- 投稿日:
Groovy Scriptの読み方が分からなかったので読み解き方のメモ。全て憶測
確認環境
| Env | Ver |
|---|---|
| Jenkins | 2.249.1 |
| Groovy Script | 不明 |
サンプルコード
def credentials = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
org.jenkinsci.plugins.plaincredentials.StringCredentials.class,
jenkins.model.Jenkins.instance.getItemByFullName("ここにフォルダパス")
)
def cred = credentials.findResult { it.id == "ここに取得したいやつのCredentials ID" ? it : null }
読み解き方
個人的な解釈なので特に根拠はない。全て憶測。
lookupCredentialsの部分
端的に言うとデータ型とストア名のようなものを指定し、認証情報を取得する機能であると思われる。Groovy Script的にはCollectionが返ってくる。
- com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials())
- 第一引数にデータ型、第二引数にLOOKUP条件を設定するものと思われる
- org.jenkinsci.plugins.plaincredentials.StringCredentials.class
- 文字列の認証情報ということだと思われる
- jenkins.model.Jenkins.instance.getItemByFullName())
- 現在のJenkinsインスタンス(Jenkinsシステムそのもの)から名前で要素を取得するものだと思われる
findResultの部分
- http://docs.groovy-lang.org/docs/groovy-2.1.3/html/groovy-jdk/java/util/Collection.html#findResult(groovy.lang.Closure)
- 恐らくJSのArray.findと似たような機能で、
itの中に配列要素が入ってくるので、それを使って配列内容の要素を取り出すのに使うのだと思う
- 恐らくJSのArray.findと似たような機能で、
- 投稿日:
HuskyとはNode.jsを利用した開発で非常によく使われているGit hooksのユーティリティだが、個人的にはこのツールの存在価値に疑問を感じている。
という訳で、この記事ではHuskyのメリデメを考えた結果と、Huskyが何をしているか、Huskyの必要性について書いてゆく。
Huskyがあるメリット
Huskyは極めて有名なツールであるため、Huskyが入っているとこのプロジェクトはGit hooksで管理されており、標準化されていることが確認できるだろう。恐らくHuskyのメリットはこれ以外に存在しないと考えている。
Huskyがあるデメリット
Huskyの管理をしないといけない、Huskyも地味にアップデートするからだ。これは明確なコストである。
そしてHuskyのコードやリポジトリを見たことがある人は多分ほとんどいないと思う。更に言えばHuskyが何をしているかすらも知らない人だっているはずだ。そんな得体の知れないものを使うのは怖いというところだ。
Huskyは何をしているか?
端的に言えばGit hooksのパスを .husky/ に設定しているだけである。
要するに git config core.hooksPath .husky を叩いているだけだ。
もう少し細かく言えば以下に相当する処理を実行している。
mkdir -p .husky/_
cp husky.sh .husky/_
git config core.hooksPath .husky
勿論、ソースコードには他の処理も書かれているのだが、実質的には上記三行が全てと言って良い。
husky.sh を活用しているケースがどれほどあるか怪しいことを考えると、本質は git config core.hooksPath .husky だと思うので、正直あるだけ邪魔では?と考えている。
Huskyの必要性
ここまででHuskyがしていることは git config core.hooksPath .husky だということが解ったが、だとしたらHuskyは本当に必要なのだろうか?私は特に理由がないのであれば package.json で husky install と書いてあるところに git config core.hooksPath .githooks とでも書いておけば良いのではないか?と思っている。恐らく何も不都合はないはずだ。
ただ世の中には色々な事情があり、使わざるを得ないケースもあると思う。しかし、可能であれば排除してもいいのではないか?個人的にはそう思っている。
何故この記事を書いたか
「この世からHuskyを滅ぼすため」というのはまぁ冗談だが、個人的にHuskyの存在価値があまり良くわかっておらず、多分世間の人もあまり理解できていないと勝手に考えていて、可能であればプロジェクトに入れたくないと考えているので、そのお気持ち表明というか、そんな感じだ。
ここからは余談だが、Huskyには結構な数のスポンサーが付いていて、恐らく毎月それなりの収入があると思われる。以下はHuskyのスポンサーである。
個人的にHuskyは最も成功したOSSの一つではないかと考えている。理由としてHusky自体は非常に単純なプロダクトであり、コミット履歴を見てもさしたるメンテナンスがされておらず、ほぼ手放しで維持されていると思われるからだ。
しかし、Huskyはそれなりの額の寄付を集めており、この記事を書いた時点で確認できるだけでも最低 10USD * (4 + 16) + 100USD * (4 + 2) の寄付がされており、つまり800USD、日本円にして11.2万円ほどだ。何もしてないのに毎月この収入があるのは大分ありがたいだろう。他のOSSならIssueやPull Requestsに対して対応したり、コード本体のメンテナンスがあるはずだが、Huskyにそんなものはないため、プロダクトの維持コストに対して非常によく寄付を集められていると感じる。
- 投稿日:
これは、かつて参画したGitHubを利用したプロジェクトでブランチフローが悪く事故が多発したので考案し、運用した内容です。
基本的には後々の運用を考えた時に情報源になり、かつGit操作に極力手間を取られることがなく、CI/CDを回しながら品質を維持できる内容で考えています。
フローの要件として考えたこと
取り回しが単純明快であること
開発以外の要素に振り回されないように単純なフローにしていて、世に言われる履歴の綺麗さとか言うのは個人的には関心が薄いので重視していません。その代わりコミットが壊れないことや、インデックスとして見やすくなるような部分を重視しています。
GitHubとの相性が良いこと
まず個々の開発タスクをIssueベースで管理し、Pull Requestベースで取り込む運用としました。
Pull Requestの取り込み方式はSquash Mergeとし、メインブランチのコミット履歴がPull Requestのマージコミットになるようにしました。
これはメインブランチのコミット履歴はPull Requestのマージコミットだけあれば後から追えるというのと、メインブランチのコミットログを単純にする意味でこの方式にしています。
CI/CDを活用しやすいこと
これは割とどこでもやっていると思いますが、ブランチ名にdevelopとかstaging, productionとか付けて管理することで、自動的に環境を識別できるようにしました。
実際に運用したフロー
フロー図
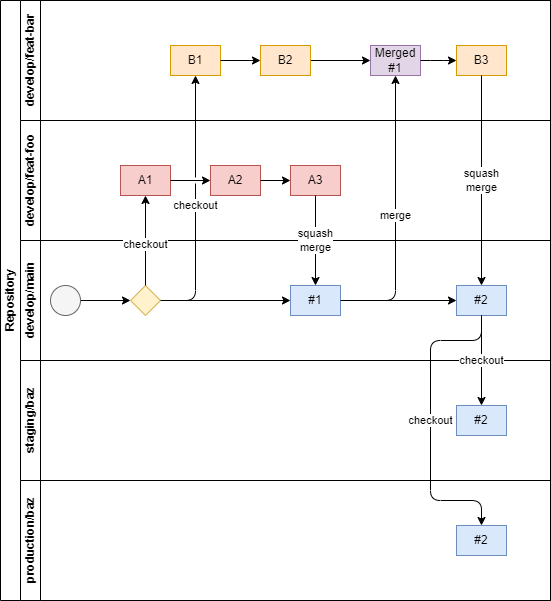
フローの運用内容
develop/mainブランチを最新ブランチとする運用develop/mainブランチ相当のものが複数ある状態というのが世の中にあると思いますが、管理が非常に大変なのでそれはしない方向にしました
- 機能ブランチを
develop/mainブランチに取り込むのはSquash Merge- 基本的に変更履歴を見る時はGitLensや
blameで変更行からPull Requestを当てて、そこを見に行くという運用にしていました
- 基本的に変更履歴を見る時はGitLensや
- 機能ブランチに
develop/mainブランチを取り込むのはmerge- 一般的には
rebaseが多いと思いますが、次の観点から採用しませんでした- どのポイントで取り込んだのかわからない
mergeと比較した場合にコンフリクト対応に手を取られる- 経験上ここで事故が頻発する
- 素直に
push出来ない
mergeであれば以下のように単純な流れに出来ますし、push前に差分確認して事故を防ぐことも容易ですgit switch develop/maingit pullgit switch -git merge -- コンフリクトがあれば解消
git push
- 一般的には
- デプロイ方式によるルートブランチ分割
- ルートブランチ名によってデプロイ先を変更できるようにしました
- GitHub Actionsでブランチ名を拾って環境変数を差し替えることでデプロイするワークフローを組んでいます
staging/やproduction/ブランチはdevelop/mainからcheckoutする運用です- これらはデプロイするためだけの使い捨てブランチなので毎回生えます
あとがき
このフローの利点としてはマージでコンフリクトが起きても基本的にCurrentとIncomingを一回比較するだけで済むのでコンフリクトの解消が簡単で、コンフリクト時はIncomingが壊れないようにCurrentを直すのが基本になり、Currentを優先する場合は適宜上書きするといった内容です。
ブランチの合流はmergeだとマージコミット分一回の解消だけでいいので事故の発生要因が低いのがrebaseと比較した時の利点です。rebaseだとコミット回数分再帰的に合流させる必要があるのでブランチの寿命が長かったりすると苦行になってきます。
このフローができた経緯としては元々はGitHub Flowをベースにしていたのですが、色々やっていくうちにこうしたらもっと良くなるのではないか?というのを試行錯誤していてこの形に落ち着いたのですが、後から調べたらGitLab Flowに近い形式に見えたので、似た内容は既に誰かが考えているものだなと感じました。
上で挙げた内容の他にもGitHubのリポジトリ設定でブランチ保護のルールを設定したり、Pull Requestのマージ設定でSquash mergingだけ許可したり、ヘッドブランチの自動削除をするなど、基本的に面倒なことを考えたり、しなくて良い様にするなど、開発に注力しやすいように環境を整えると心理的な抵抗が少なく運用できて便利だなと感じています。
- 投稿日:
runコマンドでサービスを指定してコマンドを蹴ると実行結果が取れる- e.g.
docker-compose run node-git 'npm' 't'
- e.g.
- コマンドを複数繋げる場合はシェルを呼び出してやる
- e.g.
docker-compose run node-git 'sh' '-c' '"ls -la && grep foo"'
- e.g.