検索条件
タグで絞り込み
ジャンル(4)
ジャンル::ガジェット(1)
ジャンル::ベンチマーク(3)
ジャンル::自作PC(3)
地域(1)
地域::兵庫県(1)
地域::兵庫県::摂津(1)
地域::兵庫県::摂津::神戸市(1)
技術(1)
技術::LLM(1)
全6件
(1/2ページ)
AUTOMATIC1111の更新は長らく止まっており、新しいツールを探していてComfyUIを試したりしていたのだが、Hire fixに相当する機能に当たることが出来ず、どうにもイマイチだった。
そこでかつてAUTOMATIC1111からフォークされ、AUTOMATIC1111にマージされたForgeからreForgeが新たに派生していることを知ったので試してみたが、これがかなり良かった。生成速度は爆速になったし、複数キャラの絡みも自然にできるようになった。
reForgeは既に開発が停止しているようだが、逆に言えば安定していると言う事でもある。
というわけで試した結果をつづっていく。
git pullしたらwebui.bat叩いて終わりなので特筆することはない。AUTOMATIC1111とディレクトリ構造が同じなので、extentionやmodel, loraなどの環境はそのまま引っ越せる。
前回のベンチマークでは平均生成速度2.911it/s、生成時間120秒だったが、今回は平均生成速度4.352it/s、生成速度81秒まで短縮された。
これは前回最速を記録したUltra 7 265F + 4070Tiを12秒も凌ぐ速度で、極めて速い。正直コスパでNovelAIと勝負できるレベルだ。
ソフトウェア
reForegeにxformersは不要とのことで、xformersを入れていない。
| Env | Ver |
|---|---|
| version | f1.0.0v2-v1.10.1RC-latest-2446-ge1dcf9b4 |
| python | 3.11.9 |
| torch | 2.7.1+cu128 |
| xformers | N/A |
| gradio | 3.41.2 |
ハードウェア
前回とマザボが変わっているが、これによる差はないだろう。
| デバイス | 製品 |
|---|---|
| CPU | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 5070 Ti |
| MEM | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASRock Z890 Pro RS |
コマンドライン引数なしでwebui.batを実行
| 設定 | 値 |
|---|---|
| Model | ntrMIXIllustriousXL_xiii.safetensors [1207404b17] |
| Clip skip | 2 |
| ENSD | 31337 |
| Propmpt | (illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), {{shot_hair}}, smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, {{purple eyes}}, gray {{jacket}}, white shirt, glasses, {{small breasts}}, |
| Negative Prompt | nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind |
| VAE | Automatic |
| Sampleing method | DPM++ 2M |
| Hires. fix | True |
| Upscaler | Latent |
| Hires steps | 0 |
| Denoising strength | 0.8 |
| Upscale by | 2 |
| Sampleing steps | 20 |
| Width | 768px |
| Height | 768px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | -1 |
20/20 [00:02<00:00, 6.90it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 6.96it/s]
20/20 [00:11<00:00, 1.71it/s]
20/20 [00:02<00:00, 7.06it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 7.14it/s]
20/20 [00:11<00:00, 1.70it/s]
20/20 [00:02<00:00, 6.98it/s]
20/20 [00:11<00:00, 1.67it/s]
200/200 [01:21<00:00, 2.46it/s]
200/200 [01:21<00:00, 1.66it/s]
前回のベンチマークでは平均生成速度2.911it/s、生成時間120秒だったが、今回は平均生成速度4.352it/s、生成速度81秒まで短縮された。
平均生成速度
4.352it/s (前回比 +1.441it/s)
生成時間
81秒 (前回比 -39秒)
まとめ
明らかに爆速になった。これだけ早ければ何の文句もない。総合点でNovelAIと勝負できるレベルといっても過言ではないだろう。
Forge CoupleというExtentionsが出ており、これを使うと複数キャラをNovelAI並みの自然さで配置できる。安定性ではNovelAIには敵わないのだが、無料で勝負できるところに価値がある。これがあればもうRegional Prompterは窓から投げ捨てていい。

Forge Coupleを使えばこのレベルは朝飯前だ。因みにこれはサンプルプロンプトそのままに近いが、キャラ同士の絡みも実現できる。
例えば、以下の条件であれば、ふたなりアスナと直葉の断面図あり挿入シーンという難題さえこなして見せる。かなりドギツイのが出てくるので試したい人はプロンプトをよく確認してほしい。かなり地獄のようなワードが入りすぎている。
nsfw, hentai illust, {num: 2girls}, 1dickgirls and 1girls, wet hair, drool,wet and messy, {cup: asuna to suguha}, very aesthetic, masterpiece, no text, from side, female sex, female sex from behind, female only
{num}, {cup}, couple, girl, kirigaya suguha, sao, large breast, large areola, white skin, (bob cut), armpit hair, pubic hair, doggy style, x-ray, creampie, ahegao, full body
{num}, {cup}, couple, dick girl, asuna (sao), A adult tall beauty crossdresser,shemale, little breasts, sagging breats, (dark nipple), little long nipples,wetty hair, hentai anime , long gloves and high socks, enjoying,smile,heart eyes, erection foreskin dick,smegma, armpit hair, pubic hair, hairy, tatoo,normal dick, sex, cum in cevio, ahegao, full body,
Negative prompt: lowres, artistic error, film grain, scan artifacts, worst quality, bad quality, jpeg artifacts, very displeasing, chromatic aberration, dithering, halftone, screentone, multiple views, logo, too many watermarks, negative space, blank page, low quality, child, text, speaking, censored. male, boy, male sex, 1boy
Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 6, Seed: 1605499267, Size: 768x512, Model hash: c3688ee04c, Model: waiNSFWIllustrious_v110, Denoising strength: 0.85, Clip skip: 2, Hires CFG Scale: 6, Hires upscale: 2, Hires upscaler: Latent, forge_couple: True, forge_couple_compatibility: False, forge_couple_mode: Advanced, forge_couple_separator: \n, forge_couple_mapping: "[[0, 1, 0, 1, 1], [0, 0.5, 0, 1, 1], [0.5, 1, 0, 1, 1]]", forge_couple_common_parser: { }, Pad conds: True, Version: f1.0.0v2-v1.10.1RC-latest-2446-ge1dcf9b4
ポイントは一行目のfrom side, female sex, female sex from behind, female onlyと、2~3行目のキャラクター設定行にある{num}, {cup}, couple,だ。
まずfrom sideのように構図を指定していないと破綻しやすい。NovelAIのようにいい感じにはしてくれない。
次にふたなり百合をする場合、female sex, female sex from behind, female only辺りがあると良い。男が出てくる確率が目に見えて減る。
キャラクター設定についても{num}, {cup}で一行目の変数を参照し、プレイスタイルや人物属性の設定を強めることで出現率が大幅に向上する。またcoupleを付けることで、二人が出てくる確率が上がる。これがないと一人しか出てこなかったり、男が出てくる確率が増える。

この様なノイズ画像が生成される時に「Number of Couples and Masks mismatched」というエラーが出ている場合、余計な空行が入っているのが原因なので、それを消すと直る。
Empty lines are still counted; ensure you do not leave an empty line at the end;
久々にPC構成を大刷新してみたのでベンチマークをしてみたが、かなり複雑な結果になった。
大まかにはCore Ultra 7 265FはCore i7 13700に、RTX 5070 TiはRTX 4070 Tiに劣るケースがありそうなことが判明したが、結果が複雑すぎて断言しづらい。
ソフトウェア
| Env | Ver |
|---|---|
| version | v1.10.1-89-g2174ce5a |
| python | 3.10.6 |
| torch | 2.7.0+cu128 |
| xformers | 0.0.30 |
| gradio | 3.41.2 |
ハードウェア
スペックアップ前後で単純に計測したところ、結果に疑問を持ったのでCPUとGPUを新旧それぞれで組み合わせて全数網羅で見ている。
| デバイス | 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|---|
| CPU | Intel Core i7 13700 | Intel Core i7 13700 | Intel Core Ultra 7 265F | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti |
| MEM | Crucial Ballistix BL2K16G32C16U4B * 4 | Crucial Ballistix BL2K16G32C16U4B * 4 | Crucial CT2K16G56C46U5 * 4 | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASUS TUF GAMING Z790-PLUS D4 | ASUS TUF GAMING Z790-PLUS D4 | ASUS TUF GAMING Z890-PLUS WIFI | ASUS TUF GAMING Z890-PLUS WIFI |
4070Tiより5070Tiの方がベンチスコアが若干高く出るが、Core i7 13700よりCore Ultra 7 265Fの方が顕著にスコアが低い。
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 27,439 | 29,138 | 22,393 | 23,479 |
おまけ:ローディングタイム
構成1-2は記録し忘れたので書いていない。
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 6.5秒 | - | 7.9秒 | 8.6秒 |
ローディングタイムはストレージ依存のはずなのでCPUやGPUの性能が大きく影響することはないはずだが、かなり差が出ていたので参考程度にとどめておく。結果は小数第二位で四捨五入している。
CPUのキャッシュメモリサイズやDDR5の4枚差しによる速度低下が影響している可能性もあるが、2-1と2-2はGPUのみの差なのでよくわかっていない。ひょっとしたらグラフィック自体の読み込み速度が低下しているのかもしれない。
この差はMMORPGをする上ではかなりのハンデになるため、私が現役プレイヤーであれば、このスペックダウンは受け入れられなかっただろう。特にFF14をしていた時は誰よりも早くローディングを終えるのが自慢の一つだった。
ベンチマーク用のSD設定
COMMANDLINE_ARGSは--xformers --opt-channelslast --medvramを使用。
| 設定 | 値 |
|---|---|
| Model | animagine-xl-3.1.safetensors [e3c47aedb0] |
| Clip skip | 2 |
| ENSD | 31337 |
| Prompt | 1girl, toki \(blue archive\), blue archive, toki sits cross-legged in her chair. looking at viewer, cowboy shot, masterpiece, best quality, newest, |
| Negative Prompt | nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, |
| VAE | Automatic |
| Sampleing method | Euler a |
| Sampleing steps | 15 |
| Width | 1024px |
| Height | 1024px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | 50 |
生成ログ
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 15/15 [00:04<00:00, 3.12it/s] | 15/15 [00:05<00:00, 2.67it/s] | 15/15 [00:05<00:00, 2.92it/s] | 15/15 [00:05<00:00, 2.78it/s] |
| 15/15 [00:04<00:00, 3.34it/s] | 15/15 [00:05<00:00, 2.92it/s] | 15/15 [00:04<00:00, 3.35it/s] | 15/15 [00:05<00:00, 2.95it/s] |
| 15/15 [00:04<00:00, 3.34it/s] | 15/15 [00:05<00:00, 2.91it/s] | 15/15 [00:04<00:00, 3.44it/s] | 15/15 [00:05<00:00, 2.96it/s] |
| 15/15 [00:04<00:00, 3.36it/s] | 15/15 [00:05<00:00, 2.95it/s] | 15/15 [00:04<00:00, 3.46it/s] | 15/15 [00:05<00:00, 2.93it/s] |
| 15/15 [00:04<00:00, 3.32it/s] | 15/15 [00:05<00:00, 2.97it/s] | 15/15 [00:04<00:00, 3.46it/s] | 15/15 [00:04<00:00, 3.01it/s] |
| 75/75 [00:33<00:00, 2.24it/s] | 75/75 [00:35<00:00, 2.08it/s] | 75/75 [00:31<00:00, 2.40it/s] | 75/75 [00:34<00:00, 2.20it/s] |
| 75/75 [00:33<00:00, 3.96it/s] | 75/75 [00:35<00:00, 3.30it/s] | 75/75 [00:31<00:00, 3.96it/s] | 75/75 [00:34<00:00, 3.32it/s] |
平均生成速度
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 3.296it/s | 2.884it/s | 3.326it/s | 2.926it/s |
生成時間
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 33秒 | 35秒 | 31秒 | 34秒 |
まとめ
この結果からは4070Tiより5070Tiの方が生成速度が遅いことが読み取れる。またCPUがCore Ultra 7 265Fの時に僅かに高速化しているが、これはPCIe4から5への変化が効いている可能性がある。
またUltra 7 265F+4070Tiの組み合わせが最速を叩き出している点も見逃せない。つまりこれはStableDiffusionにおいてはi7 13700よりUltra 7 265Fが優位であることを示しており、FF14のベンチとは結果が逆転することを意味している。
りこベンチとは個人的によく使う設定をベースにしたベンチだ。トキベンチの設定は個人的に使わず、実用性がないので今後はこちらを主にしていくと思う。
COMMANDLINE_ARGSは--xformersを使用。
ベンチマーク用のSD設定
| 設定 | 値 |
|---|---|
| Model | ntrMIXIllustriousXL_xiii.safetensors [1207404b17] |
| Clip skip | 2 |
| ENSD | 31337 |
| Propmpt | (illustration:1.0), masterpiece, best quality, 1girl, solo, happy, smile, theater, (perspective:1.3), from below, (looking away:1.2), (from side:1.0), {{shot_hair}}, smile, bangs, shaggy, (brown hair:1.1), swept_bangs, thick_eyebrows, skin_fang, closed mouth, {{purple eyes}}, gray {{jacket}}, white shirt, glasses, {{small breasts}}, |
| Negative Prompt | nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo, (loli:1.2), school satchel, pink, school bag, school uniform, from behind |
| VAE | Automatic |
| Sampleing method | DPM++ 2M |
| Hires. fix | True |
| Upscaler | Latent |
| Hires steps | 0 |
| Denoising strength | 0.8 |
| Upscale by | 2 |
| Sampleing steps | 20 |
| Width | 768px |
| Height | 768px |
| Batch count | 5 |
| Batch size | 1 |
| CFG Scale | 7 |
| Seed | -1 |
生成ログ
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 20/20 [00:05<00:00, 3.43it/s] | 20/20 [00:06<00:00, 2.94it/s] | 20/20 [00:03<00:00, 5.92it/s] | 20/20 [00:04<00:00, 4.51it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.13it/s] | 20/20 [00:11<00:00, 1.73it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.49it/s] | 20/20 [00:06<00:00, 3.06it/s] | 20/20 [00:03<00:00, 6.26it/s] | 20/20 [00:04<00:00, 4.79it/s] |
| 20/20 [00:11<00:00, 1.67it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.72it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.53it/s] | 20/20 [00:06<00:00, 3.03it/s] | 20/20 [00:03<00:00, 6.28it/s] | 20/20 [00:04<00:00, 4.81it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.36it/s] | 20/20 [00:06<00:00, 3.06it/s] | 20/20 [00:03<00:00, 6.15it/s] | 20/20 [00:04<00:00, 4.78it/s] |
| 20/20 [00:12<00:00, 1.62it/s] | 20/20 [00:17<00:00, 1.13it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 20/20 [00:05<00:00, 3.53it/s] | 20/20 [00:06<00:00, 3.08it/s] | 20/20 [00:03<00:00, 6.13it/s] | 20/20 [00:04<00:00, 4.57it/s] |
| 20/20 [00:11<00:00, 1.68it/s] | 20/20 [00:17<00:00, 1.14it/s] | 20/20 [00:11<00:00, 1.71it/s] | 20/20 [00:17<00:00, 1.13it/s] |
| 200/200 [01:49<00:00, 1.82it/s] | 200/200 [02:11<00:00, 1.53it/s] | 200/200 [01:33<00:00, 2.13it/s] | 200/200 [02:00<00:00, 1.65it/s] |
| 200/200 [01:49<00:00, 1.66it/s] | 200/200 [02:11<00:00, 1.12it/s] | 200/200 [01:33<00:00, 1.68it/s] | 200/200 [02:00<00:00, 1.11it/s] |
平均生成速度
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 2.567it/s | 2.085it/s | 3.932it/s | 2.911it/s |
生成時間
| 構成1-1 | 構成1-2 | 構成2-1 | 構成2-2 |
|---|---|---|---|
| 109秒 | 131秒 | 93秒 | 120秒 |
まとめ
結果としてはトキベンチと変わらず、Ultra 7 265F+4070Tiの組み合わせが最速でi7 13700+5070Tiの組み合わせが最も遅い。
結果しては複雑で、個人的にはどの道を選ぶか未だに悩んでいる。
まず、今回新規導入したデバイスについての評価は以下の感じだ。
Core Ultra 7 265F
RTX 5070 Ti
この結果は非常に悩ましい。FF14ベンチの結果からみるとゲーミング性能だけで言えばi7 13700+5070Tiが最適解だが、StableDiffusionの生成速度ではUltra 7 265F+4070Tiが最適解となった。
ただ私はもうFF14をしておらず、あまりゲームもしていないため、FF14ベンチの結果はある程度無視できる。そうなるとStableDiffusionだ。生成速度は重要な要素だ。とはいえ、4070Tiではメモリ不足でControlNetが使えないケースもあった。
また最近話題になっているFramePackのkisekaeichiではVRAM16GB必須という話もあり、今回は生成速度よりメモリを取る判断をしたいと思う。少なくとも旧環境である構成1-1と現環境である構成2-2を比べた時の差は一割程度であり、十分許容できる。
正直、私にはベンチマークのためにハードウェアを組み替える環境がないので、ある程度の情報でジャッジせざるを得ない。ちもろぐの人みたいに組み換え環境がある人はこの辺りがやりやすいと思うが、私の場合はPCケースからマザボを引っ張り出してそう取り返して、もう一度ケースに戻す手間がかかる。一連の作業には1時間ほど掛かり非常に手間だ。
今回はあまりにも結果が結果だったので、やむを得ず、新環境に組み替えてから、一度元に戻してベンチを取り直す検証を行ったが、組み換えの手間に加え、高価なCPUグリスが無くなり結構キツイ思いをしている。ちなみに今は新環境に完全に復帰している。

5070Tiが良さそうだったのでついでに今までDDR5にするのを渋ってたメモリをアップグレードするかぁ!と総入れ替えした結果の記録。
| デバイス | 変更前 | 変更後 |
|---|---|---|
| CPU | Intel Core i7 13700 | Intel Core Ultra 7 265F |
| GPU | GeForce RTX 4070 Ti | GeForce RTX 5070 Ti |
| MEM | Crucial Ballistix BL2K16G32C16U4B * 4 | Crucial CT2K16G56C46U5 * 4 |
| M/B | ASUS TUF GAMING Z790-PLUS D4 | ASUS TUF GAMING Z890-PLUS WIFI |
今回はなんと、これだけのパーツを神戸市内、それも中央区だけで揃えてきた。通販は箱が増えて邪魔だし日本橋に行くのは大変なので、神戸で揃えられたのは非常に良かった。


机の下から薄汚れたケースを取り出すことから始まる。いい加減掃除した方がいいかなと思った。

まずは現環境をご開帳。1~2年に一度は簡単に掃除しているのもあり、中はそこまで汚れていない。

分解を進めていくときの部品入れに、いつか役に立つだろうと取っていた揖保乃糸の箱が役に立った。

グラボをメモリを外し、コネクタをいくらか外したところ。

CPUクーラーのヒートシンクもぼちぼち埃にまみれていた。これも掃除した方がいい。

CPUグリスは意外と乾いてなかった。このCPUを付けたのは2年半ほど前で、恐らくその時からそのままである。

オンボードLAN(Intel(R) Ethernet Controller I226-V)が腐っていたので取り付けた蟹のNICともお別れだ。新しいマザボのNICは蟹なので恐らく大丈夫という期待がある。
2025年7月2日追記
よく見たらNICはIntelで、相変わらず不安定だったため、結局蟹のNICをまた挿す羽目になった。Intel NICの不安定さについては別で記事にしようと思う。

ケースのフロントUSB用の拡張ボード。これも埃が積もっている。年期が入っているため、少しさびている気もする。

ケースからマザボを抜き取ったところ。まだNVMeSSDの抜去が残っている。マザボ交換は大変だ。


空っぽになったケース。よく見ると埃が積もっているので、やはり掃除が必要だ。

というわけで徹底的に掃除を始める。この後、全ての外装をはがし、ファンも外してクイックルワイパーとエアダスターでファンのフィンの一枚一枚や、わっか部分の内側など、掃除できる場所は掃除していった。


200mmファンの清掃ビフォーアフター。

裏配線の部分は比較的奇麗だったが、ここもクイックルワイパーやエアダスターを使って掃除していく。

一見そこまで汚れてなさそうな天面ファンも掃除する。


比較するとちゃんと奇麗になっている。こういうのは細かい積み重ねが大切なので、少しの埃であれ除去してゆく。

フロントパネルもはがして掃除する。

掃除している中でケースの前方下部にフィルターがあることに初めて気が付いた。電源ファン向けのフィルターだろうか?
今まで動かすときに何も考えずにつかんでいた気がするのでやや曲がっている。

完全に裸にして徹底的に掃除する。


戻していくところ。電源(PSU)を開けるのは地味に面倒なのだ。

新しいマザボには謎のパーツがたくさんついていたが、ほとんど使わなかった。ゴムだけ使った。

新しいマザボをケースにセットしたところ。ケーブルが多すぎて入れるのが大変だった。なお、この後のベンチマークの結果がイマイチで、元のマザボに戻し、またこのマザボに戻すという非常に面倒な工程を踏むハメになる…。

最近はNVMeが主流だからかSATAの数が少なかった。昔はもっとたくさんあったし、コネクタは一箇所に集中していて、こんな分散してなかったと思う。

細かいセッティングには、このようにケースの中に張り付いてくれる懐中電灯があると便利だ。ちなみにこれはヨドバシで売っている。
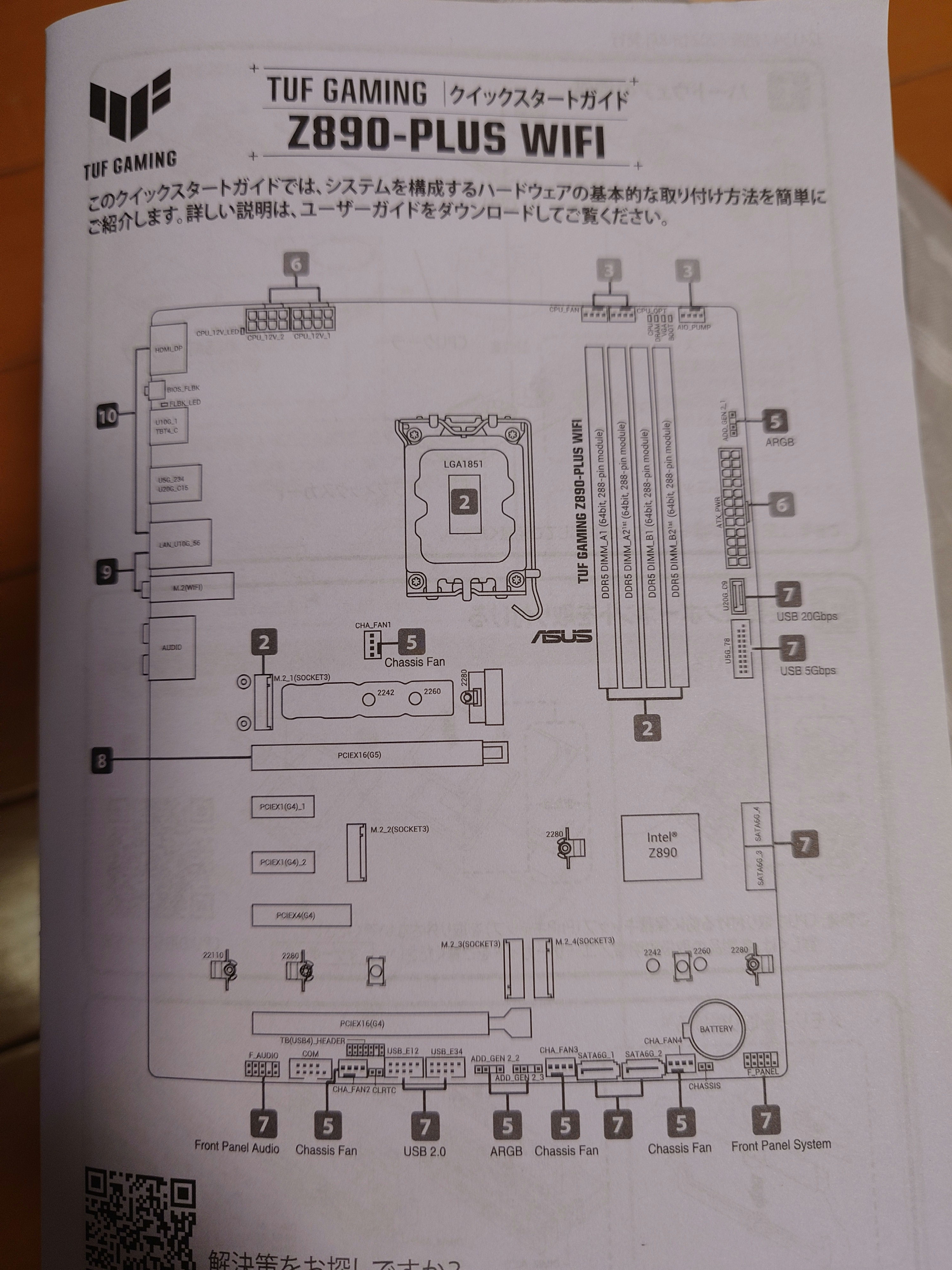
電源やリセットスイッチのケーブルを刺していて気が付いたが、このマザボにはブザーコネクタがなかった。LEDはあるものの、起動エラーを音で知れないのは少々不便である。

CPUを付けようとしたときにバックプレートが見当たらず探していたら、なんと前のマザボにセロテープでくっついていた。よく壊れなかったな…。
セロテープで固定していないと脱落してマウンタを付けづらいため、こうしていたのだと思うが、恐らくはがし忘れていたのだろう。
因みにこれはNoctuaのLGA1700用のバックプレートだが、LGA1851でもそのまま使うことができた。助かる。


マザボ現新比較。上側が今のマザボ、下が新しいマザボ。
新しい方がやや長く、薄くなっている。PCIeを複数使っている身としてはスリムになっているのは嬉しい。


PCIeスロット現新比較。左が今のマザボ、右が新しいマザボ。
今のマザボはボタンを押すとロックが外れる機構だが、ボタンが遠く、抜くとき斜めになりやすく、それが原因でロックが詰まることがしばしばあった。それに対して新しい方は位置が近いうえに、単純な作りになっており、こちらの方が抜き差ししやすいと感じた。押す場所が広く指が痛くならないのもいいところだ。

組み付け後。前よりちょっと高級感があり、チープ度が減った気がする。おそらくグラボのプラスチック感が減ったのが大きいだろう。

筐体もピカピカになっていい感じだ。しかしグラボのファンが光らなくなってしまったため回っているのか確認するのが少し煩わしくなってしまった。
BIOSからIntel Rapid Storage TechnologyをOFFにする(デフォルトはOFF)
コマンドプロンプトで起動して以下のコマンドを流す。
sfc /scannow
Ai Suite 3を消すことで解決する。
普通に消そうとしても「The model does not support this application.」とか言われるので、公式にある適当なマザボのユーティリティからAI Suite 3 Cleanerを落としてきてAi Suite 3を消す。
ZOTAC公式からドライバを落として入れる。
ROG STRIX Z370-F GAMINGのツールから落としてインスコすれば使える。
ASUS TUF GAMING Z890-PLUS WIFIだと多分この方法は無理。
ASUS TUF GAMING Z890-PLUS WIFIのツールからArmoury Crateを落とし、Armoury Crateをインストール後、Armoury Crateの機能ライブラリからアシスタントをインストールすると使えるようになる。
Armoury Crateには過去に結構苦い思い出があったので入れるのを避けたかったが、他に方法はなさそうだ。ファンの細かい調整が不要ならBIOSからやってもいいかもしれない。
ベンチスコアは複雑な結果になったので別記事、5070Tiは4070Tiより性能が悪い…?に譲る。
Automatic 1111よりいいらしいので使ってみる。
日本語表示が面倒だったので、途中から表示言語を英語に変えている。
| Env | Ver |
|---|---|
| ComfyUI | v0.3.38 |
公式サイトからインストーラーをダウンロードして実行するだけ。
Cドライブにしか対応してないらしいが、モデルや出力先は変更可能なので、インストールパスはそのままでよい。
%HOMEPATH%\AppData\Local\Programs\@comfyorgcomfyui-electron\resources\ComfyUIextra_model_paths.yaml.exampleをextra_model_paths.yamlにリネームするis_default: trueのコメントを外して有効化しておく
#comfyui:
# base_path: path/to/comfyui/
# # You can use is_default to mark that these folders should be listed first, and used as the default dirs for eg downloads
# #is_default: true
# checkpoints: models/checkpoints/
# clip: models/clip/
# clip_vision: models/clip_vision/
# configs: models/configs/
# controlnet: models/controlnet/
# diffusion_models: |
# models/diffusion_models
# models/unet
# embeddings: models/embeddings/
# loras: models/loras/
# upscale_models: models/upscale_models/
# vae: models/vae/
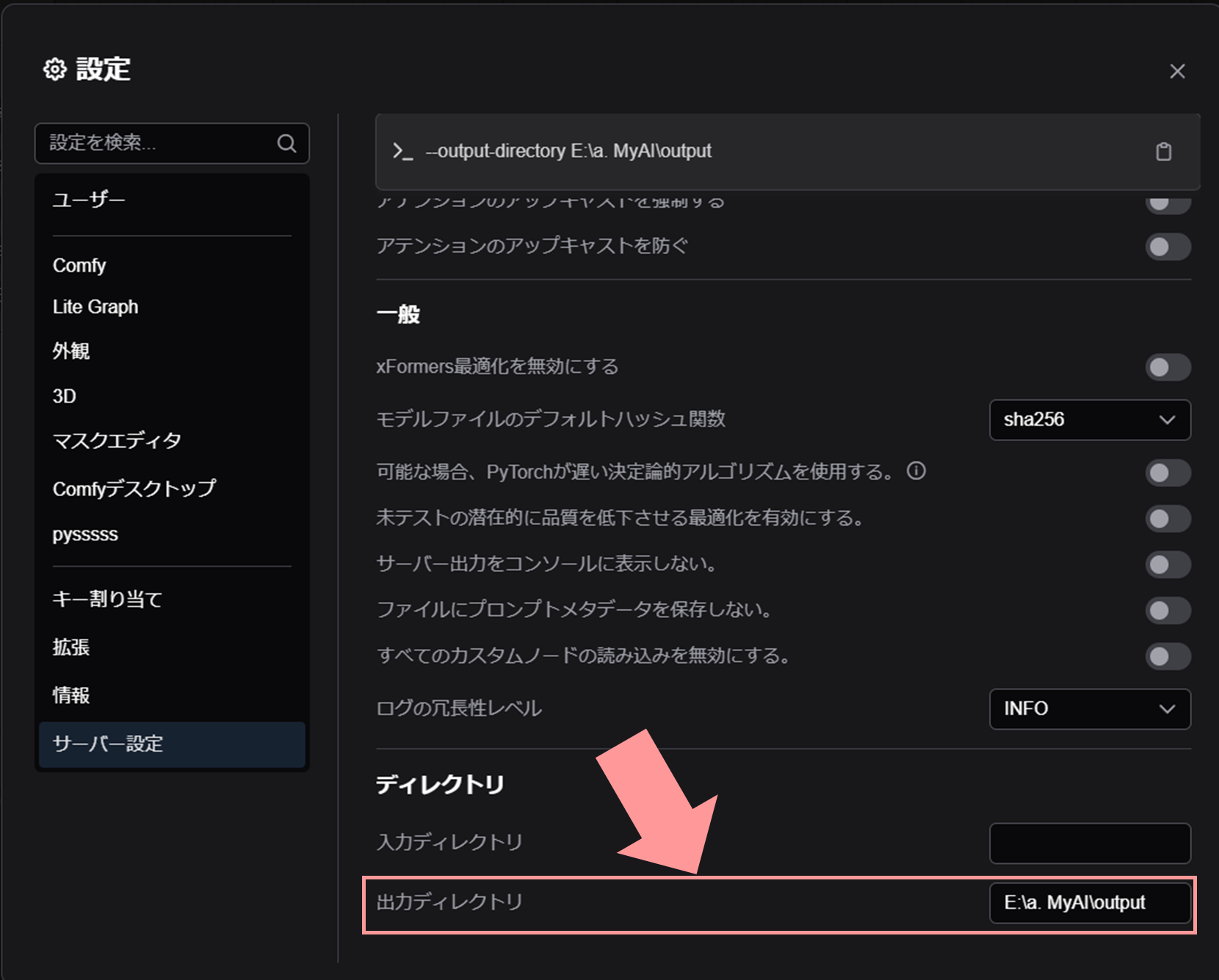
設定→サーバー設定の一番下にある「出力ディレクトリ」を設定する。
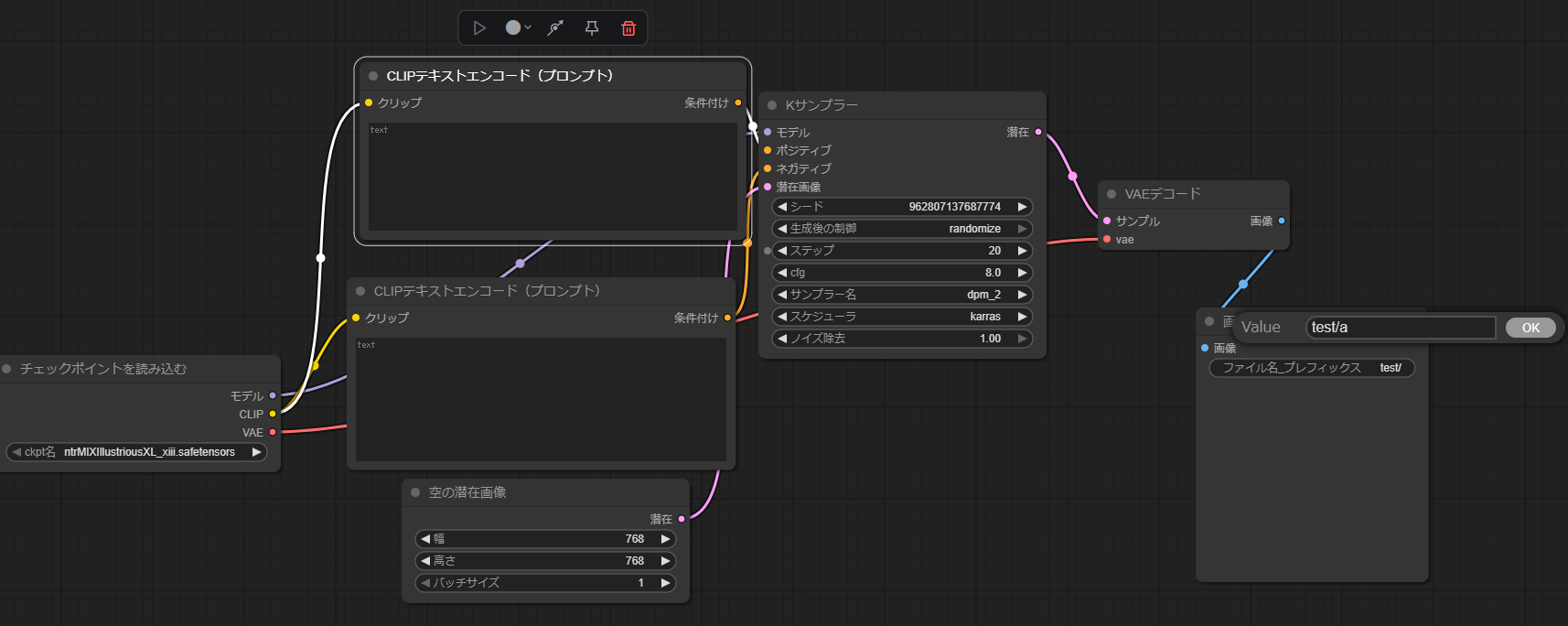
画像の保存ノードのファイル名プレフィックスをクリックし、Valueにフォルダ名/任意の文字列をつけることでフォルダわけもできる。フォルダ名/だけ指定してもうまくいかないので注意。
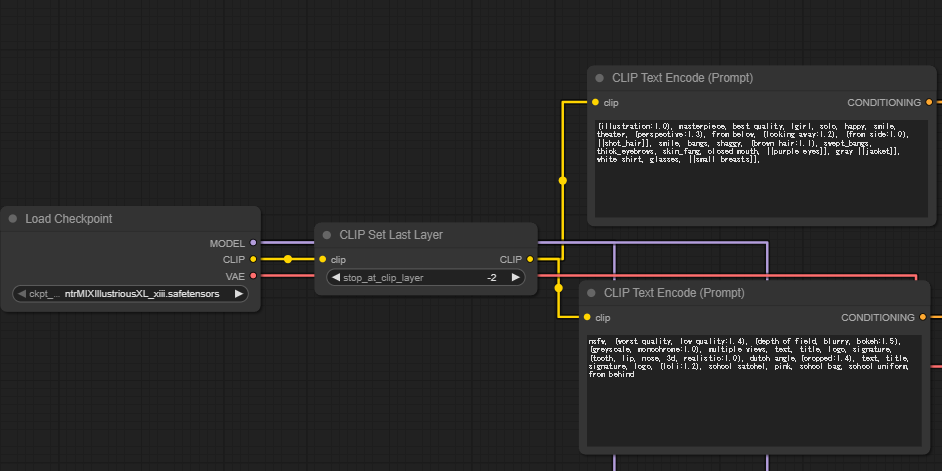
CLIP Set Last LayerノードをLoad Checkpointに接続することで実現できるらしい?
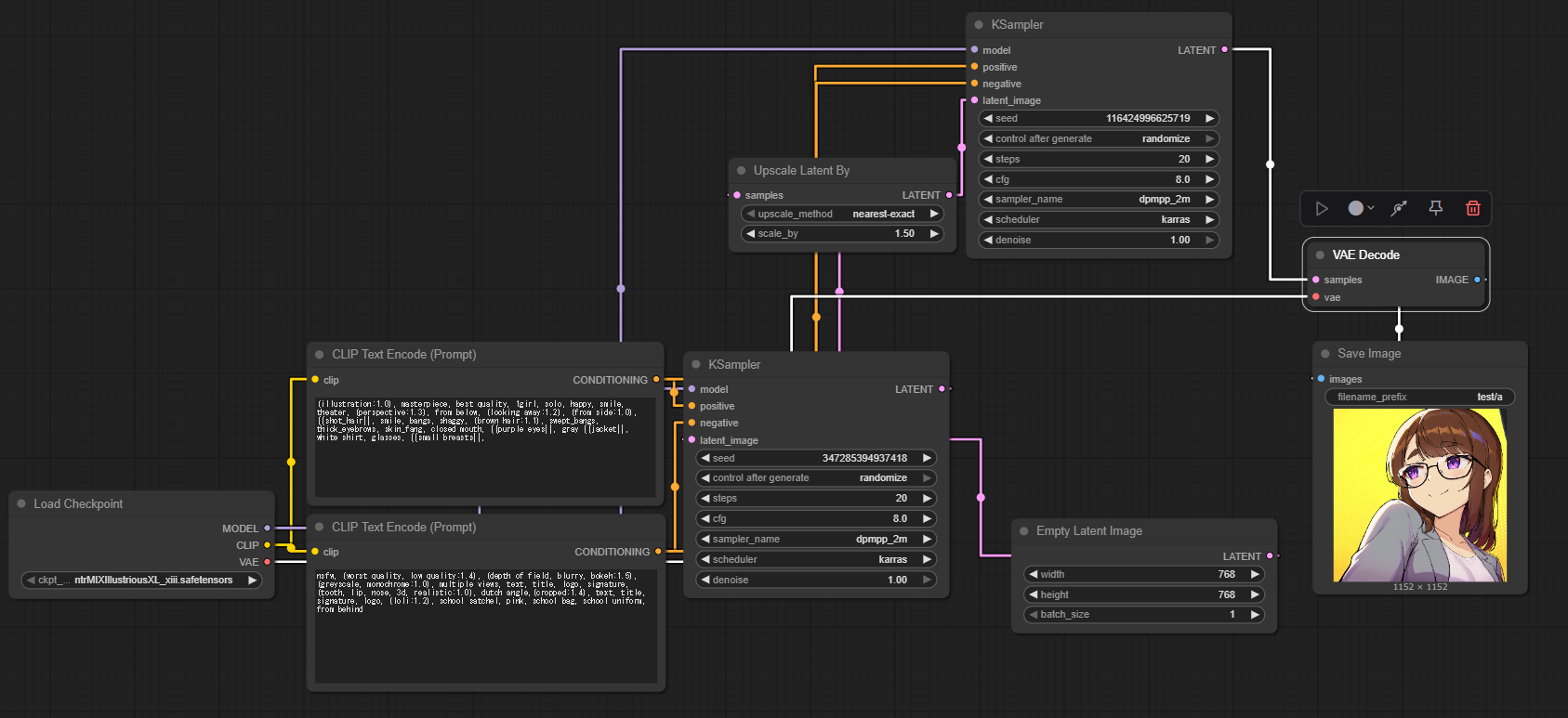
KSampler→Upscale Latent By→KSampler→VAEで繋ぐと同様のことができるらしい。
1111は1分近くかかるがComfyは数秒で起動するため、ここはいいと思った。
1111では基本的に生成種別、日付別に保存されるため整理が手間である。


これはComfy UIを以下の構成にして生成したものだ。
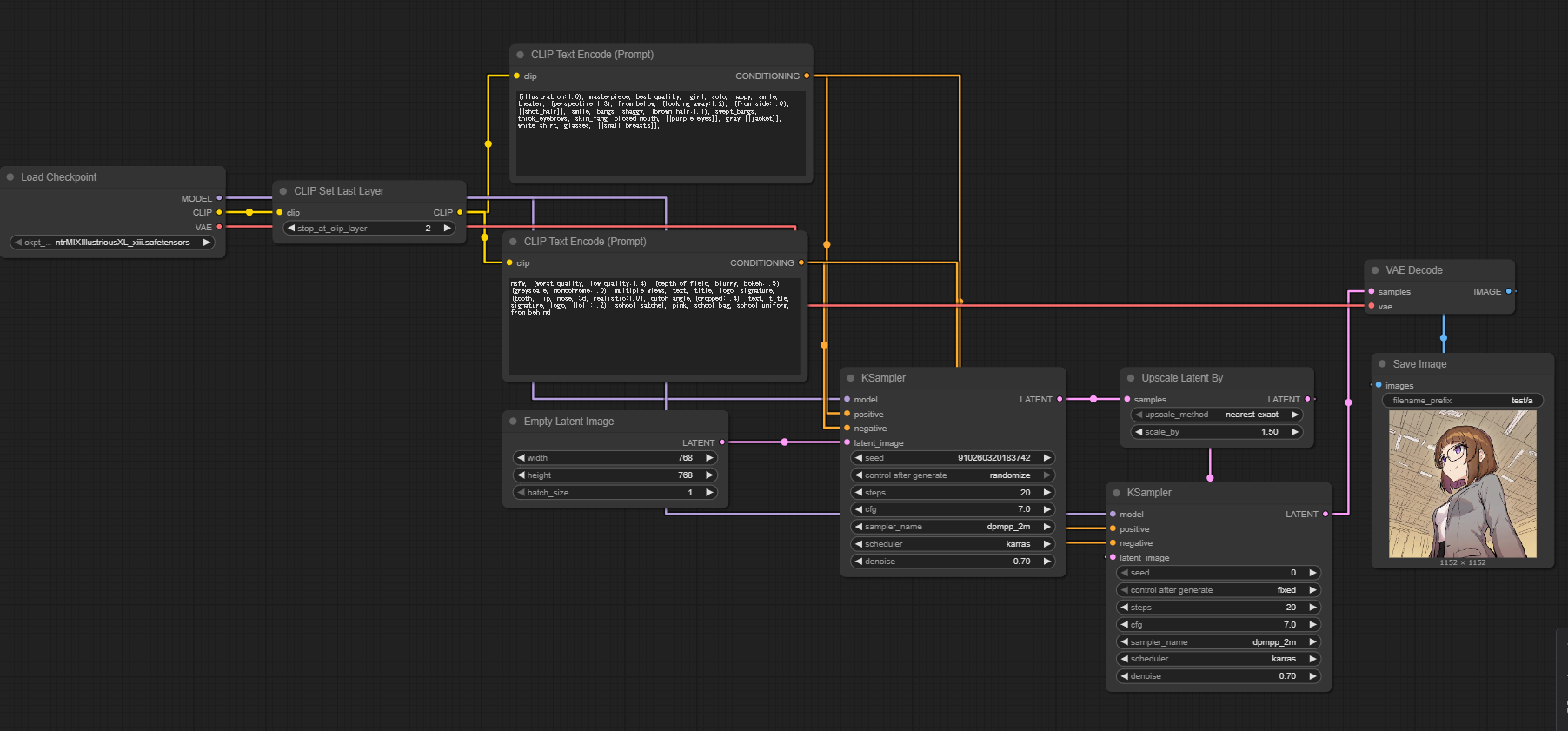
一枚目はこういう絵柄だといえばまだありかもしれないが、二枚目は微妙だ。これはどうもHires.fix相当の機能が期待通りに動いていないのが理由に見えるが、恐らくそういった事柄を探求するモチベーションがないと、上手いこと使えないと思われる。
また上記のノード接続だと生成速度も速いとは言えず、これ以上要素を増やすとなると実用性は怪しいと感じた。

1111だとこのくらいのものがパッと出てくるため、個人的には今のところ1111でいいかなと思った。カリカリにチューニングすることで1111を超えてくる可能性は否定できないが、大抵のケースで設定値は固定であり、プログラマブルである必要性はアニメーションとかの分野になってくると思われるので、動画を作るならComfy、そうでなければ1111で十分な気がした。
H200やH100は手が届く値段とは言い難いし、L40Sもなかなか厳しい…。そんな中、先日NVIDIAからDGX Sparkなる128GBものVRAMを積んだマシンが比較的安価で出るという噂を聞いたので軽く調べてみた。
想定販売価格は$2,999で、これまで出てきたワークステーション向けより安価だ。過去にあったJetsonの強化版的なものだろうか?
今持っている4070Tiと性能を比較してみたところ申し分ないグレードアップに見える。スタンドアローンマシンとのことなので、StableDiffusionを常時起動できたり何かと便利そうでもあるため、価格次第では買ってもいいかもしれない。二台繋げて動かすこともできるようだが、さすがにそこまではしない。
OSもUbuntuが動くとのことで、恐らく一般的なARM PCに仕上がってそうだ。ストレージも4TBあるそうなので、画像生成用途なら一台ですべて完結できそうである。個人的にはLLMを乗せるとどうなるのかが気になるところだが、特に調べていない。もし、CloudeレベルのLLMが動かせれば非常に魅力的だと思う。
| 性能 | DGX Spark | GeForce RTX 4070 Ti |
|---|---|---|
| CUDAコア数 | ? | 7,680 |
| Tensorコア | 第5世代 1,000 AI TOPS | 第4世代 641 AI TOPS |
| GDDR | 128GB LPDDR5x | 12GB GDDR6X |
| メモリインターフェース | 256-bit | 192-bit |
| メモリ帯域 | 34Gbps | 21Gbps |
| 電源 | 170W | 700W |
DGX Sparkのメモリ帯域は273GB/sとあったのでbit換算するために8で割っている。
メモリがLPDDRなのが気になるが、恐らくここが安価にできているポイントのような気がする。
ゲーミング向けグラボのGDDRは容量が抑えられがちなので、恐らく高いのだろう。しかしメモリ容量の割にバス幅が狭いのでここはボトルネックになりそうだ。とはいえ、StableDiffusionを使うケースでは現状より性能アップなので不満を覚えることはないと思う。