更新日:2026/07/14 投稿日:2026/07/13
令和の時代にPerlでCGI…?という感じだが、PHP-FPMの上で動いてるLaravelとかもCGIの親戚みたいなものなので、そこまで違和感はないと思う。何せFPMはFastCGI Process Manager の略だからね。
でも令和の時代にPerl…?というのは、ちょっと面白いと思っている。
Env
Ver
Perl
v5.38.2
fcgiwrap
1.1.0-14build1
nginx
1.24.0
この設定ではドメイン直下のどこにアクセスされてもファイルがなければindex.cgiに飛ばしてCGIにルーティングを処理させるようにしている。
パスごとにCGIファイルを配置する方式ならtry_filesは不要だ。
server {
listen [::]:443 ssl;
server_name example.com;
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
root /var/www;
location / {
index index.cgi;
try_files $uri $uri/ /index.cgi;
}
location ~ ^.+\.cgi$ {
fastcgi_pass unix:/var/run/fcgiwrap.socket;
fastcgi_index index.cgi;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param HTTPS on;
fastcgi_param SERVER_PORT 443;
}
}
Hello worldを出すだけの奴。レスポンスヘッダを書かないとnginxではエラーになった。Apacheでは試していない。
#!/bin/env perl
# HTTPメッセージに近い構造になっている
# レスポンスヘッダを書いている
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
# レスポンスボディ
print 'Hello world';
これをindex.cgiとかで置いてやって所有者をwww-data:www-dataにして実行権限を付与したら動く。
sudo chown www-data:www-data index.cgi
sudo chmod u+x index.cgi
ファイルの先頭に以下の二行を加えると、実行時エラーをサーバーログに吐き出すようになる。
use strict;
use warnings;
#!/bin/env perl
use strict;
use warnings;
# HTTPメッセージに近い構造になっている
# レスポンスヘッダを書いている
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
# レスポンスボディ
print 'Hello world';
#!/bin/env perl
use strict;
use warnings;
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
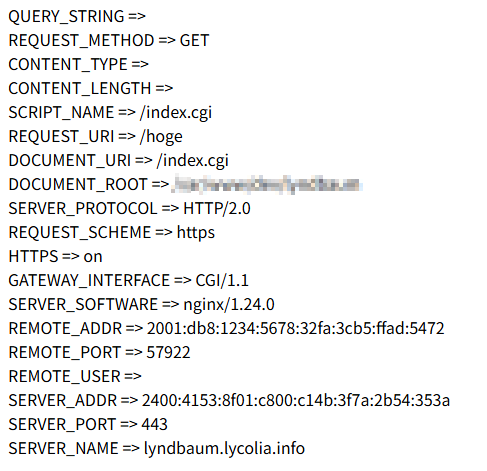
print "QUERY_STRING => $ENV{QUERY_STRING}<br>";
print "REQUEST_METHOD => $ENV{REQUEST_METHOD}<br>";
print "CONTENT_TYPE => $ENV{CONTENT_TYPE}<br>";
print "CONTENT_LENGTH => $ENV{CONTENT_LENGTH}<br>";
print "SCRIPT_NAME => $ENV{SCRIPT_NAME}<br>";
print "REQUEST_URI => $ENV{REQUEST_URI}<br>";
print "DOCUMENT_URI => $ENV{DOCUMENT_URI}<br>";
print "DOCUMENT_ROOT => $ENV{DOCUMENT_ROOT}<br>";
print "SERVER_PROTOCOL => $ENV{SERVER_PROTOCOL}<br>";
print "REQUEST_SCHEME => $ENV{REQUEST_SCHEME}<br>";
print "HTTPS => $ENV{HTTPS}<br>";
print "GATEWAY_INTERFACE => $ENV{GATEWAY_INTERFACE}<br>";
print "SERVER_SOFTWARE => $ENV{SERVER_SOFTWARE}<br>";
print "REMOTE_ADDR => $ENV{REMOTE_ADDR}<br>";
print "REMOTE_PORT => $ENV{REMOTE_PORT}<br>";
print "REMOTE_USER => $ENV{REMOTE_USER}<br>";
print "SERVER_ADDR => $ENV{SERVER_ADDR}<br>";
print "SERVER_PORT => $ENV{SERVER_PORT}<br>";
print "SERVER_NAME => $ENV{SERVER_NAME}<br>";
lib/Lyndbaum/Core.pmに次のライブラリを作成したとする。
パス名とpackage名の大文字小文字が一致してないと動かないので注意。
use strict;
use warnings;
package Lyndbaum::Core;
sub getEnv() {
return (
QUERY_STRING => $ENV{QUERY_STRING},
REQUEST_METHOD => $ENV{REQUEST_METHOD},
CONTENT_TYPE => $ENV{CONTENT_TYPE},
CONTENT_LENGTH => $ENV{CONTENT_LENGTH},
SCRIPT_NAME => $ENV{SCRIPT_NAME},
REQUEST_URI => $ENV{REQUEST_URI},
DOCUMENT_URI => $ENV{DOCUMENT_URI},
DOCUMENT_ROOT => $ENV{DOCUMENT_ROOT},
SERVER_PROTOCOL => $ENV{SERVER_PROTOCOL},
REQUEST_SCHEME => $ENV{REQUEST_SCHEME},
HTTPS => $ENV{HTTPS},
GATEWAY_INTERFACE => $ENV{GATEWAY_INTERFACE},
SERVER_SOFTWARE => $ENV{SERVER_SOFTWARE},
REMOTE_ADDR => $ENV{REMOTE_ADDR},
REMOTE_PORT => $ENV{REMOTE_PORT},
REMOTE_USER => $ENV{REMOTE_USER},
SERVER_ADDR => $ENV{SERVER_ADDR},
SERVER_PORT => $ENV{SERVER_PORT},
SERVER_NAME => $ENV{SERVER_NAME}
);
}
1;
#!/bin/env perl
use strict;
use warnings;
# @INCはライブラリをインクルードするパスを指定するための組み込み変数で
# unshiftは配列に要素を追加する関数
# つまりインクルードパスに./libを追加している
unshift(@INC, './lib');
# 読み込んだライブラリの使用
use Lyndbaum::Core;
# %で始まる変数は連想配列(ハッシュ)として機能する
my %e = Lyndbaum::Core::getEnv();
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
# ハッシュは$変数名{キー名}で参照できる
print "REQUEST_SCHEME: $e{REQUEST_SCHEME}<br>";
print "HTTPS: $e{HTTPS}<br>";
print "HOST: $e{HOST}<br>";
print "SERVER_NAME: $e{SERVER_NAME}<br>";
print "REQUEST_URI: $e{REQUEST_URI}<br>";
print "DOCUMENT_URI: $e{DOCUMENT_URI}<br>";
print "SCRIPT_NAME: $e{SCRIPT_NAME}<br>";
unshift(@INC, './lib');はuse lib './lib';の元の構文みたいなもの らしい。adiaryの実装がこうだったので真似してみたが、バッドプラクティスの可能性がある。
#!/bin/env perl
use strict;
use warnings;
unshift(@INC, './lib');
use Lyndbaum::Core;
my %e = Lyndbaum::Core::getEnv();
# Status: <コード>でレスポンスステータスコードを返せる
# 指定しないと200になった
print "Status: 200\r\n";
# 好きなサーバー名を書いて君だけのサーバーを名乗ろう!
print "Server: Lyndbaum\r\n";
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
# レスポンスボディ
print "REQUEST_SCHEME: $e{REQUEST_SCHEME}<br>";
print "HTTPS: $e{HTTPS}<br>";
print "HOST: $e{HOST}<br>";
print "SERVER_NAME: $e{SERVER_NAME}<br>";
print "REQUEST_URI: $e{REQUEST_URI}<br>";
print "DOCUMENT_URI: $e{DOCUMENT_URI}<br>";
print "SCRIPT_NAME: $e{SCRIPT_NAME}<br>";
パスが取れるのでもう朝飯前。
#!/bin/env perl
use strict;
use warnings;
unshift(@INC, './lib');
use Lyndbaum::Core;
my %e = Lyndbaum::Core::getEnv();
print "Status: 200\r\n";
print "Server: Lyndbaum\r\n";
print "Content-Type: text/html; charset=UTF-8\r\n\r\n";
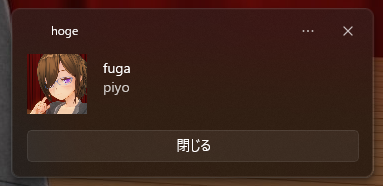
if ($e{REQUEST_URI} eq '/hoge') {
# 文字列比較はeqなので注意、シェルスクリプトと同じ!!
print "hoge!!";
} else {
print "REQUEST_SCHEME: $e{REQUEST_SCHEME}<br>";
print "HTTPS: $e{HTTPS}<br>";
print "HOST: $e{HOST}<br>";
print "SERVER_NAME: $e{SERVER_NAME}<br>";
print "REQUEST_URI: $e{REQUEST_URI}<br>";
print "DOCUMENT_URI: $e{DOCUMENT_URI}<br>";
print "SCRIPT_NAME: $e{SCRIPT_NAME}<br>";
}
何故Perlかというところだが、単にCGIとして実装したかったからだ。PHPやRuby, Pythonなどの選択肢もあると思うが、私はPythonが好きではなく、Rubyには興味がなく、最近のPHPもあまり好きではない。そこでPerlにすることにした。
PerlはPHPと比べたときに破壊的変更が少なく、枯れており、構文を覚えればワンライナーや簡単なスクリプトを書くのも便利だ。他にも構文が柔軟な部分も素晴らしい。
例えばPHPであれば以下のようにエスケープが必要なコードは
$hoge = '"/hoge/\'fuga\'/piyo/"';
if (preg_match("/(\/'fuga'\/)/", $hoge, $mat) === 1) {
echo $mat[1];
}
Perlではこう書ける。
$hoge = qq("/hoge/'fuga'/piyo/");
if ($hoge =~ m|(/'fuga'/)|) {
print $1;
}
qq()のqはquoteを指し、quoteが二つあるのでダブルクォートを指し示す。この演算子を使うことでPerlでは文字のエスケープを減らすことができ、書きやすさと可読性を保ちやすくなる。qq<>とかqq{}みたいに任意の記号を使うことができる ので、文字列の中に(出たら終わりじゃんみたいなこともない。大変柔軟性がある。
$hoge =~ m|(/'fuga'/)|の=~は正規表現の比較に使う演算子だが、ついでにキャプチャもしてくれる。更にm||のように書くことで正規表現内に/が含まれていてもエスケープ不要になる。qq同様に使う記号は好きに変えられる。
反面でPerl特有の演算子でもあるため、Perlが分からない人には暗号にしか見えないのは欠点と言えるだろう。
またPerlにはNode.jsの面倒さのようなものもない。例えばNode.jsならパッケージマネージャーをnpm, yarn, pnpmなどのどれにするかとか、実行環境をDeno, Bun, Node.jsなどのどれにするかとか、バージョン管理をVolta, nodenv, nvmなどのどれにするかとか、様々な争いがあると思うが、Perlにはそんなものはないと思う。
それに、このブログで利用しているadiaryはPerl CGIで実装されているし、lycolia.info 配下のページも実は全部Perl CGIとして実装している[1] ソフトウェア配布 に置いてるのも現状Perl実装だしね。