそれ以外にはあまりなくてよいと思う。大抵のケースで手動の方が楽だろう。手動テストでは結果の誤りが出る可能性は残るが、些末な処理で100点を目指しても仕方がないので、多少の不具合は許容で良いのではないかと思う。
単体テストが有効に機能しづらいケース
単体テストは銀の弾丸ではないため、機能しないケースが当然ある。
元から単体テストがないプロジェクトに導入するケース
元々単体テストが導入されていないプロジェクトでは多くの困難を伴う。
例えば、関数やクラスがべた書きされており、責務が曖昧なまま複雑に絡み合っているコードでは、単体テストを書くこと自体が非常に難しい。分解しようにも目に見えている範囲だけを直せないケースも少なくない。これは他の機能がその機能と強く結合しており、根幹となる部分から直していかないと上手くいかないケースがあるからだ。
この状態の関数に対するテストを書いても、リファクタリングで分割された時の動作保証がやりづらい。何故ならこの手のものは大抵きれいに分割できず、再集計になるまでに紆余曲折をたどるからだ。
単体テストに対する理解が異なるケース
「単体テスト」の「単体の単位」が上手く認識されていない場合、本来あるべき単体テストの意義や役割が意識されていないことがある。これは結合テストやe2eテストが単体テストとして扱われているケースだ。
例えば画面の単体テストの定義が、実際に画面を操作し、APIをコールし、その結果に基づいた動作の確認だったり、複数の関数を呼び出す関数を単体として考えているケースでは、単体に対する意識が異なるため、本来あるべき単体テストの導入が難しいことがある。
有効な開発標準やコーディング規約が存在しないケース
有効な開発標準やコーディング規約がなく、コードの裁量がメンバー個々人に委ねられているケースでは、チームメンバーがそれぞれ独自のスタイルでコードを書いていることもあり、より問題を複雑化させることもある。
こういったケースではありとあらゆるコードが想定外の振る舞いをするため、単体テストの導入を阻む障壁となる。
破壊的変更が多いケース
これは要件や仕様などの上流部分が固まらず、日々変動するようなプロジェクトの話だ。
いつ仕様が固まるかわからないのでコードだけは書き続ける必要があり、日々変わるので動作確認もおろそかになる。このようなプロジェクトでは書いたコードが無価値化することが日常であるため、テストコードを書くという行為自体が陳腐化していきがちだ。
単体テストを書く文化がないケース
プロジェクトの方針として単体テストを書くことを推奨していなかったり、認めていない場所がある。こういった場所では、単体テストの重要性が理解されていないことも少なくなく、テストを書くことがむしろ「余計な作業」として扱われることがある。そういったシーンで単体テストを書くと、プロジェクト内で孤立するリスクがあり、難しい。
まとめ
単体テストを書くことで自然とSOLID的な設計に近づき、コードが読みやすくなり、ある程度変更に強く、開発速度も上がり、一定の品質も担保出来るため、単体テストを書くことによる恩恵は少なくない。これは間違いなくメリットだ。
しかし一方で、単体テストは銀の弾丸ではなく、密結合でテストしにくいコードや、頻繁に仕様変更が発生するプロジェクト、文化的に単体テストが認められていない環境では上手く機能しないケースもある。
2024/11/27(水)JSXの中に分岐埋め込みをしないほうがいい
投稿日:
例えば以下のようなコード(例示用のコードなので動作的な意味は特にない)
<>
{isHoge && obj?.payload?.username !== undefined && (
<div>新規:{obj.payload.username}</div>
)}
{isPiyo && obj?.payload?.username !== undefined && (
<div>更新:{obj.payload.username}</div>
)}
{isFuga && obj?.payload?.acceptTerm !== undefined && (
<div>退会:{obj.payload.acceptTerm}</div>
)}
</>
ifやswich文で分岐処理を書く場合はIntelliSenseで漏れが分かるが、JSXに埋め込んで書くと書き漏れがあった場合に気づきづらい。また上記程度ならまだいいと思うが、ネストされていたり、三項演算子を使った複雑な分岐があったりすると読みづらく、何が起きるのかわかりづらいし、テストも書きづらいので避けたほうが良いと感じる。
このような場合はifやswich文で分岐してJSXを返すコンポーネントを別に作り、それを埋め込んだ方が良いと思う。ページ用のtsxファイルの中にこの手のものが大量にいると、大変見通しが悪いと感じる。
そもそも上記の条件はisHoge, isPiyo, isFugaの関連性が分からないため、MECEでなく、条件分岐としてもよくない。
2024/11/27(水)原則として状態は親に持つ
投稿日:
Next.jsなどの画面をはじめとしたプログラミング設計において、状態管理は非常に重要な要素だ。特に、複雑なアプリケーションでは、状態がどこに存在するかがコードの可読性や保守性に大きな影響を与える。
基本的に状態は親にすべて望むのが望ましい。これは子が状態を持っている場合に、親がこれを利用することが困難だからだ。例えば以下のようなコンポーネント構造において、子コンポーネントAでAPIをコールし、その結果を持っているとする。仕様変更でこのデータを子コンポーネントBでも利用したいとなった場合、子コンポーネントAから状態を引きはがす必要があるが、実装によっては状態と実装が密結合になっており、特にスパゲッティ化しているコードでは容易に引きはがせないこともあるだろう。
親コンポーネント
├子コンポーネントA
└子コンポーネントB
しかし親であらかじめ状態を持っておけば、このような苦労は不要になる。子AでAPIをコールした結果を親で持っておけば、それをそのままBに引き渡せばいいだけだからだ。
これは信頼できる唯一の情報源にも通じる話で、情報源が分散していると誤って同じ状態を二つ持ってしまったり、実装が複雑化してしまうことがある。酷い場合では子コンポーネントAと親の両方でAPIをコールするような実装もあるだろう。APIコールのタイミングがずれることで期待した通りの結果が得られなかったり、通信が増えることでロードが増えUXを毀損したり、APサーバーの負荷が高まる懸念もある。
基本的に同じ責務を持つ実装はDRYであることが望ましいので、このような悲劇を生まないためにも状態は親で持っておくことが重要だと考える。
逆に責務の範囲に閉じることができるのであれば、子で持ってよいケースもある。例えば親画面から子画面を出すときに、子画面だけに状態をもっていたいケースがある。こういう場合には子に一時的な状態を持つのはありだろう。例えば以下のような保存ボタンを押したときにモーダルの内容を確定するようなものであれば、モーダル内の状態として持ってよい。これは親で使わないからだ。その代わり画面状態の初期化時は親から状態を渡してやり、保存ボタンを押したときはコールバックで通知するという構造だ。
type HogeModalProps = {
shown: boolean;
hoge: string;
onClose: () => void;
onApplyClose: (state: { hoge: string }) => void;
};
export const HogeModal = (props: HogeModalProps) => {
const [hoge, setHoge] = useState(props.hoge);
const shownStyle = props.shown ? { display: 'block' } : { display: 'hidden' };
const updateHoge = (ev: FormEvent<HTMLInputElement>) => {
setHoge(ev.currentTarget.value);
};
const closeWithApply = () => {
props.onApplyClose({ hoge });
};
return (
<dialog style={shownStyle}>
<input type="text" value={hoge} onInput={updateHoge} />
<button onClick={closeWithApply}>保存</button>
<button onClick={props.onClose}>キャンセル</button>
</dialog>
);
};
このようなケースでは、子の状態を親で管理すると煩雑になるため子に持たせておいた方が良い。
2024/11/22(金)普段開発する時に考えていることを雑に書く
投稿日:
普段でWeb系のコードを書いているときに、こういうのがよいのではないか?と考えていることを雑に書いてゆく。いわゆるクラスを使わず関数を主体にして実装するなんちゃって関数型モデルみたいなやつの話。雑に書いているのでところどころ変なかもしれない。コードはNext.jsを題材にして書いている。
端的に言うとSOLIDを軸に、適切にDRY、KISS、YAGNIといった一般的な設計原則を織り込み、MVCのように役割分担のあるアーキテクチャを利用することや、実装方式を統一することを意識している。
実装方式の統一
実装方式、コーディングスタイルを統一することで、微妙な書き方の差異に起因する不具合や、レビュー時のコスト、新人が来たときの迷いを減らせる。恐らくこれこそが最も重要な設計原則だと思う。
例えば以下のコードは書き方は違うがやりたいことは似ている処理群だ。もしチームに新人が来た場合、新人はどちらを書けばよいだろうか?レビューの時に複数の実装パターンが混ざったときにレビュアーはどう対応すればいいだろうか?
// undefinedの判定方法の違い。よほど特殊なことをしているのでなければ、基本的に後者でいい
if (typeof hoge === 'undefined') { }
if (hoge === undefined) { }
// 関数の定義方法の違い。どちらかに統一するほうが望ましい
function func1(param: T) { }
const func1 = (param: T) => {}
// 仮引数の定義方法の違い。これは分割代入とそれ以外で致命的に振る舞いが変わることがあるので統一することが望ましい
const func2 = ({ hoge, piyo }: { hoge: string, piyo: number }) => {}
const func2 = (param: { hoge: string, piyo: number }) => {}
type Func2Param = {
hoge: string;
piyo: number;
}
const func2 = (param: Func2Param) => {}
何よりこれらの処理は同じような処理に見えて、微妙に振る舞いが変わるものがある。それを意識せずコードスタイルとして表現していた場合に不具合を引き起こすトリガーになりやすい。特に分割代入はオブジェクトの参照が切れるので予期せぬ動作になりやすいし、関数のスコープが長くなってきたときに由来が解りづらくなるケースがある。逆に分割代入をしないことによって変数名が冗長になることもある。
こういった問題を解決するために、コードの書き方をあらかじめチームで決めておくのがよい。特にチーム開発でコードの書き方に秩序がないプロジェクトは品質が低い傾向があると感じる。例えば車のタイヤを全て別のメーカーにしていても車は走行できるが、基本的にメーカーが違う場合、品質などの差異があるので、追々予期せぬ問題が発生する可能性がある。それと同じ問題がコードにもあると私は考えている。
他にも同じことがしたいのに複数の実装方法があるとgrepしづらかったり、直感的ではないなど、コードを読んだ人間の認知負荷の増大に繋がるため、基本的には統一されていたほうがよいだろう。
MVCのように役割分担のあるアーキテクチャ
私が普段考えているレイヤリングはMVCとClean Architectureを足して二で割ったようなものだ。DDDや厳密なClean Arctectureだと複雑で重くなりがちなので、このくらいが丁度いいのではないかと考えている。これでも十分複雑なのは承知している。
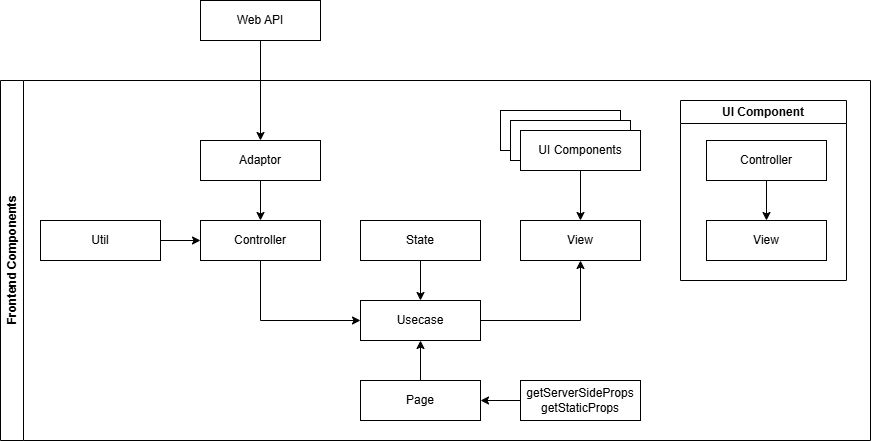
| コンポーネント | 役割 |
|---|---|
| Adaptor | APIコールなど、外部と接続するためのアダプタ関数。呼び出し処理以外を一切含まない。 ここでデータの操作や例外処理は行わず、必要な場合は呼び出しの前後で行う |
| Util | 全体的な共通処理や、画面単位の細かいロジック類 |
| Controller | 画面で利用するイベントコールバック処理。useEffect()みたいなのもここ |
| State | 画面で利用する状態 |
| View | 画面のビュー、ほぼ純粋なJSX/TSXで、booleanによる表示分岐のうち、単純なもののみ扱う。ネストしたり、複合条件を使った分岐は扱わず、必要に応じてUI Components側に移譲する |
| UI Components | 画面のビューで利用するUI部品、状態はすべてprops経由で受け取り、自身では持たない |
| Usecase | Pageコンポーネントに埋め込む存在。画面のController, State, Viewの繋ぎ合わせと、Pageコンポーネントから来たgetServerSideProps()やgetStaticProps()の結果を適切なコンポーネントに注入する |
| Page | ページコンポーネント。Usecaseコンポーネントの埋め込みとgetServerSideProps()やgetStaticProps()の呼び出しのみを行う。 |
| getServerSideProps getStaticProps |
getServerSideProps()やgetStaticProps()で処理するコードを書く |
SOLIDを意識する
リスコフの置換原則と、インターフェース分離の原則については、今回のケースでは無視でいいと思っている。
| 原則 | 効能 |
|---|---|
| 単一責任の原則 | 関数の実装を単一責務として切り出すことで、関数の肥大化を防げ、再利用性を高めることができるほか、単体テストが書きやすくなる |
| 開放閉鎖の原則 | 関数のインターフェースを抽象化し、不変のものとすることで仕様変更などの変化に対応しやすくなる |
| 依存性逆転の原則 | その関数に必要な依存性をインターフェース経由で注入することで、関数内の処理が関数本体に依存しなくなり、疎結合になるほか、注入する依存性をモックなどに変えることでテストが容易になる |
単一責任の原則
一つの関数には一つの責務だけを持たせようという原則だ。
一例としてReactでよくみられるreducerは以下のように書ける。これはreducerはaction.typeに応じた関数を呼び出すことを責務として、実際の処理は関数に移譲するといった内容だ。
const reducer = (state, action) => {
switch (action.type) {
case 'update_account':
updateAccountProc(state, action.payload);
break;
...
}
}
この実装であればreducer関数のテストは呼び出す関数をすべてモックしておき、action.typeに応じた関数が、想定通りの引数で呼ばれているかどうかを確認するだけでいい。各関数は関数単体でテストが書けるのでシンプルだ。
もしこれが関数呼び出しではなく、処理がベタで書いてあると単体の規模が大きくなり、コードの見通しが悪くなり、比例してテストコードも長くなり、個人的にはあまりよくないと思っている。コードの見通しは良いほうがよいし、責務ごとに関数を切ることでコードマージ時のコンフリクトの規模を抑えられることや、Feature flagを導入しやすくなるなど、利点は多いと思う。
欠点としては細切れになることによって、パッと見何をしているかわかりづらくなることがあると思うが、適切に抽象化し、関数名をちゃんとつけていれば基本的にそこは考慮しなくてよいと考えている。
開放閉鎖の原則
この原則は拡張に対しては開かれており、修正に対しては閉じられていないといけないということだ。
例えば以下のコンポーネントではUsernameという単語がAccountNameに代わったときにPropsを書き換える必要があるが、もしもuserNameというワードを使わずにonChangeやvalueといった抽象的な用語にしておけば、変更を不要にできる。
type Props = {
onUserNameChanged: (username: string) => void;
userName: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
props.onUserNameChanged(event.target.value);
};
return <input type="text" onChange={onChange} value={props.userName} />;
}
多くのライブラリやAPIではメソッド名やプロパティ名は汎用的な名称になっていることが多く、アップデートで名前が破壊されることはそこまで多くない。こういった風に実装しておくことで内部実装への影響なく処理ができるという寸法だ。
依存性逆転の原則
これは下位コンポーネントに実装を持たせず、上位コンポーネントから中小を介して実装を注入する原則だ。
例えば以下のような実装がある場合、「この辺りに長い色んな処理があるものとする」の部分を仕様変更などで書き換えないといけなくなることがある。
type Props = {
onChange: (value: string) => void;
value: string;
}
export const UserNameInputField = (props: Props) => {
const onChange = (event: React.ChangeEvent<HTMLInputElement>) => {
/**
* この辺りに長い色んな処理があるものとする
*/
props.onChange(event.target.value);
/**
* この辺りに長い色んな処理があるものとする
*/
};
return <input type="text" onChange={onChange} value={props.value} />;
}
しかし、props.onChangeの中に前後の処理を挟んでいれば、これを回避することができるし、onChangeの中に処理がうじゃうじゃあるのも責務として過剰だと思うので、親からonChangeに対し何かしらの処理をすることが自明な関数を注入することで、こういった問題を回避できる。
DRYについて
この原則については、基本的に過度に意識する必要はなくシステム全体の共通部品以外は二重実装を許容して構わないと考えている。
これは余りにもDRYにしすぎると、仕様変更などで影響箇所が広がりすぎて修正が困難になるからというのと、共通部品が多すぎると探すのが大変で、最悪自力で実装されるケースもあるためだ。
KISSについて
程度問題ではあるが、DDDのような冗長で難解な設計原則は避け、ある程度単純なものにしたほうがいいというのは思っている。
べた書きをすることでコードジャンプが減って見通しがいいという意見は行き過ぎだと考えている。
YAGNIについて
これは技術選定フェーズで主に使うもので、何かの技術を入れるとき、その技術である必要がなければ使わないのがよいと考えている。
例えばWeb画面からAPIを叩くときにGraphQLを採用するケースがよくあると思うが、RESTやWebAPIで済むならそちらのほうがよい可能性がある。
GraphQLはWeb標準ではなく、ライブラリによって実装もまちまちで、複雑な仕組みが絡み合っており、全容を理解するのはなかなか難しいうえに、HTTPの上にあるため、使いこなすためには基礎の理解が必要だ。スキーマ設計も難しく、単純にやるとWebAPIと特に変わらないものができてしまう。そう考えたときに、絶対にGraphQLでないといけないというケースがないのであれば、より簡単な技術を使ったほうがよいと思っている。
複雑なものを作っている時間で休憩でもしたほうが頭がすっきりするだろう。
処理の境界を挟んだ時に影響が波及しないようにする
これはAPI通信など、外部から貰ってきたデータがあったときに、内部向けにデータ変換を行うということだ。
例えばAPIからisHoge, isPiyo, isFugaというデータが来るパターンがあり、この三つのフィールドはいずれか一つしかtrueにならないケースがあるとして、画面ではこれに対応するラジオボタンを持っている場合、trueだった項目を文字列として持っておくと便利だ。こういった場合に、使う場所で毎回変換処理を挟むと将来的に修正漏れが起きるリスクが増えたり、個々の場所で微妙に違う実装になって実装方式に統一がなくなったり。そもそも出現箇所が増えて認知負荷が増えるなど厄介だ。
これを防ぐために、一番最初にレスポンスを受けた時点で変換処理を挟み、以後それを引き回すというのがよいと考えている。APIに戻すときはisHoge, isPiyo, isFugaのフォーマットに戻す必要があるのが、その場合はAPIを叩く前に逆変換の処理を挟むと、データ変換処理が入り口と出口だけに存在することになり、データフローがシンプルになる。
他にもAPIと画面の境界でENUMの内容を変換する処理を入れておくとAPI側がしれっとリファクタなどで名称変更をしたときに、異常値を検出しやすくなるし、画面の開発者は基本的にAPIのことを考えなくてもよくなるので楽になると思っている(境界部分を設計する人間だけが考えればよくなる)
あとがき
雑に書こうとしたものの、結局まとまりきらず、まとめようとしても永遠に終わらなかったので一旦吐き出してみた。多分全部話そうとすると発散しすぎて収拾がつかなくなるので、個々について深ぼったことを書いて、最後にそれをまとめたほうがいいのかもしれない。
といっても何を書くかが問題になってくるので、日々思ったことを雑にアウトプットしつつ、あとで振り返ってまとめていくのがいいのかもしれない。